Code World Models for General Game Playing
Abstract: LLMs reasoning abilities are increasingly being applied to classical board and card games, but the dominant approach -- involving prompting for direct move generation -- has significant drawbacks. It relies on the model's implicit fragile pattern-matching capabilities, leading to frequent illegal moves and strategically shallow play. Here we introduce an alternative approach: We use the LLM to translate natural language rules and game trajectories into a formal, executable world model represented as Python code. This generated model -- comprising functions for state transition, legal move enumeration, and termination checks -- serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS). In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient), and inference functions (to estimate hidden states in imperfect information games). Our method offers three distinct advantages compared to directly using the LLM as a policy: (1) Verifiability: The generated CWM serves as a formal specification of the game's rules, allowing planners to algorithmically enumerate valid actions and avoid illegal moves, contingent on the correctness of the synthesized model; (2) Strategic Depth: We combine LLM semantic understanding with the deep search power of classical planners; and (3) Generalization: We direct the LLM to focus on the meta-task of data-to-code translation, enabling it to adapt to new games more easily. We evaluate our agent on 10 different games, of which 4 are novel and created for this paper. 5 of the games are fully observed (perfect information), and 5 are partially observed (imperfect information). We find that our method outperforms or matches Gemini 2.5 Pro in 9 out of the 10 considered games.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper from Google DeepMind explores a new way to make AI good at playing many different board and card games. Instead of asking a LLM (like a chatbot) to directly choose moves—which can lead to illegal moves or shallow thinking—the researchers ask the model to write the game’s rules as computer code. Then a classic game-planning method uses that code to think ahead many steps and pick strong moves.
They call this approach a “Code World Model” (CWM): the LLM turns text rules and a few example games into a small, working game simulator written in Python. That simulator is then used for deep planning.
What questions did the researchers ask?
- Can a LLM write accurate code for a game’s rules after reading the rules and watching a few example games?
- Will planning with that code lead to smarter, more reliable play than asking the LLM to pick moves directly?
- Can this work on both:
- perfect information games (everyone sees everything, like Chess), and
- imperfect information games (some things are hidden, like Poker)?
- Can the system handle brand-new games it has never seen before?
- Can we add “helper code” to speed up planning and handle hidden information?
How did they do it?
Here’s the big idea: turn rules into code, then use that code to plan.
Building a “Code World Model” (CWM)
The LLM reads:
- a plain-English description of the game’s rules, and
- a few recorded example games (“trajectories,” which are lists of moves and what players see).
It then writes Python code that:
- keeps track of the current state of the game (like pieces on a board or cards in hands),
- lists which moves are legal,
- updates the state when a move happens,
- checks if the game is over and who gets points,
- and (for hidden-information games) describes what each player can see.
Think of this like writing a tiny, trusted game engine for each game.
Making the code correct (unit tests and fixes)
The first try isn’t perfect. So the team automatically creates unit tests from the example games:
- “Given this state and move, does your code predict the right next state?”
- “Are these the correct legal moves?”
- “Is this the right score?”
If a test fails, the LLM gets the error message and tries to fix the code. The paper uses two refinement styles:
- Sequential chat: fix tests one by one.
- Tree search: keep multiple versions of the code and improve the most promising ones first (using a strategy called Thompson sampling).
Planning with the model (MCTS/ISMCTS)
Once the CWM is ready, the agent plays by planning rather than guessing. It uses:
- MCTS (Monte Carlo Tree Search) for perfect information games.
- ISMCTS (Information Set MCTS) for hidden-information games.
In simple terms, MCTS tries lots of “what if” futures, like exploring branches of a tree, and uses the results to pick better moves now.
Handling hidden information (inference functions)
In games like Poker, you can’t see everything. The planner needs a good guess about the hidden parts (like the opponent’s cards). So the LLM also writes an “inference” function—code that samples a plausible hidden state consistent with what a player has seen so far.
Two styles:
- Hidden history inference: guess a full sequence of unseen actions (including random events like card draws), then reconstruct the hidden state. This is stricter and often more accurate.
- Hidden state inference: guess the hidden state directly. Easier to write, but less guaranteed to be consistent.
