MV-Performer: Taming Video Diffusion Model for Faithful and Synchronized Multi-view Performer Synthesis
Abstract: Recent breakthroughs in video generation, powered by large-scale datasets and diffusion techniques, have shown that video diffusion models can function as implicit 4D novel view synthesizers. Nevertheless, current methods primarily concentrate on redirecting camera trajectory within the front view while struggling to generate 360-degree viewpoint changes. In this paper, we focus on human-centric subdomain and present MV-Performer, an innovative framework for creating synchronized novel view videos from monocular full-body captures. To achieve a 360-degree synthesis, we extensively leverage the MVHumanNet dataset and incorporate an informative condition signal. Specifically, we use the camera-dependent normal maps rendered from oriented partial point clouds, which effectively alleviate the ambiguity between seen and unseen observations. To maintain synchronization in the generated videos, we propose a multi-view human-centric video diffusion model that fuses information from the reference video, partial rendering, and different viewpoints. Additionally, we provide a robust inference procedure for in-the-wild video cases, which greatly mitigates the artifacts induced by imperfect monocular depth estimation. Extensive experiments on three datasets demonstrate our MV-Performer's state-of-the-art effectiveness and robustness, setting a strong model for human-centric 4D novel view synthesis.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making new videos of a person from different camera angles (like front, side, and back) using only a single normal video as input. The system, called MV-Performer, can create a synchronized, 360-degree “multi-view” video of a performer that looks consistent across all angles and over time.
What questions were the researchers asking?
They focused on three simple questions:
- Can we turn one regular video of a person into a full 360-degree set of videos that all stay in sync?
- Can we keep the person’s look (clothes, identity, motion) consistent when the camera angle changes a lot, even to views we never saw (like the back)?
- Can we make this work on real-world videos, not just studio recordings, even when depth estimates (how far things are from the camera) are imperfect?
How did they do it?
Think of the goal like turning a single filmed performance into a “virtual stage” you can watch from any seat in the theater. Here’s the approach, in everyday terms:
1) A video generator that learns from lots of examples
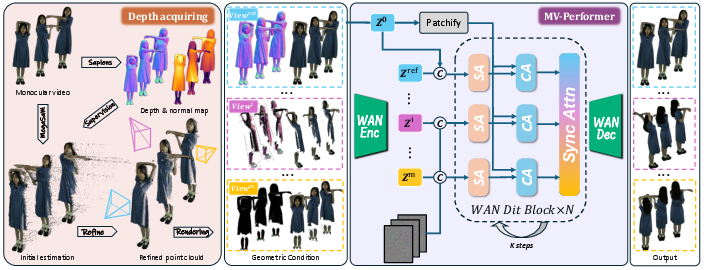
They start with a strong video diffusion model (a type of AI that turns noise into realistic videos by refining them step by step). It’s like a very skilled film editor that can imagine missing frames and views. They fine-tune it on a human-focused, multi-camera dataset so it understands how people look from many directions.
2) “Depth-based warping”: moving pixels like stickers in 3D
- Imagine each pixel in the input video is a sticker placed at the right distance in 3D space (this distance is called “depth”).
- If you “move the camera” to a new viewpoint, you can re-place those stickers to where they would appear from that new angle. This creates a rough preview for the model to fill in.
- This step is called depth-based warping. It gives the model a geometric hint about where things go in 3D when the camera moves.
3) “Normal maps”: telling the model what faces the camera
- A “normal” is like a tiny arrow sticking out of the surface of the person’s body, showing which way it faces.
- They create “camera-dependent normal maps,” which highlight areas facing the camera and darken areas facing away.
- Why this helps: when you turn to a back view, the warped image might be confusing (you never saw the back), but the normal map tells the model clearly what’s front-facing vs. back-facing at that new angle. It reduces confusion and helps the model guess the hidden parts better.
4) Keeping all views synchronized with attention
- “Reference attention”: The model looks back at the original video to keep identity and details consistent, like comparing notes with the original performance.
