DexNDM: Closing the Reality Gap for Dexterous In-Hand Rotation via Joint-Wise Neural Dynamics Model
Abstract: Achieving generalized in-hand object rotation remains a significant challenge in robotics, largely due to the difficulty of transferring policies from simulation to the real world. The complex, contact-rich dynamics of dexterous manipulation create a "reality gap" that has limited prior work to constrained scenarios involving simple geometries, limited object sizes and aspect ratios, constrained wrist poses, or customized hands. We address this sim-to-real challenge with a novel framework that enables a single policy, trained in simulation, to generalize to a wide variety of objects and conditions in the real world. The core of our method is a joint-wise dynamics model that learns to bridge the reality gap by effectively fitting limited amount of real-world collected data and then adapting the sim policy's actions accordingly. The model is highly data-efficient and generalizable across different whole-hand interaction distributions by factorizing dynamics across joints, compressing system-wide influences into low-dimensional variables, and learning each joint's evolution from its own dynamic profile, implicitly capturing these net effects. We pair this with a fully autonomous data collection strategy that gathers diverse, real-world interaction data with minimal human intervention. Our complete pipeline demonstrates unprecedented generality: a single policy successfully rotates challenging objects with complex shapes (e.g., animals), high aspect ratios (up to 5.33), and small sizes, all while handling diverse wrist orientations and rotation axes. Comprehensive real-world evaluations and a teleoperation application for complex tasks validate the effectiveness and robustness of our approach. Website: https://meowuu7.github.io/DexNDM/







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces DexNDM, a way to teach a robot hand to spin and turn lots of different objects in the air. The big challenge is that robots usually learn in a simulator (a “video game” version of the world), but the real world is messier. DexNDM helps close this “reality gap” so a single policy learned in simulation can work well on real robots for many object shapes, sizes, and wrist positions.
Key Questions and Goals
The authors set out to:
- Create one general policy that can rotate many different objects—small, long, and oddly shaped—under many wrist directions and rotation axes, in the real world.
- Bridge the gap between simulation and reality using only a small amount of real data (no fancy sensors or constant human resets).
- Make real-world data collection safe, cheap, and automatic.
- Test whether a “joint-wise” model (each finger joint learns its own motion) is better than modeling the whole hand at once.
- Show the policy is useful, for example in teleoperation (controlling the hand to use tools and do assembly).
How They Did It (Methods Explained Simply)
Think of teaching a robot hand like training an athlete:
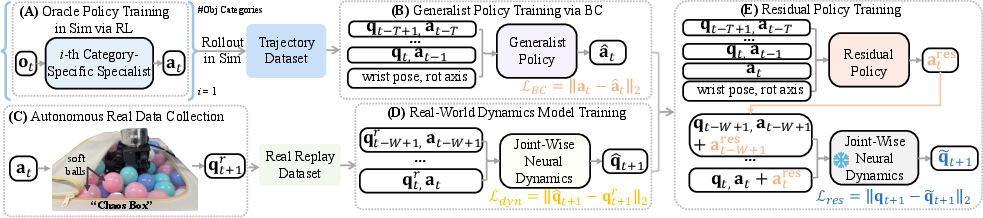
- Train specialists, then create a generalist:
- In simulation, they trained expert policies for different object categories (like “long sticks” or “animal-shaped toys”) using reinforcement learning, where the robot gets rewarded when it rotates the object correctly and penalized when it moves the object the wrong way.
- Then they used behavior cloning (imitation learning) to distill these experts into one generalist policy that can handle many objects.
- Collect real-world data safely and automatically:
- Instead of asking the robot to rotate hard objects and risk dropping them, they built a “Chaos Box”: a container filled with soft balls.
- They replayed actions from the simulated policy while the hand interacted with these balls. The balls push and pull in random ways, creating lots of safe, diverse “loads” on the hand—like training in a ball pit. This gives useful real-world experience without breaking things or needing a person to reset the scene.
- Learn a joint-wise neural dynamics model (the “secret sauce”):
- “Dynamics” means how things move when you apply forces. The big idea: don’t try to learn the entire hand+object system all at once. Instead, let each joint (like each knuckle) learn to predict its own next position from its own recent history.