These inference functions are also tested and refined so they match the observations from the example games.
Learning without seeing hidden info (“closed deck”)
Sometimes you can’t peek at the hidden parts even during training (like when learning from real online games). The paper proposes an “autoencoder-like” trick:
- The inference function “encodes” what you saw into a guess about hidden actions.
- The CWM “decodes” that guess back into the observations you should see.
- Unit tests check that decoding matches the real observations and that the code runs without errors.
This setup nudges the model to learn consistent hidden states without ever seeing the true hidden information.
Speeding up with value functions
To make planning faster, the LLM also writes a “value function”:
- A small piece of code that estimates how good a position is, without having to simulate all the way to the end.
- They generate several candidate value functions and keep the best one after testing them against each other.
What did they find?
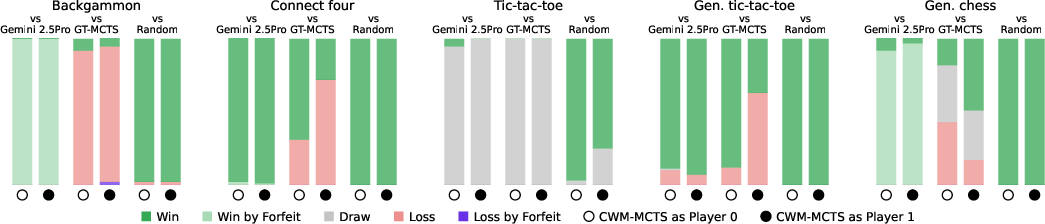
Across 10 games (5 perfect information, 5 imperfect), including 4 brand-new games designed for this study:
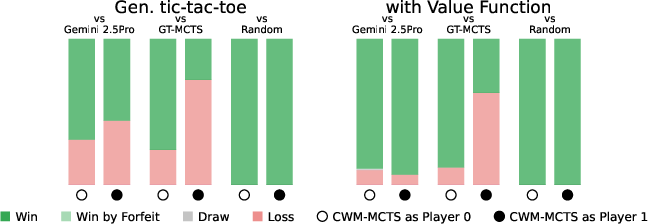
- The CWM approach outperformed or matched a strong LLM player (Gemini 2.5 Pro used directly as a move chooser) in 9 out of 10 games.
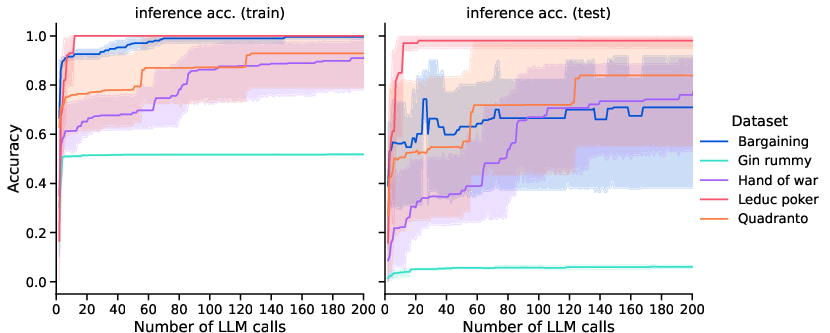
- Perfect information games: the learned simulators were highly accurate, and planning on top of them worked very well.