- “Sync attention”: The model lets different camera views talk to each other within the same time frame, so the front, side, and back agree frame-by-frame. Think of it like a conductor keeping multiple musicians (views) in sync.
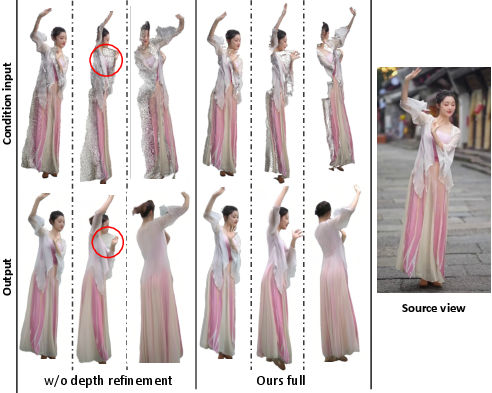
5) Making it work on real videos: refining depth
Real-world depth estimates can be messy (for example, causing “floaters” — bits that pop out where they shouldn’t). The authors:
- Combine a rough metric depth (how far in real units) with a sharper relative depth (good shapes) and surface normals.
- Align and refine them to clean up the 3D point cloud, so the warping looks neat and the model gets better guidance.
What did they find?
They tested on two multi-view human datasets and on real online videos. The key takeaways:
- MV-Performer creates synchronized, 360-degree multi-view videos from a single input video, with much better consistency and quality than prior methods.
- It keeps the same identity and clothing details across camera angles, and the motion stays in sync over time.
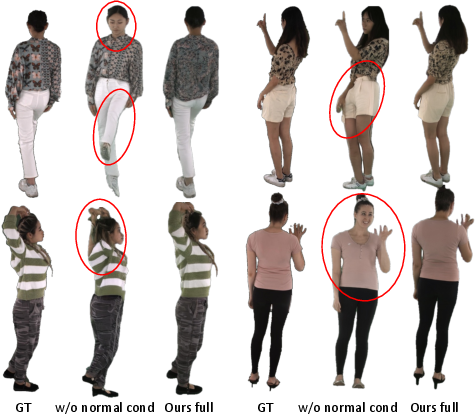
- The “normal map” trick is crucial for big camera changes (like turning to full back view).
- The “sync attention” helps different angles agree on details in each frame.
- The depth refinement step makes a big difference in real-world videos, reducing artifacts and weird “floaters.”
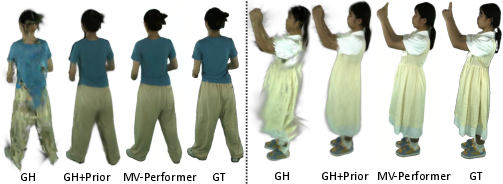
- It also helps other tools: the generated extra views can be used as “priors” (extra training material) to improve 3D avatar reconstruction from one video.
Why does this matter?
- It makes it possible to create free-viewpoint videos (watch a performance from anywhere around the person) from just one normal video.
- This could help in VR/AR experiences, filmmaking, sports replay, virtual try-on, and creating high-quality avatars without expensive multi-camera setups.
- It reduces the need for studio rigs with many synced cameras, making 360-degree content creation cheaper and more accessible.
Limitations and what’s next
- It still depends on decent depth estimation; bad depth gives worse results.
- Faces and very fine details can be hard to preserve perfectly.
- Generating videos with diffusion models takes time (multiple refinement steps), so it’s not instant.
- Like many AI models, it may reflect dataset biases and can struggle with looks it hasn’t seen much.
- Future work could speed it up (fewer steps), improve depth, and handle more diverse subjects and conditions even better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete directions that the paper leaves open for future work.
- Depth dependency and failure modes
- The method’s success hinges on accurate monocular metric depth and camera estimation (MegaSaM, UniDepthV2) and normal prediction (Sapiens); there is no end-to-end alternative if these fail. Explore learning the depth/normal refinement jointly with the diffusion model or integrating uncertainty-aware conditioning to gracefully handle poor estimates.
