- The paper introduces a two-stage 4D generative world model that synthesizes wrist-view videos solely from anchor views, bridging a critical data gap.
- The methodology leverages a VGGT-based wrist head, SPC loss, and a diffusion-based video generator to ensure geometric and temporal consistency.
- Experimental results demonstrate state-of-the-art performance across datasets, significantly improving task completion and bridging the exocentric–egocentric gap.
WristWorld: Generating Wrist-Views via 4D World Models for Robotic Manipulation
Introduction and Motivation
WristWorld addresses a critical bottleneck in vision–language–action (VLA) robotics: the scarcity of wrist-view data in large-scale manipulation datasets. Wrist-view observations are essential for capturing fine-grained hand–object interactions, which are pivotal for precise manipulation and robust policy learning. However, most datasets predominantly provide anchor (third-person) views, resulting in a substantial anchor–wrist domain gap. Existing world models are unable to synthesize wrist-view sequences from anchor views alone, as they typically require a wrist-view first frame for conditioning. WristWorld introduces a two-stage 4D generative world model that bridges this gap, enabling the synthesis of geometrically and temporally consistent wrist-view videos solely from anchor views.
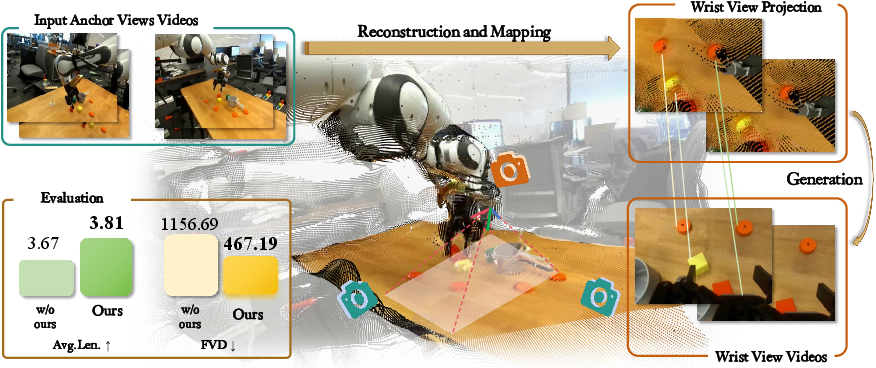
Figure 1: WristWorld synthesizes realistic wrist-view videos from anchor views via a two-stage process, expanding training data and improving downstream VLA model performance.
Methodology
Two-Stage 4D Generative World Model
WristWorld comprises two distinct stages: reconstruction and generation.
Reconstruction Stage:
This stage extends the Visual Geometry Grounded Transformer (VGGT) with a dedicated wrist head. The wrist head regresses wrist camera extrinsics (rotation and translation) from aggregated multi-view features using transformer-based attention. A novel Spatial Projection Consistency (SPC) loss is introduced, which enforces geometric alignment between 2D correspondences and reconstructed 3D/4D geometry using only RGB data, obviating the need for explicit depth or extrinsic supervision. The output is a sequence of wrist-view condition maps, generated by projecting reconstructed 3D scenes into the wrist-view image plane.
Generation Stage:
A diffusion-based video generator (DiT) synthesizes temporally coherent wrist-view videos conditioned on the wrist-view projections and CLIP-encoded anchor-view features. The conditioning stream concatenates VAE-encoded wrist-view projections with noisy wrist-view latents, and incorporates global semantics via CLIP and text embeddings. This design ensures that the generated wrist-view sequences are both geometrically consistent and semantically aligned with the anchor views.
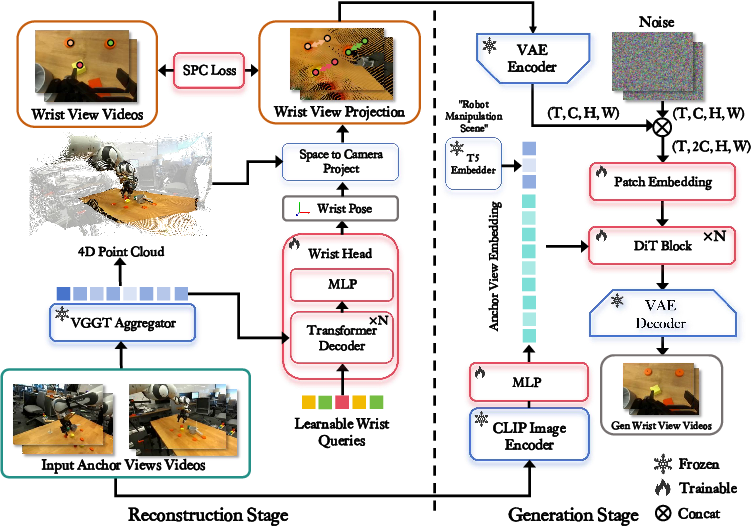
Figure 2: Overview of the two-stage 4D generative world model: reconstruction (VGGT + wrist head + SPC loss) and generation (DiT conditioned on wrist projections and CLIP features).
Key Components
- Wrist Head: Transformer decoder with learnable wrist queries, regressing wrist camera pose from multi-view features.
- SPC Loss: Enforces geometric consistency by penalizing reprojection errors and infeasible depth values, using dense 2D–2D correspondences lifted to 3D–2D pairs.
- Condition Map Generation: Projects reconstructed 3D scenes into wrist-view frames, providing temporally aligned structural guidance.
- Video Generation Model: DiT with expanded patch embedding to accommodate concatenated latents, conditioned on CLIP and text features for semantic fidelity.
Experimental Results
Quantitative and Qualitative Evaluation
WristWorld is evaluated on Droid, Calvin, and Franka Panda datasets. It achieves state-of-the-art performance across all video generation metrics (FVD, LPIPS, SSIM, PSNR) without requiring wrist-view first-frame guidance. Notably, on the Franka Panda dataset, WristWorld demonstrates robust generalization to real-world manipulation scenarios with significant viewpoint variation.