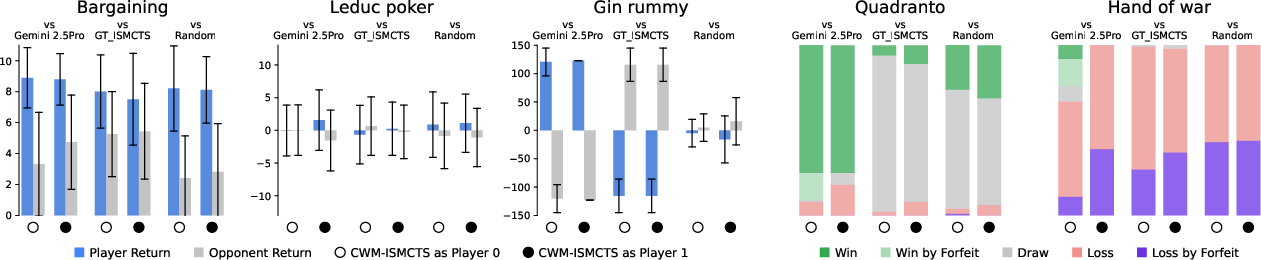
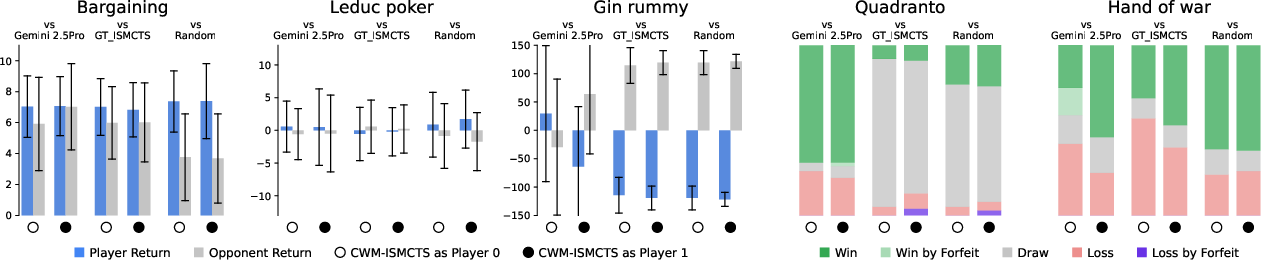
- Imperfect information games (with hidden history inference): accuracy was strong in most games. Gin Rummy was the hardest due to its complex scoring and multi-step logic.
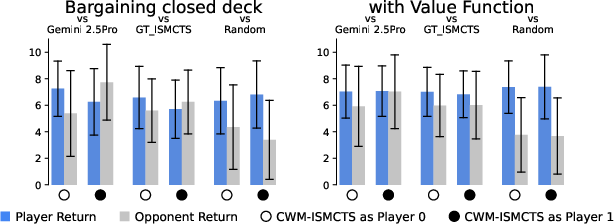
- “Closed deck” learning (no hidden info during training): code accuracy dropped, but actual gameplay performance stayed surprisingly competitive.
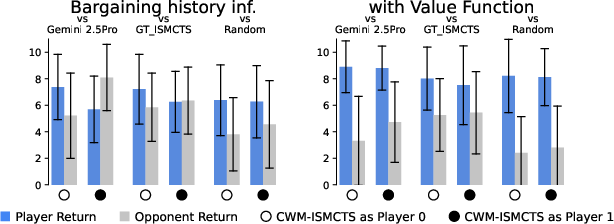
- Value functions sometimes gave a clear boost (for example, in Bargaining and generalized Tic-tac-toe).
- Compared to direct LLM move-picking, the CWM approach:
- made far fewer illegal moves,
- showed deeper strategy via planning,
- and adapted better to brand-new games.
Why this matters:
- Verifiable: The code lists legal moves and checks the rules. This prevents nonsense moves.
- Strategic depth: Classic search (MCTS) can look many steps ahead, leading to smarter play.
- Generalization: Turning “data + rules” into code helps the system adapt to new games more easily.
What does this mean going forward?
- Smarter, safer game AIs: By asking LLMs to write the rules as code, we get agents that follow the rules, think ahead, and play strongly, even in games they’ve never seen.
- Beyond games: The same idea—“let the AI write a small simulator, then plan in it”—could help in other areas with clear rules, like puzzles, simulations, or simple real-world tasks with instructions.
- Handling hidden information: The inference-as-code idea and the autoencoder-like training could make AIs better at reasoning under uncertainty.
- Next steps: Improve learning for very complex games (like Gin Rummy), learn and refine the code continually while playing, and extend to open-world settings with free-form text or visuals.
In short, this paper shows that combining LLMs (to write rule-following code) with classic planning (to think ahead) can beat using LLMs as players directly—and it works across many different games.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
- Verification coverage and overfitting: Unit tests are derived from 5 offline trajectories and modest random/MCTS rollouts, which may not cover rare rules, edge cases, or deep procedural branches (e.g., Gin rummy scoring). How to systematically increase coverage (fuzzing, property-based testing, symbolic execution) and provide formal guarantees beyond trajectory-matching?