- The proposed depth refinement (scale–shift alignment + normal-guided optimization) is not quantitatively ablated (e.g., per-component gains, robustness across domains); a systematic study and standardized protocol for monocular depth refinement in 4D NVS is missing.
- No bundle-adjustment or temporal smoothing is applied to in-the-wild camera/depth trajectories; investigate temporal calibration stabilization to reduce drift across frames in moving-camera inputs.
- Conditioning design and visibility modeling
- The camera-dependent normal map masks back-facing surfaces as black, which resolves some ambiguity but discards useful cues and does not model self-occlusion or visibility accurately. Assess improved conditioning (e.g., z-buffer visibility, soft visibility, confidence/uncertainty maps, learned occlusion priors).
- The reliance on oriented point clouds assumes sufficiently accurate normals; analyze sensitivity to normal noise and explore alternative geometric encodings (e.g., TSDF, surfel splats with per-point confidence, signed visibility fields).
- Synchronization and 3D consistency
- The “sync attention” is a frame-level spatial self-attention across views; there is no explicit 3D consistency constraint (e.g., cross-view reprojection consistency, geometry-aware attention, or shared 3D latent). Evaluate whether adding explicit multi-view geometry constraints improves cross-view alignment.
- No metric specifically evaluates multi-view synchronization or cross-view consistency (beyond per-video FVD). Develop and report standardized cross-view consistency metrics (e.g., cycle reprojection error, cross-view identity feature consistency, silhouette/mesh overlap).
- It remains unclear how the method scales with the number of target views m; complexity and attention scaling with many views are not studied. Explore memory-efficient multi-view aggregation and variable-m setting.
- Temporal robustness and long-range generation
- Experiments use relatively short clips (e.g., 49 frames). Robustness to long sequences (minutes), temporal drift, and reappearance consistency is not evaluated. Investigate streaming/causal generation and long-horizon memory mechanisms.
- Large and rapid motions, motion blur, and strong occlusions are not stress-tested in a controlled way. Create benchmarks and ablations quantifying performance under increasing motion magnitude/velocity and occlusion severity.
- Generalization scope and coverage
- Single-performer assumption: multi-person interactions, inter-person occlusions, and close-contact scenes are not addressed. Extend to multi-person settings with layered human/background modeling and collision-aware visibility.
- Backgrounds: the approach is human-centric, but background modeling and view-consistent background synthesis/compositing are not analyzed. Evaluate layered generation (foreground–background disentanglement) and background control.
- Generalization to diverse body shapes, clothing materials (reflective/transparent), accessories, props, and complex hairstyles is not systematically evaluated. Build targeted test suites and adapt conditioning to handle challenging materials.
- Camera trajectories: continuous free-view camera control, extreme elevations (top-down), zoom, and rapidly varying intrinsics are not studied. Assess trajectory coverage and propose continuous trajectory control mechanisms.
- Identity and facial detail fidelity
- The paper notes difficulty preserving facial details due to WAN2.1 VAE constraints. Quantify identity preservation (e.g., face-ID similarity across views/time) and explore face-specific modules, super-resolution, or face-conditioned refinement.
- Back-view hallucination can produce plausible but incorrect textures relative to ground truth. Investigate constraints (e.g., garment priors, texture symmetry cues, sparse back-view exemplars) to improve faithfulness when ground truth is available.
- Model scale, efficiency, and deployment
- Only the 1.3B WAN2.1 variant is explored; scaling laws (quality vs. parameters) and trade-offs (quality vs. speed) are not reported. Study model size scaling, distillation, and one-step solvers for real-time or interactive use.
- Inference cost remains high due to multi-step denoising. Evaluate consistency-preserving acceleration (pruning, KV-caching, latent caching across views) and quality–speed Pareto fronts.
- Dataset constraints and biases
- Training relies on MVHumanNet’s limited camera distributions (fixed cages, 16–60 views) and may underrepresent diverse trajectories and demographics; implicit camera embeddings were dismissed partly due to training-view scarcity. Test whether combining explicit depth/normal conditioning with camera embeddings or synthetic camera augmentation improves generalization.
