Best-of-Majority: Minimax-Optimal Strategy for Pass@$k$ Inference Scaling
Published 3 Oct 2025 in cs.LG and stat.ML | (2510.03199v1)
Abstract: LLM inference often generates a batch of candidates for a prompt and selects one via strategies like majority voting or Best-of- N (BoN). For difficult tasks, this single-shot selection often underperforms. Consequently, evaluations commonly report Pass@$k$: the agent may submit up to $k$ responses, and only the best of them is used when computing regret. Motivated by this, we study inference scaling in the more general Pass@$k$ inference setting, and prove that neither majority voting nor BoN exhibits the desirable scaling with $k$ and the sampling budget $N$. Combining the advantages of majority voting and BoN, we propose a new inference strategy called Best-of-Majority (BoM), with a pivotal step that restricts the candidates to the responses with high frequency in the $N$ samples before selecting the top-$k$ rewards. We prove that when the sampling budget is $N=\tilde\Omega(C*)$, the regret of BoM is $O(\epsilon_{\mathrm{opt}}+\sqrt{\epsilon_{\mathrm{RM}}2C*/k})$, where $C*$ is the coverage coefficient, $\epsilon_{\mathrm{RM}}$ is the estimation error of the reward model, and $\epsilon_{\mathrm{opt}}$ is the estimation error of reward at the optimal response. We further establish a matching lower bound, certifying that our algorithm is minimax optimal. Beyond optimality, BoM has a key advantage: unlike majority voting and BoN, its performance does not degrade when increasing $N$. Experimental results of inference on math problems show BoM outperforming both majority voting and BoN.
The paper introduces Best-of-Majority (BoM), a novel algorithm that integrates majority voting and Best-of-N methods to achieve minimax optimal performance in Pass@$k$ inference.
The approach leverages frequent candidate selection and a reward model, with theoretical regret bounds tied to the coverage coefficient and reward model error.
Experimental results on datasets like GSM8K, MATH-500, and AIME24 confirm that BoM consistently outperforms baselines while maintaining robust scaling with increased sample sizes.
Best-of-Majority: Minimax-Optimal Strategy for Pass@k Inference Scaling
Introduction
The authors introduce a novel inference strategy called Best-of-Majority (BoM) for Pass@k inference settings, aimed at addressing the weaknesses of existing strategies such as majority voting and Best-of-N (BoN). The paper highlights that neither majority voting nor BoN exhibits scaling desirable with respect to k and the sampling budget N. The BoM algorithm combines elements of both strategies, leveraging frequent candidate responses before refining selection with a reward model.
Algorithm and Theoretical Foundations
BoM addresses the inadequacies in existing inference methods by integrating insights from both majority voting and BoN. The strategy restricts the candidate set to those responses appearing with sufficient frequency, thus ensuring high likelihood of correctness before invoking the reward model for selection. This integration allows for minimax optimal performance, as demonstrated through theoretical bounds providing convergence guarantees.
The regret for BoM is formulated as O(ϵopt+ϵRM2C∗/k), with C∗ as the coverage coefficient and ϵRM being the estimation error of the reward model. BoM showcases scaling monotonicity, excelling unlike its counterparts by ensuring that performance does not deteriorate as N scales up.
Experimental Results
Experimental validations on math problem datasets like GSM8K, MATH-500, and AIME24 confirm BoM's consistent superiority over baseline methods.