- Analogy: it’s easier to listen to each musician’s part than to decode the whole orchestra at once. Each joint model learns the “net effect” of everything (other joints, the object pushing back, the motors) in a simple way, without needing to track the object precisely.
- This simpler view makes learning faster and more reliable from limited real data.
- Add a residual policy to fix small mismatches:
- A “residual” is a small correction. Using the learned joint-wise dynamics model, they trained a residual policy that adds tiny adjustments to the action suggested by the simulation policy, so the real hand behaves more like the simulator predicted.
- Analogy: if your map is slightly off, a small steering correction keeps you on the right road.
Main Findings and Why They Matter
What they showed:
- Strong generalization in simulation: The generalist policy worked on new objects it hadn’t seen and rotated along different axes and wrist directions, outperforming a strong baseline by a large margin.
- Big real-world success:
- Rotated many challenging objects in the air, including:
- Complex shapes (like animal models).
- Long objects (aspect ratios up to 5.33).
- Small objects (as small as ~3 cm).
- Handled tough wrist orientations, including palm-down, base-up/down, and thumb-up/down.
- Rotated long objects around their long axis in the air—something earlier methods struggled with.
- Better than prior methods:
- Outperformed AnyRotate on replicable test objects.
- Achieved comparable or better performance than Visual Dexterity, even though their metric was favorable to Visual Dexterity’s setup.
- Joint-wise model beats whole-hand model when data is limited:
- More sample-efficient: learns well from fewer real-world examples.
- More robust: generalizes better when training and test situations differ.
- Practical application:
- Built a teleoperation system where a person can control the hand to do complex tasks, like using a screwdriver or knife, and assembling parts.
Why it’s important:
- It shows a path to making robot hands truly dexterous in real life without relying on expensive, specialized hardware or perfect object tracking.
- It reduces the need for constant human intervention during training.
- It works across many conditions, making robots more useful in everyday or industrial settings.
Implications and Future Impact
DexNDM suggests a new way to bridge simulation and reality for complex manipulation tasks:
- Model each joint separately to learn faster and generalize better from limited, imperfect data.
- Collect cheap, safe, and automated real-world data with randomized loads instead of risky task-specific trials.
- Use small corrective policies (residuals) to align real behavior with simulated plans.
This approach could help:
- Home robots handle diverse objects and orientations (picking up toys, opening containers, using tools).
- Factory or lab robots manipulate tricky parts without costly sensors or constant resets.
- Future research on other dexterous skills, like re-grasping, tool-use, and delicate assembly.
In short, DexNDM makes it more realistic to train a robot hand in a simulator and then have it spin, turn, and manage many real objects reliably—bringing dexterous manipulation a big step closer to everyday use.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper. These are framed to guide future research and experimentation.
- Hardware generalization: The approach is only validated on the LEAP hand; it remains unclear how the joint-wise dynamics model and residual policy transfer to other dexterous hands (e.g., Allegro, Shadow, customized hands), different fingertip materials, actuator characteristics, and kinematic configurations.
- Object diversity and material properties: Real-world tests do not systematically vary surface friction, texture, compliance, or mass distribution (e.g., soft/deformable, highly glossy, sticky, or very heavy objects); how robust the model/policy is to these factors is unknown.
- Axis fidelity in the real world: The paper avoids real-time object state estimation; as a result, it does not quantify how accurately rotations follow a specified axis on hardware (beyond “radians rotated” and time-to-fall). Methods to measure axis alignment without reliable vision/tactile sensing are missing.
- Sustained multi-revolution rotation: While “about one full circle” is reported, the stability and consistency of multi-turn rotations (multiple revolutions) across axes and wrist orientations are not evaluated or characterized.
- Closed-loop sensing limitations: The generalist policy observation excludes object state; how to incorporate robust tactile or vision (under severe occlusions) to achieve axis-accurate, goal-conditioned rotation in the real world remains unaddressed.
- Residual policy training target: The residual is trained to align real joint transitions (via learned dynamics) with simulated next states using simulated trajectories; whether optimizing residual directly for task reward (e.g., RL finetuning) yields better transfer, stability, or robustness is not examined.