- Ambiguity and robustness of rule-to-code translation: The approach presumes clear, complete textual rules. Robustness to ambiguous, inconsistent, or partially specified rule descriptions (and noisy trajectory logs) is untested. What prompt designs or constraint-checking can detect and recover from underspecified rules?
- Data efficiency vs complexity: Synthesis is attempted from only 5 trajectories, which appears insufficient for complex games (Gin rummy). How does accuracy scale with the number, diversity, and curation of trajectories, and can active data collection or query-driven test generation close gaps efficiently?
- Calibration and correctness of inference in IIGs: Inference functions focus on posterior support via observation reconstruction, not calibrated belief distributions. There is no evaluation of posterior quality (e.g., likelihood, calibration, entropy, support coverage) or sensitivity to opponent policies. How to estimate and validate belief quality beyond binary reconstruction checks?
- Identifiability in closed-deck “autoencoder” learning: The encoder–decoder setup can reconstruct observations with spurious latents that do not reflect true hidden variables or causal mechanisms. What constraints, priors, or structural regularizers (e.g., permutation/identity constraints, sparsity, consistency across episodes) are needed to ensure identifiable, faithful latent representations?
- Chance model learning: The method treats chance via deterministic functions plus sampling but does not evaluate whether learned chance distributions are accurate (only that specific samples are possible). How to learn, test, and calibrate chance outcome distributions from limited data?
- Scalability to larger and multi-player games: Experiments focus mainly on two-player games and moderate complexity. It is unclear how synthesis, unit testing, and ISMCTS scale to more players, deeper trees, simultaneous moves, or larger action/state spaces (e.g., full-scale Chess/Go variants, multi-player imperfect information games).
- Planning–compute scaling laws: The paper fixes (IS)MCTS to 1,000 simulations. There is no comprehensive study of performance vs search budget, or how value functions/inference quality change the compute–performance frontier. What are scaling curves and bottlenecks as simulations and thinking time increase?
- Value function synthesis quality: Value functions are selected by tournament without ground-truth targets or calibration metrics. There is no analysis of stability across seeds, generalization beyond the tournament opponents, or principled criteria for selection/refinement. How to train and validate value functions (e.g., via CWM rollouts, self-play, or fitted value iteration) and detect overfitting?
- Fairness and strength of baselines: The GT (IS)MCTS baseline is run without value functions while the CWM agent may use synthesized ones; the LLM-as-policy baseline uses a single prompting strategy. How do conclusions change with stronger or specialized baselines (e.g., CFR for poker, policy/value-guided MCTS, multiple LLMs/prompts, temperature/think-time sweeps)?
- Online/active model updating: The approach learns CWMs offline and does not update models during play. Can online refinement (active testing, discrepancy-driven debugging, rule repair) improve robustness and reduce compounding errors, especially in closed-deck settings?
- Reliability of inference metrics: For Gin rummy, “online” inference accuracy is high despite poor train/test accuracy, suggesting metric mismatch or distribution shift in evaluation. How to design consistent, informative inference metrics that reflect posterior correctness across train/test/online regimes?
- Opponent modeling and equilibrium reasoning: Opponents are implicitly modeled with simplistic priors (e.g., uniform legal moves or fixed baselines). How can synthesized CWMs incorporate opponent models or equilibrium solvers (e.g., CFR, regret minimization) to handle strategic adaptation?
- Search algorithm diversity: Only (IS)MCTS and PPO-on-CWM are explored. How do alternative solvers (e.g., POMCP, DESPOT, belief-state MCTS, CFR variants) compare when driven by CWMs and synthesized inference/value functions?
- Safety and sandboxing for generated code: Executing LLM-generated Python poses security and reliability risks (e.g., unsafe imports, resource abuse). What sandboxing, static analysis, and runtime guards are required for safe deployment?
- Uncertainty estimation and fallback policies: The agent lacks confidence measures for CWM/inference/value outputs. How can uncertainty drive fallback behaviors (e.g., more rollouts, human-in-the-loop checks, conservative moves) or trigger re-synthesis?
