- The paper introduces Contrastive-SDE, a novel method integrating contrastive learning with SDEs for efficient unpaired image-to-image translation.
- It leverages a U-Net-based architecture and SimCLR framework to extract domain-invariant features, eliminating the need for pre-trained classifiers.
- Experiments on CelebA-HQ and AFHQ datasets show competitive performance with reduced computational cost and faster training convergence.
Contrastive-SDE: Guiding Stochastic Differential Equations with Contrastive Learning for Unpaired Image-to-Image Translation
Introduction
The paper "Contrastive-SDE: Guiding Stochastic Differential Equations with Contrastive Learning for Unpaired Image-to-Image Translation" presents a novel approach combining contrastive learning with stochastic differential equations (SDEs) to address the task of unpaired image-to-image (I2I) translation (2510.03821). Traditional methods such as GANs for unpaired I2I encounter issues like mode collapse, while score-based diffusion models (SBDMs) suffer from slow convergence and complexity in domain adaptation. The authors propose using a time-dependent contrastive learning model aimed at extracting domain-invariant features, thereby overcoming these challenges inherent in existing methodologies. This approach eliminates the need for a pretrained classifier or supervised learning, thus reducing computational overhead and enabling faster convergence.
Methodology
Score-based Diffusion Models (SBDM)
SBDMs leverage stochastic differential equations to progressively transform input images to resemble output distributions. The forward SDE gradually infuses noise into the data, while the reverse SDE seeks to retrieve the noiseless original by estimating the gradient of the data log-density. The authors employ this mechanism to generate domain-consistent images by learning score-based models and efficiently solving the reverse SDE through methods like Euler-Maruyama, integrating contrastive guidance.
Contrastive Learning
Contrastive learning aims to extract features by maximizing similarities between certain image pairs in an embedding space. Specifically, the paper utilizes the SimCLR framework, which forms positive image pairs (e.g., an image and its augmented version) and treats all other images as negative pairs, with a focus on minimizing domain-specific artifacts. The novel aspect of this work is integrating contrastive learning directly with diffusion processes to maintain semantic consistency in the translated images.
Training the Contrastive Model
The proposed approach trains a U-Net-based architecture to learn domain-invariant features via contrastive learning, facilitating the guidance of SDEs. The model architecture includes residual and attention layers (Figure 1), ensuring effective feature extraction and projection into contrastive spaces. The learned representations are used alongside a guidance function during image generation, where positive pairs are treated with specific emphasis on maintaining domain-invariant attributes.
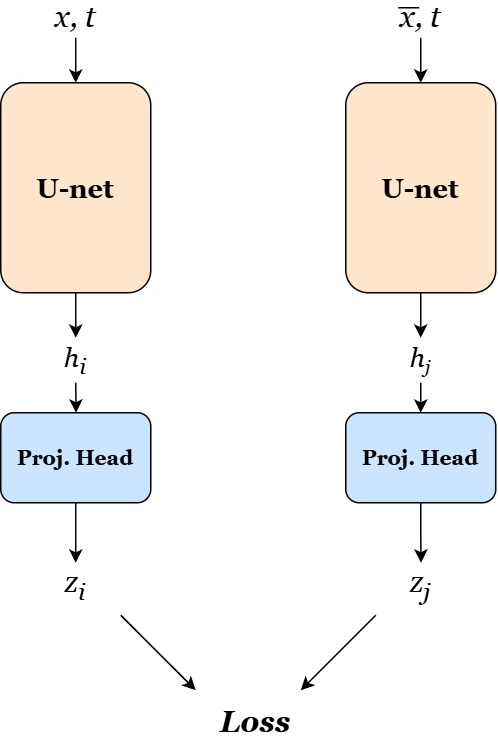
Figure 1: Architecture of the contrastive model for feature extraction and domain-invariant representation.
Guiding Diffusion
The translation process leverages a pre-trained SDE guided by a learned function Q, which encapsulates the contrastive model's output. This function is responsible for preserving domain-invariant elements while eliminating domain specifics throughout the reverse SDE. The guidance mechanism effectively aligns source images with target attributes without additional classifier requirements.
Results and Discussion
Datasets and Evaluation Metrics
The model is evaluated on the CelebA-HQ and AFHQ datasets for tasks such as Cat-Dog and Male-Female translations. Performance is measured using metrics like Fréchet Inception Distance (FID) for realism, and L2, PSNR, and SSIM for faithfulness. Results indicate that Contrastive-SDE attains competitive performance in faithfulness compared to state-of-the-art methods, confirming the method's capability in maintaining domain consistency.
Comparison and Analysis
Contrastive-SDE exhibits lower computational costs and faster convergence than methods requiring extensive classifier training, such as EGSDE. While the FID scores are moderate, the improved training efficacy underlines the model's potential as an alternative to existing approaches, particularly when domain-specific feature extraction is avoided. The use of domain-invariant features decisively reduces the model's complexity without sacrificing the quality of translation.

Figure 2: Qualitative comparison of Contrastive-SDE with several baselines on three I2I translation tasks.
Ablation Study
Ablation studies performed highlight the effects of initial time step choice and similarity score function on model performance. Adjusting these parameters reveals a trade-off between realism and faithfulness, enhancing flexibility depending on application-specific needs.

Figure 3: Comparison of faithfulness with initial time P.
Conclusion
The integration of contrastive learning with SDEs for unpaired I2I translation offers a significant advancement by simplifying the training process and ensuring efficient domain adaptation. This method presents an avenue for future work in extending applications to scenic translations and other complex, unstructured datasets. Further exploration in refining domain-invariant feature extraction could enhance realism without compromising fidelity, setting the stage for broader applicability and improved generative quality in diffusion models.