- Stability and safety guarantees: There is no control-theoretic analysis (e.g., passivity, Lyapunov stability) of the closed-loop system with a learned joint-wise dynamics model and residual actions; conditions for safe deployment and failure modes are not characterized.
- Theoretical assumptions and validity: The generalization analysis relies on covariate shift () and a strict DPI claim; whether these assumptions hold under contact-rich, discontinuous manipulation dynamics (stick–slip, impacts) is not empirically validated or theoretically relaxed.
- Expressivity limits of joint-wise factorization: Predicting each joint from its own history may miss long-range inter-joint couplings in tasks requiring tightly coordinated motions; conditions under which this factorization breaks (e.g., nonlocal coupling, stiff contacts) are not identified.
- Model architecture and hyperparameter sensitivity: The paper does not systematically study sensitivity to history length (W), network depth/width, feature normalization, and PD gains; guidelines for selecting these hyperparameters across tasks and hardware are lacking.
- Dynamics model constraints: The joint-wise model does not encode physical constraints (e.g., torque limits, energy, contact complementarity); whether adding structure (latent variables, physics-informed layers, or graph couplings) improves robustness and OOD generalization is an open question.
- “Chaos Box” data collection design: The choice of ball properties, quantity, stiffness, action replay noise magnitude, and container geometry is ad hoc; there is no ablation on how these choices affect data coverage, safety, and downstream performance.
- Distributional relevance quantification: While Figure 1 suggests joint I/O histories are task-relevant, a quantitative multi-joint analysis (e.g., KL divergences across wrist poses and object categories) of Chaos Box vs. task distributions is absent.
- Scaling autonomous data beyond rotation: It is unclear how to generalize the autonomous data collection strategy to other dexterous skills (e.g., regrasping, unscrewing caps, knob turning, tool use requiring specific force/torque profiles) without human resets.
- Online adaptation: The residual policy is static post-training; there is no investigation into online adaptation (meta-learning, system ID on-the-fly) to handle object-specific dynamics, fingertip wear, or environmental shifts.
- Integration with System ID and Domain Randomization: The paper does not explore whether combining joint-wise NDM with structured SysID or better-informed DR improves transfer relative to either alone.
- Evaluation breadth and rigor: Real-world metrics focus on radians rotated and time-to-fall; missing are success rates under axis targets, repeatability, variance across trials, and failure characterization by object type and wrist pose.
- Benchmarking comparability: Comparisons to AnyRotate and Visual Dexterity rely on re-implementation or video-based estimates, with different hardware and task definitions; a standardized, reproducible benchmark and common metrics are needed to draw rigorous conclusions.
- Object tracking under occlusion: The work defers object orientation estimation due to occlusions; exploring occlusion-robust tracking (e.g., fusion of vision, magnetic IMUs, tactile pose estimation) is left open.
- Transfer to dynamic arm motions: The system is evaluated for in-air rotation with a fixed wrist pose; how it performs under simultaneous arm motions, external disturbances, or environmental contacts is not tested.
- Robustness to sensing and actuation noise: The impact of encoder noise, latency, actuator saturation, and thermal drift on the learned dynamics and residual controller is not quantified.
- Teleoperation evaluation: The teleoperation demonstrations are qualitative; task success rates, speed, error, and user-study results (e.g., workload, intuitiveness) are missing.
- Data and code release completeness: It is unclear whether the full real-world dataset (Chaos Box trajectories), trained models, and evaluation protocols will be released to enable replication and ablation by the community.
- Sim-to-sim robustness: The truncated sim-to-sim comparison suggests cross-simulator sensitivity; a complete study across multiple physics engines (Isaac Gym, MuJoCo, Genesis, Bullet) with consistent settings is needed.
- Limits of generality: The reported max aspect ratio (≈5.33) and small size (2–3 cm) are impressive, but extreme cases (ultra-slender, very small or very large objects) and deformables remain unexplored.