- Test generation for long-horizon logic: Current unit tests check local transitions and observation consistency; they do not enforce global invariants (e.g., conservation rules, scoring invariants, deck/card consistency across the episode). How to encode and test cross-time invariants and relational constraints?
- Handling invalid “validity”: Even when CWMs pass unit tests, they may enumerate legal actions inconsistent with true rules (“valid but wrong”). How to detect and penalize off-trajectory but rule-violating behaviors (e.g., SMT-based constraint checks, metamorphic tests)?
- Compute and cost transparency: Synthesis can require hundreds of LLM calls per game (e.g., 500 in Gin rummy), but wall-clock time, computational resources, and cost–benefit trade-offs are not reported. What is the end-to-end cost profile and how can it be reduced?
- Generalization beyond OpenSpiel/text: The method assumes OpenSpiel-style APIs and text descriptions. Extending to open-world, multimodal interfaces (GUI, natural dialogues, partial logs) is not demonstrated. What abstractions and toolchains are needed for multimodal code world modeling?
- LLM dependency and reproducibility: Results hinge on a specific model (Gemini 2.5 Pro) and prompts; sensitivity to LLM choice, temperature, and prompt variants is not explored. How robust is synthesis across providers and versions, and can standardized prompt suites or distillation mitigate variability?
- Dataset and reproducibility of synthesized CWMs: Only examples are shown; full synthesized code artifacts, seeds, and unit tests for all games are not clearly released. Without them, replicability and downstream benchmarking are limited.
- Integrating domain libraries and subroutines: Failures on complex procedural logic (Gin rummy) suggest benefits from reusable rule libraries, declarative constraints, or hybrid neuro-symbolic tools. How to compose LLM code with verified subroutines to reduce logical errors?
- Learning the right abstraction level: The framework fixes a low-level stepwise API. Some games may benefit from higher-level, macro-action or declarative rule abstractions. What criteria determine the best abstraction to synthesize for efficient planning and accurate inference?
- Distributional shift and self-play: CWMs are learned from random-policy and GT/MCTS mixtures but deployed against different opponents (LLM policy). How to mitigate distributional shift (e.g., via self-play data augmentation, adversarial test generation, curriculum) during synthesis and refinement?
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage the paper’s core contributions—LLM-synthesized Code World Models (CWM), heuristic value functions, and inference-as-code—paired with classical planners (MCTS/ISMCTS). Each item lists the sector, example tools/products/workflows, and key assumptions/dependencies.
- Game AI prototyping and QA
- Sector: Software, Gaming
- What to deploy now:
- Rulebook-to-Engine conversion: Automatically translate natural language game rules and a handful of trajectories into an executable Python simulator (OpenSpiel-style API) with legal move enumeration, transition, reward, termination, chance handling.
- Planner-backed bots: Plug MCTS/ISMCTS onto the synthesized CWM to produce strong, verifiable agents that avoid illegal moves.
- Automated unit-test generation: Create trajectory-derived tests to detect illegal moves, state-transition bugs, and observation mismatches; iteratively refine via LLM-guided code repair (conversation or tree search).
- Example tools/workflows:
- “CWM Builder” CLI or IDE plugin for studios; continuous integration (CI) test harness that auto-generates tests from play logs.
- Tournament bot pipeline: Synthesize CWM → synthesize heuristic value functions (tournament selection) → attach MCTS/ISMCTS → deploy.
- Assumptions/dependencies:
- Clear textual rules and a small set of representative trajectories; sandboxed execution of LLM-generated code; reliance on an LLM comparable to Gemini 2.5 Pro for synthesis quality.
- Referee and rules clarification assistants for tabletop and online games
- Sector: Consumer/Daily Life, Gaming
- What to deploy now:
- A “Referee bot” that reads rulebooks, synthesizes a verifiable CWM, and acts as a rules-checker to flag illegal moves and explain rulings based on the executable specification.
- Example tools/workflows:
- Mobile/web assistant for family board games; moderation bots for online platforms that check legality using the CWM API.
- Assumptions/dependencies:
- Accurate synthesis for typical board/card games; minimal setup (rules + a few example plays).