- The paper acknowledges potential demographic bias (skin tones, “origin”); no fairness evaluation is provided. Establish bias audits and balanced datasets; measure performance across demographic and appearance strata.
- Evaluation breadth and baselines
- Some key baselines (e.g., Human4DiT, Disco4D) are omitted due to training cost/code availability; consider proxy comparisons or standardized subsets to enable broader benchmarking.
- Metrics focus on per-frame/sequence quality (PSNR/SSIM/LPIPS/FID/FVD) but omit geometry-oriented metrics (e.g., multi-view silhouette IoU, PCK on projected keypoints, reprojection error). Introduce geometry-aware evaluation for 4D NVS.
- Integration with reconstruction and downstream tasks
- The application as a generative prior for reconstruction is promising but limited to GauHuman; broader studies (NeRF/3DGS variants, texturing pipelines, tracking) and failure analyses are missing. Quantify how many synthetic views, which angles, and what quality thresholds most benefit reconstruction.
- End-to-end joint training that couples MV-Performer with 3D reconstruction (e.g., optimizing a scene prior or a shared 3D latent) is not explored; assess whether joint optimization improves faithfulness and consistency.
- Uncertainty, reliability, and safety
- No uncertainty estimates are provided for generated views; develop confidence maps or ensemble-based uncertainties to indicate reliability under large extrapolations.
- The method can generate realistic unseen views, raising provenance/privacy concerns; propose watermarking, provenance tracking, or usage guidelines for responsible deployment.
- Ablation gaps
- Limited ablations on: number/distribution of training views, number of target views m, impact of camera pose noise, dependence on segmentation/matting quality, and sensitivity to each third-party estimator (depth/normal/camera). Conduct controlled ablations to map failure boundaries and robustness envelopes.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s released code and methods, with offline processing and current hardware/software dependencies.
- Free-viewpoint human video from single-camera footage for post-production
- Sector: media/film/TV, advertising, content platforms
- Tool/product/workflow: “Orbit Camera” operator in NLEs or Blender; pipeline uses MegaSaM (camera+metric depth), Sapiens (relative depth+normals), oriented point-cloud rendering, MV-Performer inference to generate synchronized 360-degree views
- Assumptions/dependencies: single, full-body performer; reasonable monocular depth quality; offline GPU (≈24 GB VRAM) with 25–50 sampling steps; domain similar to MVHumanNet; rights to use footage; WAN 2.1 and third-party models licensing
- Rapid previz, blocking, and stunt planning with multi-view synthesis from rehearsal takes
- Sector: film/TV production, live events
- Tool/product/workflow: on-set capture with handheld camera; generate multi-view clips for directors/DPs to explore angles without multi-cam rigs
- Assumptions/dependencies: scene motion not too fast; performer segmented cleanly; background complexity may affect depth; offline turnaround
- Social media and creator tooling: 360-degree “turntable” effects from one take
- Sector: creator economy, short video apps
- Tool/product/workflow: plugin or desktop app that uploads a clip and returns synchronized side/back views for edits/transitions
- Assumptions/dependencies: single-person, full-body framing; acceptable identity/clothing fidelity; compute time per clip; content provenance tagging recommended
- E-commerce fashion content: dynamic 360-degree garment visualization from a single runway or studio clip
- Sector: retail/e-commerce, fashion brands
- Tool/product/workflow: batch process studio clips to produce back/side views; integrate into PDPs or lookbooks
- Assumptions/dependencies: consistent lighting/background; garment details on unseen sides are synthesized (may deviate from ground truth); brand QA required
- Sports coaching and dance instruction from single-camera recordings
- Sector: education, sports analytics, performing arts
- Tool/product/workflow: generate side/back views to analyze posture and form; annotate results in coaching software
- Assumptions/dependencies: not a medical-grade tool; accuracy depends on depth and motion complexity; single-performer clips
- Generative priors for monocular avatar/volumetric reconstruction
- Sector: AR/VR avatars, gaming, digital humans
- Tool/product/workflow: use MV-Performer to synthesize side/back views, then feed multi-view sequences into 3DGS/NeRF pipelines (e.g., GauHuman) to reduce rear-view artifacts and improve reconstructions
- Assumptions/dependencies: reconstruction stacks can ingest generated views; identity consistency acceptable; synthesized textures differ from ground truth but act as useful priors
- Academic dataset augmentation for 3D human modeling and multi-view learning
- Sector: academia/research