- Contact regime coverage: There is no analysis of how well the model handles diverse contact regimes (static friction, stick–slip transitions, rolling vs. sliding, multi-point contacts) and whether additional sensing or modeling is required.
- Policy specialization vs. generalization trade-offs: The specialist-to-generalist pipeline works, but the conditions under which category experts or a single generalist are preferable (e.g., per-object performance, training cost) are not reported.
- Long-term durability and wear: The effect of fingertip wear, surface contamination, and environmental changes over days/weeks on performance and the learned dynamics is not studied.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the paper’s findings and pipeline today, along with sectors, potential tools/workflows, and key dependencies.
- Dexterous reorientation in manufacturing and warehousing (robotics, industrial automation)
- Use cases: inline part reorientation; rotating elongated or small parts to align with fixtures; barcode/label exposure by rotating packaged goods; bin-picking followed by in-hand reorientation.
- Tools/workflows: deploy the trained “generalist rotation policy” on commercial dexterous hands (e.g., LEAP, Allegro) as a gripper firmware add‑on; integrate the residual policy for site-specific sim‑to‑real adaptation; add a “Chaos Box” station for low-touch fleet-wide data collection/refresh.
- Assumptions/dependencies: availability of a multi-finger hand with reliable proprioception and PD control; modest compute for policy inference; safety interlocks for rotating items near people; basic integration with existing robot arms.
- Operator-assist teleoperation for fine tasks (software, robotics, education)
- Use cases: VR teleoperation with policy assistance for tool use (e.g., screwdriver, knife handling), small assembly tasks (e.g., furniture kits, lab fixtures), and delicate repositioning.
- Tools/workflows: pair the policy with a VR interface; add “policy-preview” or “autonomous micro-actions” that execute robust in-hand rotations while the operator handles gross motion; record sessions to bootstrap further data collection.
- Assumptions/dependencies: consumer-grade VR hardware; teleop middleware; latency under typical network conditions; safety training for tool manipulation.
- Post-pick reorientation in service robotics (consumer, hospitality, retail)
- Use cases: rotating bottles, cups, utensils, or toy parts for presentation/placement; exposing caps/lids for opening; aligning items for scanning in retail kiosks.
- Tools/workflows: incorporate the rotation policy into a mobile service robot; scripted task flows using “rotate to axis” primitives; periodic on-site “Chaos Box” data refresh to adapt to local item sets.
- Assumptions/dependencies: item geometry within demonstrated ranges (small objects ~2–3 cm, aspect ratios up to ~5.3); reliable grasping upstream; clear safety boundaries in public spaces.
- Lab automation for sample handling (academia, biotech)
- Use cases: in-hand rotation of small vials, tubes, and custom 3D-printed containers to align labels or lids; gentle alignment for imaging or pipetting stations.
- Tools/workflows: plug-in “rotation primitive” for lab robots; autonomous data collection using soft-loads (Chaos Box) with dummy labware; scripted sequences integrating the generalist policy.
- Assumptions/dependencies: cleanroom/contamination controls; force/torque limits for delicate items; compliance with lab safety protocols.
- Sim‑to‑real toolkit for contact-rich manipulation research (academia, software)
- Use cases: accelerate transfer of manipulation policies without object-state tracking; minimize human resets in real-data collection for student projects and lab prototypes.
- Tools/workflows: open-source implementation of the joint-wise neural dynamics model; standardized “Chaos Box” protocol; reference pipelines for specialist-to-generalist training via RL + BC; evaluation metrics (TTF, RotR/RotP, survival angle).
- Assumptions/dependencies: access to simulation (Isaac Gym/MuJoCo) and a dexterous hand; modest GPU/CPU for training; adoption of shared datasets and protocols.
- Quality control and inspection (industrial, electronics)
- Use cases: rotate small components to expose serial numbers/inspection surfaces; align complex-shaped parts for imaging.
- Tools/workflows: integrate the rotation primitive into vision-guided inspection cells; use residual policy learning to adapt to component-specific friction/texture.
- Assumptions/dependencies: camera placement and lighting; safe handling limits; synchronization with inspection software.
- Education and training modules in robotics programs (education)
- Use cases: classroom projects around sim‑to‑real; curriculum modules on joint-wise dynamics and information contraction; student labs using Chaos Box data collection.