Figure 3: Generated condition maps exhibit superior viewpoint consistency compared to 3D Base and WoW 14B baselines.
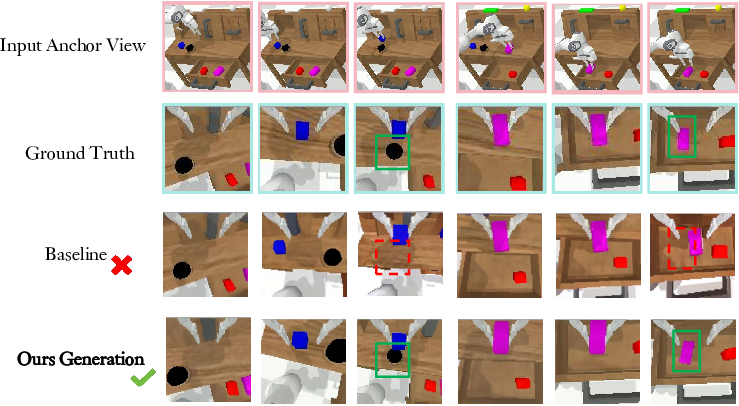
Figure 4: On the Calvin benchmark, WristWorld produces wrist-view videos with improved spatial and viewpoint consistency over SVD.

Figure 5: On Franka real-robot data, WristWorld generates wrist-view sequences closely matching ground-truth observations, demonstrating strong third-to-wrist generalization.

Figure 6: Qualitative visualization on Franka Panda: WristWorld maintains superior geometric consistency and wrist-following behavior compared to prior models.
Augmenting VLA training data with synthesized wrist-view videos from WristWorld yields measurable improvements. On Calvin, the average task completion length increases by 3.81%, and the anchor–wrist gap is closed by 42.4%. On Franka Panda, task success rates improve by 15.5% on average when using generated wrist views. These results confirm that synthetic wrist-view data provides effective supervisory signals for VLA models, enhancing both perception and control.
Plug-and-Play Extension
WristWorld can be integrated as a plug-in module to existing single-view world models, enabling post-hoc synthesis of wrist-view videos from anchor-view rollouts without requiring wrist-view initialization. This design facilitates scalable multi-view extension and enriches the observation space for downstream tasks.
Ablation Study
Ablation experiments reveal that wrist-view projection and SPC loss are critical for high-quality video generation. Removing either component leads to substantial degradation in temporal coherence and perceptual fidelity, underscoring the necessity of projection-based conditioning and geometric supervision.
Implementation Details
Implications and Future Directions
WristWorld provides a scalable solution for bridging the exocentric–egocentric gap in robotic datasets, enabling the synthesis of wrist-centric views from abundant anchor-view data. This approach reduces the need for costly wrist-view data collection and calibration, and facilitates the development of more robust VLA policies. The framework's plug-and-play design allows seamless integration with existing world models, promoting multi-view generalization and improved manipulation performance.
Future research may explore extending WristWorld to other egocentric perspectives (e.g., finger-tip or tool-mounted cameras), incorporating more advanced geometric priors, and leveraging self-supervised or unsupervised learning for further data efficiency. Additionally, investigating the impact of synthetic wrist-view data on policy transfer and sim-to-real adaptation remains a promising direction.
Conclusion
WristWorld introduces a principled two-stage 4D generative framework for synthesizing wrist-view videos from anchor views, leveraging geometric transformers, projection-based conditioning, and diffusion-based video generation. Empirical results demonstrate strong video generation quality and significant gains in downstream VLA performance. By augmenting datasets with wrist-centric views, WristWorld offers a practical and scalable solution for advancing robotic manipulation and embodied AI.