- Tool/product/workflow: augment monocular datasets with synchronized multi-view sequences to train generalizable human NeRF/3DGS, pose/motion estimation, and multi-view consistency models
- Assumptions/dependencies: proper labeling of synthetic content; domain alignment with target tasks; ethical data usage
- Video editing and VFX QA
- Sector: VFX/post production
- Tool/product/workflow: check wardrobe continuity or silhouette readability across views without reshoots; quickly iterate shot design
- Assumptions/dependencies: synthesized back-side details are inference-based; human review required
Long-Term Applications
These applications require further research, scaling, system integration, or model development (e.g., distillation, multi-person support, higher resolution, robust depth).
- Real-time or near-real-time free-viewpoint broadcast from minimal camera setups
- Sector: sports broadcast, live events
- Tool/product/workflow: distilled one-step or few-step models with hardware acceleration; low-latency pipeline combining fast depth, segmentation, and MV-Performer-style synthesis
- Assumptions/dependencies: faster sampling (model distillation), robust depth in diverse venues, multi-person handling, latency budgets
- Mobile or cloud apps for consumer “rotatable person videos”
- Sector: consumer software, social apps
- Tool/product/workflow: one-tap 360-degree human video from smartphones; cloud inference with watermarking/provenance
- Assumptions/dependencies: cost-effective compute; content labeling; UX for quality control; bandwidth management
- Telepresence and volumetric streaming with monocular capture
- Sector: enterprise collaboration, AR/VR
- Tool/product/workflow: capture single-camera feeds and generate view-synchronized avatars for immersive meetings; integrate into platforms like VRChat
- Assumptions/dependencies: multi-person and occlusions; identity/face details; temporal stability; privacy and consent workflows
- Integrated pipelines that jointly optimize 3DGS/NeRF with multi-view diffusion guidance
- Sector: digital humans, VFX, game engines
- Tool/product/workflow: co-training generative multi-view synthesis with 3D representations for consistent geometry and appearance across views
- Assumptions/dependencies: algorithmic coupling, differentiable rendering integration, training cost
- Healthcare and rehabilitation: remote multi-view assessment from single-camera sessions
- Sector: healthcare
- Tool/product/workflow: generate clinically relevant side/back views for posture/gait assessment; integrate with motion analytics
- Assumptions/dependencies: clinical validation and regulatory approval; robust tracking; fairness across demographics; data security
- Robotics and human–robot interaction: synthetic multi-view motion datasets
- Sector: robotics, AI/ML
- Tool/product/workflow: produce diverse, synchronized views for training human pose/intent recognition from limited camera setups
- Assumptions/dependencies: physical plausibility of synthesized views; label quality; domain transfer to real deployments
- Multi-person and interaction scenes with 360-degree synthesis
- Sector: events, performance capture, crowd analytics
- Tool/product/workflow: extend models to multiple subjects, occlusions, and interactions; synchronized viewpoint generation for groups
- Assumptions/dependencies: new datasets, model capacity, improved segmentation/depth for multi-person scenes
- Higher-fidelity identity and face detail preservation at production resolution
- Sector: film/TV, digital identity
- Tool/product/workflow: train larger or specialized backbones; fine-tune VAEs; high-res inference for close-ups
- Assumptions/dependencies: compute scale, data with high-quality facial detail, improved latent architectures
- Policy and governance tooling for synthetic multi-view content
- Sector: policy/regulation, platforms
- Tool/product/workflow: standards for disclosure, watermarking, and provenance (e.g., C2PA); platform moderation policies; dataset governance and consent management
- Assumptions/dependencies: cross-industry adoption; legal frameworks; public awareness
- Bias, safety, and fairness evaluation frameworks for human-centric multi-view generation
- Sector: academia/policy/industry
- Tool/product/workflow: benchmarks and audits addressing skin tone, attire, body types; safety mitigations; robust depth across domains
- Assumptions/dependencies: representative datasets; transparent model reporting; collaboration across stakeholders
- Fashion/retail virtual try-on with volumetric motion and accurate garment back-side synthesis
- Sector: retail/e-commerce
- Tool/product/workflow: combine multi-view synthesis with garment simulation; interactive try-on with motion
- Assumptions/dependencies: physically based cloth modeling; accurate back-side texture inference or capture; user privacy
Cross-cutting assumptions and dependencies
- Technical: robust monocular depth and normal estimation (current method integrates MegaSaM + Sapiens + refinement), single-performer full-body framing, manageable motion, GPU availability, and the WAN 2.1 backbone with 25–50 steps sampling.