- Rapid curriculum and benchmarking in education and research
- Sector: Education, Academia
- What to deploy now:
- Course modules that teach game theory, POMDPs, and model-based planning by having students generate CWMs from text and compare LLM-as-policy vs planner-on-CWM performance.
- OOD evaluation: Generate new games and test generalization (as in ggbench/Kaggle Game Arena/TextArena).
- Example tools/workflows:
- Assignments/labs: Students refine CWMs via unit tests; attach MCTS/ISMCTS; analyze inference accuracy for imperfect information games (open deck and closed deck).
- Assumptions/dependencies:
- Access to OpenSpiel or similar frameworks; adequate LLM capacity; safe code execution environment.
- Model-based evaluation of LLM agents in strategic domains
- Sector: Academia, Software
- What to deploy now:
- Use CWM-based planners as baselines for benchmarking LLMs in strategy games; quantify verifiability and strategic depth vs direct LLM policies.
- Example tools/workflows:
- Automated pipelines that generate CWMs for test suites; compare win/loss/draw rates and forfeit rates against LLM-as-policy agents.
- Assumptions/dependencies:
- Stable evaluation harness; consistent compute budgets for (IS)MCTS.
- Spec-to-simulator for discrete processes beyond games (rules engines, finite-state workflows)
- Sector: Software (Rules/Workflow Engines)
- What to deploy now:
- Convert textual business rules or process descriptions into executable simulators; enumerate valid actions and verify transitions; use planners to explore edge cases.
- Example tools/workflows:
- “Spec2Sim” internal tooling for QA teams; audit of process legality and termination conditions via auto-generated unit tests.
- Assumptions/dependencies:
- Target domains must be sufficiently discrete and amenable to OpenSpiel-like APIs; careful adaptation of reward/termination semantics.
- Imperfect information planning with inference-as-code (open deck setup)
- Sector: Gaming, Academia
- What to deploy now:
- Hidden-history inference functions synthesized by LLMs to support ISMCTS on partially observed games (e.g., Leduc Poker, Bargaining), leveraging trajectory-derived unit tests.
- Example tools/workflows:
- ISMCTS pipeline with regularized inference samplers that pass observation-matching unit tests; tournament selection for heuristic value functions.
- Assumptions/dependencies:
- Post-hoc access to hidden information in training trajectories (open deck); stochastic unit tests that become deterministic for correct inference; quality degrades for highly procedural games (e.g., Gin rummy).
Long-Term Applications
These applications require further research, scaling, or productization—especially in handling complex procedural logic, richer observability, continuous dynamics, safety, and online learning.
- Closed-deck generalization and online CWM learning
- Sector: Gaming, Academia, Robotics (research)
- What could emerge:
- Autoencoder-like pipelines where inference functions (encoders) and CWMs (decoders) refine themselves from partially observed logs without ever peeking at hidden states; active/online learning to repair models during play.
- Potential tools/products:
- “Closed Deck Autoencoding” engine; active learning modules that select queries/experiments to disambiguate hidden causal mechanisms.
- Assumptions/dependencies:
- Robust code synthesis under strict partial observability; principled uncertainty handling; safe code repair loops; scalable planning under evolving models.
- Text-to-simulator for policy design and social systems analysis
- Sector: Policy, Public Administration, Finance, Energy
- What could emerge:
- Turn complex policy documents or market rules (auctions, negotiations) into executable simulators; compute equilibria or perform counterfactual planning (planner-in-the-loop) to test fairness, stability, and unintended effects.
- Potential tools/products:
- “PolicySim”: Rulebook-to-engine for regulatory sandboxing; “Negotiation Lab” for designing bargaining protocols and measuring outcomes.
- Assumptions/dependencies:
- Formalization of institutional rules into discrete, testable steps; governance for executing LLM-generated code; domain-specific validation (e.g., legal counsel).
- Agentic decision-support via text-to-simulator in enterprise operations
- Sector: Enterprise Software, Logistics, Finance, Energy
- What could emerge:
- Spec-to-simulator for discrete operational processes (e.g., scheduling, inventory moves) with ISMCTS planning under uncertainty; scenario testing with synthesized value functions.