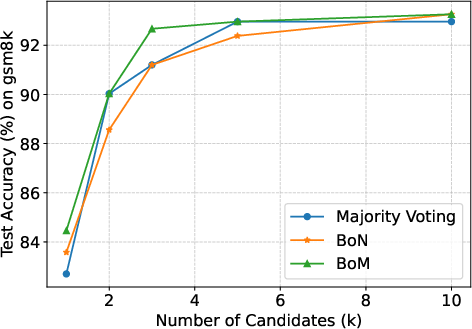
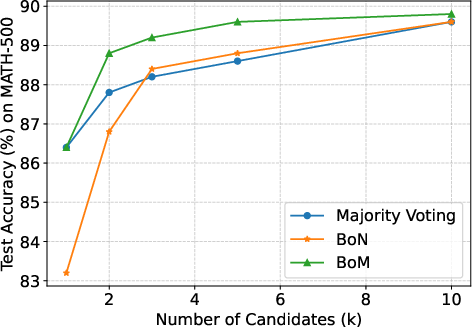
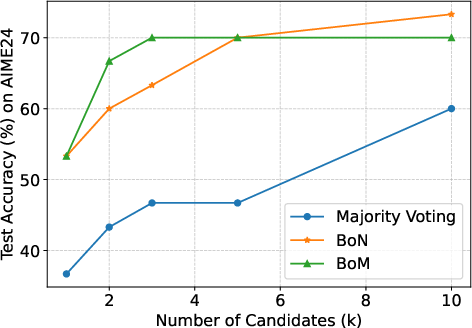
Figure 1: Results with different k on Qwen3-4B. BoM consistently outperforms the baselines on MATH-500 for all k and on AIME24, GSM8K when k is small, and matches the performance of baselines in other settings.
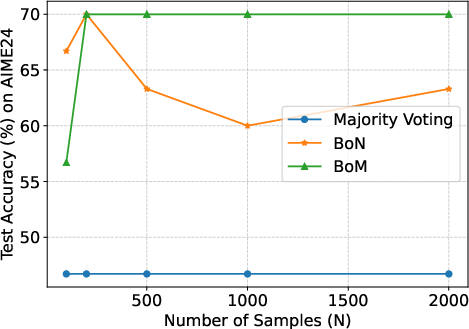
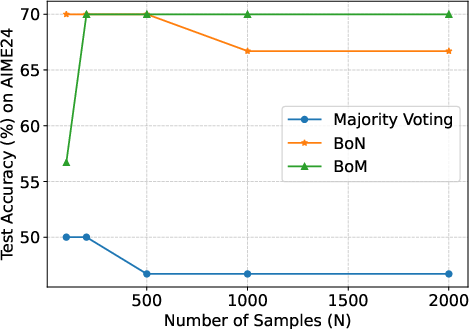
A detailed comparison illustrates BoM's robustness across varying values of k and N, affirming its theoretical underpinnings. Notably, BoM outperforms both majority voting and BoN in maintaining high final scores without succumbing to performance degradation as N increases.
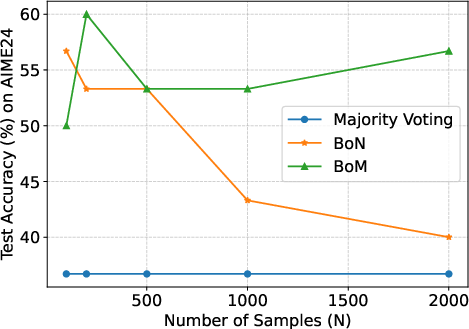
Figure 2: The results with fixed k and different N. When N increases, the performance of BoN is likely to decrease over all the k. The performance of Majority voting remains at a low level. Among them, BoM has a more consistent performance and outperforms baselines with larger N.
Implications and Future Work
The incorporation of both majority voting and BoN dimensions allows BoM to achieve minimax optimality, representing a strategic advancement in LLM inference scaling. Furthermore, its demonstration of scaling monotonicity opens pathways to leveraging larger computational budgets (N) without adverse effects, ensuring computational efficiency when expanding sample sizes.
Future research can extend this work by exploring additional dimensions where inference strategies interlace with post-training model behaviors, potentially enhancing LLM versatility further.
Conclusion
The paper "Best-of-Majority: Minimax-Optimal Strategy for Pass@k Inference Scaling" presents a significant stride in refining inference strategies for LLMs. BoM, through its hybrid approach and robust theoretical as well as practical validations, sets a new standard ensuring optimal performance in complex inference scenarios.