- Tools/workflows: teaching kits combining a low-cost dexterous hand, simulation exercises, and pre-trained models; assignments comparing whole-hand vs. joint-wise modeling.
- Assumptions/dependencies: availability of affordable hardware; institutional support for hands‑on labs.
- Robotics startup prototyping (entrepreneurship, software)
- Use cases: rapid validation of dexterous capabilities in investor demos or pilot deployments; productizing a “rotation-as-a-service” microservice.
- Tools/workflows: cloud-based training for the residual policy; containerized deployment on edge devices; plug-in APIs for “rotate to axis” commands.
- Assumptions/dependencies: DevOps readiness; cost control for compute; device drivers for the target hand.
- Sustainable packaging and recycling streams (policy, industry)
- Use cases: rotate irregular recyclables to read material codes; reorient small items for automated sorting in MRFs (materials recovery facilities).
- Tools/workflows: add rotation primitives to existing sorting lines; policy refresh via Chaos Box with representative waste loads.
- Assumptions/dependencies: robust grippers for dirty/irregular objects; occupational safety approvals; throughput targets.
- Safety and standardization pilots (policy)
- Use cases: define practical safety envelopes for in-hand rotation near humans; seed standards for sim‑to‑real data collection without human resets.
- Tools/workflows: test protocols using Chaos Box to validate generalization claims; draft technical guidance for dexterous manipulation metrics and reporting.
- Assumptions/dependencies: regulatory collaboration (e.g., ISO/ANSI); cross-lab reproducibility; incident reporting procedures.
Long-Term Applications
These use cases will likely require additional research, scaling, regulatory approval, or hardware iterations before broad deployment.
- Home assistants with general-purpose dexterity (consumer robotics)
- Use cases: complex household tasks involving in-hand manipulation (e.g., opening caps, turning knobs, rotating utensils mid-task, toy assembly).
- Tools/workflows: extended training for diverse household items; continuous self-supervised adaptation via low-risk data collection; integration with high-level planners.
- Dependencies: cost-effective dexterous hands; reliable multimodal sensing; long-tail generalization across clutter and variable surfaces; robust safety.
- Robotic prosthetics with adaptive in-hand manipulation (healthcare)
- Use cases: assist users in rotating everyday objects (pens, utensils, bottles) with limited sensing; adapt to each user’s preferences and environments.
- Tools/workflows: embedded joint-wise dynamics models tuned to individual prosthetics; on-device “Chaos Box”-style low-risk data (soft loads, wearable-safe).
- Dependencies: medical device certification; integration with EMG/neural control; comfort, weight, battery life; personalized safety limits.
- Surgical and medical robotics (healthcare)
- Use cases: instrument rotation inside constrained spaces; safe in-hand manipulation of delicate tools; alignment tasks during minimally invasive procedures.
- Tools/workflows: high-fidelity simulators with realistic tissue contact; policy verification under safety-critical constraints; surgeon-in-the-loop teleop with assistive micro-rotations.
- Dependencies: stringent regulatory approval; formal safety and stability guarantees; sterilization, traceability, and fail-safe designs.
- Extreme environment maintenance (energy, infrastructure, space, nuclear)
- Use cases: remote in-hand manipulation of tools/components where sensing is limited; rotating parts for inspection/repair in hazardous zones.
- Tools/workflows: teleoperation augmented by robust rotation primitives; autonomous adaptation with low-risk load data (simulated or proxy objects).
- Dependencies: radiation/pressure/temperature-hardened hardware; long-latency communications; reliability beyond lab conditions; domain-specific safety.
- Flexible automation for e-commerce and returns processing (industry)
- Use cases: handling the “long tail” of product shapes; align irregular items for scanning and repackaging with minimal human intervention.
- Tools/workflows: policy marketplaces (pretrained “rotation packs” per category); scheduled on-site data collection and residual refresh; KPI monitoring for mis-rotation and drop rates.
- Dependencies: change management; integration with existing WMS/ERP systems; cost-benefit relative to simpler grippers.