- Potential tools/products:
- “Spec2Sim Enterprise” with sandboxed execution, audit trails, and verification; integration with operations dashboards.
- Assumptions/dependencies:
- Mapping real processes to discrete action/state spaces; performance and scalability; explainability and compliance requirements.
- Multi-modal CWMs for open-world and embodied agents
- Sector: Robotics, AR/VR, Education
- What could emerge:
- CWMs learned from visual rulebooks, UI screenshots, or video demonstrations; planners operating over synthesized simulators for complex tasks; bridging to POMDPs in robotics labs.
- Potential tools/products:
- “Visual Rulebook-to-Engine” and “UI2Sim” pipelines; embodied agent training with planner-backed reasoning.
- Assumptions/dependencies:
- Reliable perception-to-symbol mapping; continuous/physics dynamics integration; safety and real-time constraints.
- Fairness auditing and compliance testing for digital platforms
- Sector: Gaming, FinTech, Online Marketplaces
- What could emerge:
- Convert platform rules into CWMs and use planners to stress test fairness and detect exploitable loops; certify legality of outcomes (e.g., no illegal moves, transparent RNG).
- Potential tools/products:
- “Referee-as-a-Service” for platforms; audit dashboards showing verifiable behavior against executable rules.
- Assumptions/dependencies:
- Standardized APIs and audit protocols; privacy and security measures for play logs; acceptance by regulators.
- EdTech at scale: interactive tutors and auto-generated exercises with verifiable mechanics
- Sector: Education
- What could emerge:
- Tutors that synthesize CWMs for puzzles/games, verify student strategies, and provide planner-grounded feedback; generate OOD tasks to build transfer learning.
- Potential tools/products:
- “CWM Tutor” that pairs text-to-simulator with MCTS/ISMCTS; curriculum generation tools.
- Assumptions/dependencies:
- Robust synthesis for complex rules; classroom-friendly sandboxing; explainability and assessment alignment.
- Security-conscious code synthesis and verification frameworks
- Sector: Software Engineering, Cybersecurity
- What could emerge:
- End-to-end pipelines that safely generate, sandbox, test, repair, and certify executable rule engines; formal methods layered onto LLM-generated code.
- Potential tools/products:
- “Trusted CWM” with static/dynamic analysis, formal checks, and secure execution; Thompson-sampling refinement orchestration with provenance tracking.
- Assumptions/dependencies:
- Mature sandboxing; integration with formal verification tooling; attack surface analysis for generated code.
Cross-cutting assumptions and dependencies
- LLM synthesis quality and safety: Performance depends on the LLM’s ability to translate textual rules and sparse trajectories into correct code. Execution must be sandboxed.
- Domain fit: CWMs assume discrete action spaces, deterministic functions (with chance as the sole source of randomness), and tractable state representations.
- Test coverage and refinement budget: Unit tests derived from limited trajectories may miss rare branches; tree-search refinement (Thompson sampling) improves resilience but costs LLM calls.
- Planning compute: MCTS/ISMCTS benefits from compute budgets; synthesized heuristic value functions reduce rollout needs but may be brittle in complex, procedural games (e.g., Gin rummy).
- Data availability: Open deck (post-hoc hidden states) yields better synthesis than closed deck; closed deck autoencoder approaches need additional regularization or active learning.
- Integration and compliance: For policy/enterprise uses, mapping real systems to discrete simulators and obtaining governance approvals are non-trivial.
Glossary
- Belief state: The agent’s probability distribution over hidden states given its history of observations and actions. "More precisely, at play time, agent must be able to sample from its belief state , where is the estimated CWM."
- Chance node: A point in the game tree where stochastic events (e.g., dice rolls, card draws) occur according to a fixed distribution. "It contains functions providing logic to update the game state when an action is taken ... the distribution for chance nodes, and the reward function for a state."
- Closed deck synthesis: Learning a code world model using only observed actions and observations, without any access to hidden state information in trajectories. "We refer to this scenario as closed deck synthesis; to the best of our knowledge, this scenario has not been addressed in prior CWM work."
- Code World Model (CWM): An executable program that formalizes a game’s rules, state dynamics, observations, and rewards, enabling planning over a simulated environment. "We call the result of this process a “Code World Model” (CWM)."