- Data and domain: training on MVHumanNet-style data; generalization may degrade for out-of-domain appearances, lighting, or backgrounds; multi-person scenes not yet supported.
- Legal/ethical: rights to input footage; privacy and consent for generating unseen views; disclosure and provenance for synthetic content.
- Performance: offline processing time; resolution currently around 480px; potential improvements via distillation and larger backbones.
Glossary
- 3D Gaussian splatting (3DGS): A point-based rendering approach that models scenes with anisotropic 3D Gaussians for efficient, photorealistic rendering. Example: "3D Gaussian splatting~\cite{kerbl20233d}"
- 3D human prior: A learned or parametric model of human shape/pose used to guide reconstruction or rendering from sparse inputs. Example: "use 3D human prior to anchor the pixel-aligned features accurately on the human template."
- 3D VAE: A variational autoencoder that jointly encodes video frames into a temporally-aware latent representation. Example: "A key component of this framework is a 3D VAE that jointly encodes video frames into a temporally-aware latent space"
- 4D human novel view synthesis: Generating time-varying multi-view renderings (3D over time) of a human from limited inputs. Example: "4D human novel view synthesis"
- Articulated avatars: Digital human models with articulated joints enabling realistic movement and deformation. Example: "articulated avatars with enhanced detail."
- Camera intrinsics/extrinsics: Calibration parameters describing camera internal projection (intrinsics) and pose in world coordinates (extrinsics). Example: "consisting of intrinsics and extrinsics "
- Camera-dependent normal map: A view-aware surface orientation map where back-facing normals relative to the camera are masked to reduce ambiguity. Example: "we render the camera-dependent normal map from oriented point clouds"
- Cross-attention: An attention mechanism that fuses information between queries and external key-value features (e.g., reference video latents). Example: "we implement cross-attention mechanisms between and reference latents "
- Depth-based warping: Reprojecting RGBD content from one view to another using estimated depth and camera parameters to create partial renderings. Example: "depth-based warping paradigm"
- Differentiable rendering: Rendering formulations that allow gradients to flow through geometric and shading computations for learning. Example: "corresponding differentiable rendering techniques"
- Diffusion Probabilistic Models: Generative models that iteratively denoise samples from noise to data distributions. Example: "Diffusion Probabilistic Models~\cite{sohl2015deep,song2019generative,ho2020denoising} have witnessed huge success"
- Diffusion Transformer (DiT): A transformer-based diffusion backbone operating on latent spatio-temporal tokens for video generation. Example: "a Diffusion Transformer (DiT) model is employed for video generation"
- FID: Fréchet Inception Distance, an image-level metric assessing distributional similarity between generated and real data. Example: "FID \cite{heusel2017gans}"
- Flow matching: A generative modeling technique that learns a velocity field to transport noise to data via an ODE. Example: "Flow matching models~\cite{lipman2022flow, esser2024scaling}"
- FVD: Fréchet Video Distance, a video-level metric evaluating temporal and perceptual quality of generated sequences. Example: "FVD \cite{unterthiner2018towards}"
- GPU-accelerated 3DGS rasterization: Hardware-optimized rendering of 3D Gaussian splats for fast, high-quality view synthesis. Example: "GPU-accelerated 3DGS rasterization~\cite{kerbl20233d}"
- Implicit canonical geometry: A learned body-centric 3D representation in a canonical pose/space used for consistent human modeling. Example: "learn a plausible implicit canonical geometry~\cite{pumarola2021d} of clothed humans."