- General contact-rich manipulation beyond rotation (robotics, software)
- Use cases: in-hand rolling, finger gaiting for tool transitions, regrasping, complex non-prehensile maneuvers.
- Tools/workflows: extend the joint-wise dynamics approach to multi-contact transitions and object-aware planning; curriculum learning from specialists to generalists across skills.
- Dependencies: richer reward design without privileged sensing; scalable autonomous data strategies beyond soft-loads; closed-loop tactile integration (optional).
- Standardization of sim‑to‑real methods for dexterity (policy, academia)
- Use cases: benchmarks and certification processes for contact-rich manipulation; reproducible pipelines in shared facilities.
- Tools/workflows: reference datasets, simulators, and lab protocols (including Chaos Box variants); open leaderboards on multi-axis/wrist metrics.
- Dependencies: community buy-in; maintenance budgets; governance around data sharing and safety.
- Cost-down dexterous hardware ecosystem (hardware, manufacturing)
- Use cases: accessible multi-finger hands tuned to joint-wise models; modular fingertips optimized for contact variability.
- Tools/workflows: co-design cycles between hardware and learned dynamics; standardized proprioceptive sensing suites; OEM firmware supporting residual adaptation.
- Dependencies: supply chain readiness; durability in industrial duty cycles; service/support models.
- Human–robot collaboration with shared autonomy (workforce, policy)
- Use cases: mixed-initiative manipulation where robots handle micro-rotations while humans perform higher-level tasks; training programs for safe collaboration.
- Tools/workflows: HRC policies defining role boundaries; UI cues for when assistive rotations are active; logs for audit and incident analysis.
- Dependencies: ergonomic studies; legal frameworks; union/worker engagement and reskilling plans.
- Sustainability reporting and governance for autonomous data collection (policy)
- Use cases: guidelines for low-intervention, safe real-world data gathering; measuring energy use and waste reduction from reduced resets and human labor.
- Tools/workflows: audit trails for Chaos Box sessions; environmental impact metrics; risk assessments for different object classes.
- Dependencies: standardized reporting; third-party audits; alignment with ESG frameworks.
Cross-cutting assumptions and dependencies
- Hardware: multi-finger dexterous hand (e.g., LEAP/Allegro) with reliable proprioception and PD/torque control; optional fingertip force/contact sensing.
- Software stack: access to high-throughput simulation (Isaac Gym/MuJoCo); RL training and BC distillation; residual policy training; data pipelines for autonomous collection.
- Data: sufficient coverage via soft-load “Chaos Box” or analogous apparatus; occasional domain-specific refresh for new object classes; tolerance for noisy, object-agnostic real data.
- Safety and compliance: operator training for tool manipulation; industry-specific standards (ISO/ANSI); safeguards for public deployments.
- Performance bounds: the demonstrated object sizes/aspect ratios and wrist orientations; task success may degrade outside these ranges; upstream grasp stability is assumed.
Glossary
- Ablation study: A controlled analysis where components of a system are systematically removed or altered to assess their impact on performance. "A systematic ablation study validates the crucial role of our key design choices in both the dynamics model and the data collection strategy."
- Autonomous data collection: Gathering training data without human intervention, often via automated procedures or environments. "a fully autonomous data collection strategy that gathers diverse, real-world interaction data with minimal human intervention."
- Behavior Cloning (BC): A supervised learning approach where a policy is trained to imitate expert demonstrations. "We therefore use BC: roll out all oracle policies, aggregate only successful trajectories, and train a generalist via supervised learning."
- Chaos Box: A simple, automated setup that uses randomized loads from soft objects to collect diverse interaction data safely. "This approach, which we call the ``Chaos Box'' (Fig.~\ref{fig:method}(C))"
- Contact-rich dynamics: System behavior characterized by frequent, complex contact interactions that are hard to model and predict. "The complex, contact-rich dynamics of dexterous manipulation create a ``reality gap''"
- Covariate shift: A type of distribution shift where the input distribution changes between training and testing, while the conditional output distribution remains the same. "satisfying covariate shift, i.e., ."