- Determinized belief space planner: A planning approach for partially observable problems that fixes hidden variables to specific determinizations and plans as if fully observed. "In addition, \citet{curtis2025llm} use a determinized belief space planner (related to the POMCP method of \citet{Silver10POMCP}), whereas we use ISMCTS"
- Extensive-form games: A game-theoretic representation that models sequential actions, information sets, and chance within a game tree. "Interactions in multiplayer games can be described using the formalism of extensive-form games~\citep{Kuhn53,...}"
- General-sum game: A game where the sum of players’ payoffs is not constant; interests may be partially aligned or conflicting. "Our imperfect information games contain a mixture of ternary-outcome games, zero-sum games and general-sum games"
- Ground truth (GT) code: The actual, correct implementation of the game environment used as a reference. "an (IS)MCTS agent that has access to the game's ground truth (GT) code, including inference functions but not value functions"
- Heuristic value function: A learned or hand-crafted estimator of state value used to guide search and reduce simulation effort. "In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient)"
- Hidden history inference: Sampling plausible complete action histories (including chance actions) consistent with observed data to reconstruct hidden states. "Hidden history inference."
- Hidden state inference: Directly sampling hidden states from observations and actions without reconstructing the full action history. "Hidden state inference."
- Information Set MCTS (ISMCTS): A variant of MCTS that plans over information sets in imperfect information games, handling hidden information via sampling. "for imperfect information games, we use Information Set MCTS (see Appendix \ref{sec:ismcts})."
- Latent state: Unobserved components of the environment state that influence dynamics and observations. "a definition of the (possibly latent) state"
- Maximum a posteriori (MAP): The mode of the posterior distribution; the most probable hypothesis given the data. "This lower bound is tightest when is the maximum a posteriori, but is valid for any sample."
- Monte Carlo Tree Search (MCTS): A simulation-based planning algorithm that builds a search tree via randomized rollouts and statistical backing-up of values. "serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS)."
- OpenSpiel: A framework providing standardized game environments and APIs for reinforcement learning research. "Our game environments are based on OpenSpiel~\citep{LanctotEtAl2019OpenSpiel}"
- Out-of-distribution (OOD): Data or tasks that differ from those seen during model training, often used to assess generalization. "including novel (or “OOD”) ones which we create, to avoid contamination issues with the training set of the LLM."
- Partially observable Markov decision process (POMDP): A stochastic control model where the true state is hidden and decisions are made based on observations. "Imperfect information games can be considered a special kind of (multi-agent) partially observable Markov decision process (POMDP)."
- POMCP: Partially Observable Monte Carlo Planning; a Monte Carlo search method for POMDPs using particle filtering in belief space. "related to the POMCP method of \citet{Silver10POMCP}"
- PPO (Proximal Policy Optimization): A policy-gradient reinforcement learning algorithm that stabilizes updates via clipped objectives. "We also tried learning a policy using PPO applied to the (partially observed) CWM: see Appendix \ref{sec:PPO} for details."
- Post-hoc observability: An assumption that hidden variables become revealed after the trajectory, simplifying model learning. "assumes post-hoc observability;"
- ReAct-style methods: Prompting strategies that interleave reasoning steps with actions, often used in tool-augmented LLM agents. "uses ReAct-style methods~\citep{Yao22React} for decision-making."
- Regularized autoencoder: An autoencoder constrained by structural priors (e.g., game rules and APIs) to produce meaningful latent representations. "we introduce a novel paradigm that effectively tasks the LLM with synthesizing a regularized autoencoder"
- Thompson sampling: A Bayesian exploration strategy that samples actions or models according to their posterior probability of being optimal. "and uses Thompson sampling to decide which hypothesis to ask the LLM to improve"
- Ternary-outcome game: A game with three possible results: win, loss, or draw. "All of our perfect information games are ternary-outcome games, so we are limited to win, lose, or draw (W/L/D)."
- Zero-sum game: A strictly competitive game where one player’s gain is exactly another player’s loss. "mixture of ternary-outcome games, zero-sum games and general-sum games"
Collections
Sign up for free to add this paper to one or more collections.