- In-the-wild: Data captured under unconstrained, real-world conditions without studio setups. Example: "collected in-the-wild datasets"
- MegaSaM: A method for unified metric depth and camera estimation from monocular videos. Example: "MegaSaM \cite{li2024_megasam}"
- Metric depth: Depth values with real-world scale, enabling accurate geometric reasoning and reprojection. Example: "metric depth "
- Monocular depth estimation: Inferring per-pixel depth from a single camera view. Example: "imperfect monocular depth estimation"
- Multi-view stereo: Reconstructing 3D geometry by matching and triangulating features across multiple calibrated views. Example: "multi-view stereo~\cite{seitz2006comparison,furukawa2015multi}"
- NeRF: Neural Radiance Fields, an implicit volumetric representation enabling photorealistic novel view synthesis. Example: "neural radiance fields (NeRF)~\cite{mildenhall2020nerf}"
- Normal map: A per-pixel or per-point encoding of surface normals used to convey orientation and refine geometry. Example: "normal map"
- Oriented partial point clouds: View-limited colored point sets with associated normals indicating surface orientation. Example: "oriented partial point clouds"
- Ordinary differential equation (ODE): The continuous-time formulation used to integrate learned velocity fields for generation. Example: "through an ordinary differential equation (ODE)."
- Plücker ray: A 6D line representation used as camera pose embedding for view control in diffusion models. Example: "Plücker ray as the camera embedding \cite{bai2024syncammaster,bai2025recammaster,hecameractrl}"
- PSNR: Peak Signal-to-Noise Ratio, a pixel-level fidelity metric comparing generated and ground-truth frames. Example: "PSNR \cite{psnr}"
- Reference attention mechanisms: Attention modules that condition generation on a reference video to preserve identity and details. Example: "reference attention mechanisms"
- RGBD-warping: Reprojecting RGB with aligned depth (D) from a source to target view to form geometric cues. Example: "we perform RGBD-warping with known camera parameters"
- SMPLX: A parametric human body model with expressive face and hands used for fitting and alignment. Example: "SMPLX fitting"
- SSIM: Structural Similarity Index, a metric assessing perceptual structural fidelity. Example: "SSIM \cite{ssim}"
- Synchronized attention mechanism: Frame-level spatial self-attention that aggregates information across views to enforce consistency. Example: "The synchronized attention mechanism effectively aggregates per-frame information"
- Unprojection: Mapping image pixels and depths into 3D world coordinates to build point clouds. Example: "we first unproject the 2D pixels "
- Velocity field: The vector field learned in flow matching that transports samples from noise to data. Example: "learns a velocity field $v_\theta"
- Video diffusion model: A diffusion-based generative model producing temporally coherent video sequences. Example: "video diffusion model"
- Volumetric occupancy fields: 3D scene representations that define occupied volumes for rendering/reconstruction. Example: "volumetric occupancy fields~\cite{huang2018deep}"
- WAN 2.1: A flow-matching video generation framework with a 3D VAE backbone for temporally consistent synthesis. Example: "WAN 2.1 \cite{wan2025wan}"
- Warping floater: Artifacts appearing as misprojected blobs during large viewpoint changes due to depth errors. Example: "image warping floater at large viewpoints change would be intolerable"
Collections
Sign up for free to add this paper to one or more collections.