- DAgger: Dataset Aggregation; an imitation learning algorithm that iteratively collects data from a learner’s policy with expert corrections. "Although DAgger-style distillation has been effective in prior work,"
- Data Processing Inequality (DPI): A principle stating that processing data cannot increase information about an unknown variable; in KL form, mappings cannot increase divergence. "Data Processing Inequality for KL (strict form)"
- Domain Randomization (DR): A sim-to-real technique that randomizes simulation parameters during training to improve real-world robustness. "Domain Randomization (DR), which broadens training distributions"
- Joint-wise neural dynamics model: A model that predicts each joint’s next state from its own history, factorizing the system to improve generalization and sample efficiency. "we learn a joint-wise neural dynamics model."
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from another reference distribution. "the projection contracts distribution shift: "
- LEAP hand: A specific robotic hand platform used for dexterous manipulation experiments. "our smaller LEAP hand matches or surpasses performance and succeeds on shapes it struggles with (e.g., elephant, bunny, teapot)."
- Model-based control: Control strategies that rely on an explicit model of system dynamics to plan or optimize actions. "learns residual or full models for the whole system for model-based control"
- Model-free reinforcement learning (RL): RL methods that do not learn an explicit model of the environment’s dynamics. "We adopt a model-free RL approach."
- Partially Observable Markov Decision Process (POMDP): A framework for decision-making under uncertainty where the agent receives observations rather than full states. "We formulate in-hand rotation as a finite-horizon Partially Observable Markov Decision Process (POMDP), "
- PD controller: Proportional-Derivative controller; a feedback controller that applies control based on current error and its rate of change. "is converted to torques via a PD controller and executed on the robot."
- Proprioception: Sensing of a robot’s internal states (e.g., joint positions/velocities) used as input for control or learning. "a short history of proprioception, fingertip and object states, per-joint/per-finger force measurements, binary contact signals, wrist orientation, and the target rotation axis"
- Proximal Policy Optimization (PPO): A policy gradient RL algorithm that uses clipped objective updates for stable learning. "We split objects into five categories and train an oracle policy for each with PPO~\citep{Schulman2017ProximalPO} in Isaac Gym~\citep{makoviychuk2021isaac}."
- Pushforward (of a distribution): The distribution obtained by mapping a random variable through a measurable function. "denote the pushforwards by and ."
- Residual MLP: A multilayer perceptron architecture that adds its output to the input (residual connection) to ease optimization. "We use and implement the policy as a residual MLP~\citep{He2015DeepRL}."
- Residual policy: An additional policy that outputs corrective actions to adapt or compensate a base policy. "we train a residual policy $\pi^{\mathrm{res}$"
- Sim-to-real (reality gap): The challenge of transferring policies trained in simulation to real hardware due to dynamics mismatches. "We introduce \href{https://meowuu7.github.io/DexNDM/}{DexNDM}, a sim-to-real approach that enables unprecedented in-hand rotation in the real world."
- Specialist-to-generalist (pipeline): A training strategy that distills multiple expert policies into a single generalist policy. "We attain the base policy via a specialist-to-generalist pipeline: train category-specific experts on data spanning aspect ratios and geometric complexities, then distill them into a unified policy."
- System Identification (SysID): The process of estimating model parameters of a system from observed data. "System Identification (SysID), which fits simulator parameters from real data"
- Tactile sensing: Sensing modality that measures physical contact properties (e.g., force, pressure) to inform manipulation. "rely on expensive hardware and sophisticated tactile sensing."
- Teleoperation: Remote control of a robot by a human operator, often using VR or haptic interfaces. "building a teleoperation system to perform complex dexterous tasks, such as tool-using (e.g., screwdriver, knife) and assembly"
- Time-to-Fall (TTF): A performance metric measuring how long an object is held/manipulated before failure. "Time-to-Fall (TTF)âduration until termination; in simulation, episodes are capped at 400 steps (20s) and TTF is normalized by 20s, while in the real world we report raw time"
- Whole-hand neural dynamics model: A learned dynamics model that predicts the next full hand state from the entire hand’s history and actions. "one way is to learn a ``whole-hand'' neural model."
Collections
Sign up for free to add this paper to one or more collections.