- The paper presents a pipeline combining multi-view diffusion with dual-branch NeRF conditioning for interactive, feed-forward 3D object relighting.
- It achieves state-of-the-art results on synthetic and real-world benchmarks by delivering high PSNR, SSIM, and LPIPS metrics alongside fast rendering speeds.
- The approach eliminates per-illumination optimization and generalizes to unseen lighting, highlighting its potential for AR/VR and content creation applications.
ROGR: Relightable 3D Objects using Generative Relighting
Overview and Motivation
ROGR presents a method for reconstructing relightable 3D object models from multi-view images under unknown illumination, enabling rendering under arbitrary novel environment maps without further optimization. The approach leverages a generative multi-view diffusion model to synthesize consistent relit images, which are then distilled into a lighting-conditioned Neural Radiance Field (NeRF). This pipeline addresses the limitations of prior inverse rendering and single-view relighting methods, which either require per-illumination optimization or suffer from view inconsistency.

Figure 1: ROGR reconstructs a relightable neural radiance field from posed images under unknown illumination, supporting on-the-fly relighting and novel view synthesis.
Methodology
Multi-View Relighting Diffusion Model
The first stage employs a multi-view diffusion model to generate view-consistent relit images for a given object under a set of environment maps. The model is based on latent diffusion, with inputs comprising image latents, camera raymaps, and HDR/LDR environment map latents, all aligned to the camera pose. The architecture adapts CAT3D with 2D UNet and 3D attention layers to facilitate cross-view information exchange.

Figure 2: The multi-view relighting diffusion model generates consistent relit images from posed inputs and environment maps, forming a multi-illumination dataset.
This process is repeated across M environment maps, yielding N×M relit images per object, which serve as training data for the subsequent NeRF.
Lighting-Conditioned Relightable NeRF
The relightable NeRF is trained on the multi-illumination dataset to predict view-dependent color conditioned on arbitrary environment maps. The architecture extends NeRF-Casting, introducing dual-branch conditioning:
- General Conditioning: Encodes the full environment map via a transformer encoder, providing low-frequency illumination cues.
- Specular Conditioning: Samples and blurs the environment map at the specular reflection direction using multiple Gaussian kernels, capturing high-frequency specularities.
These conditioning signals are concatenated with NeRF-Casting's feature vector for each ray, enabling the model to synthesize both diffuse and specular effects under novel lighting.
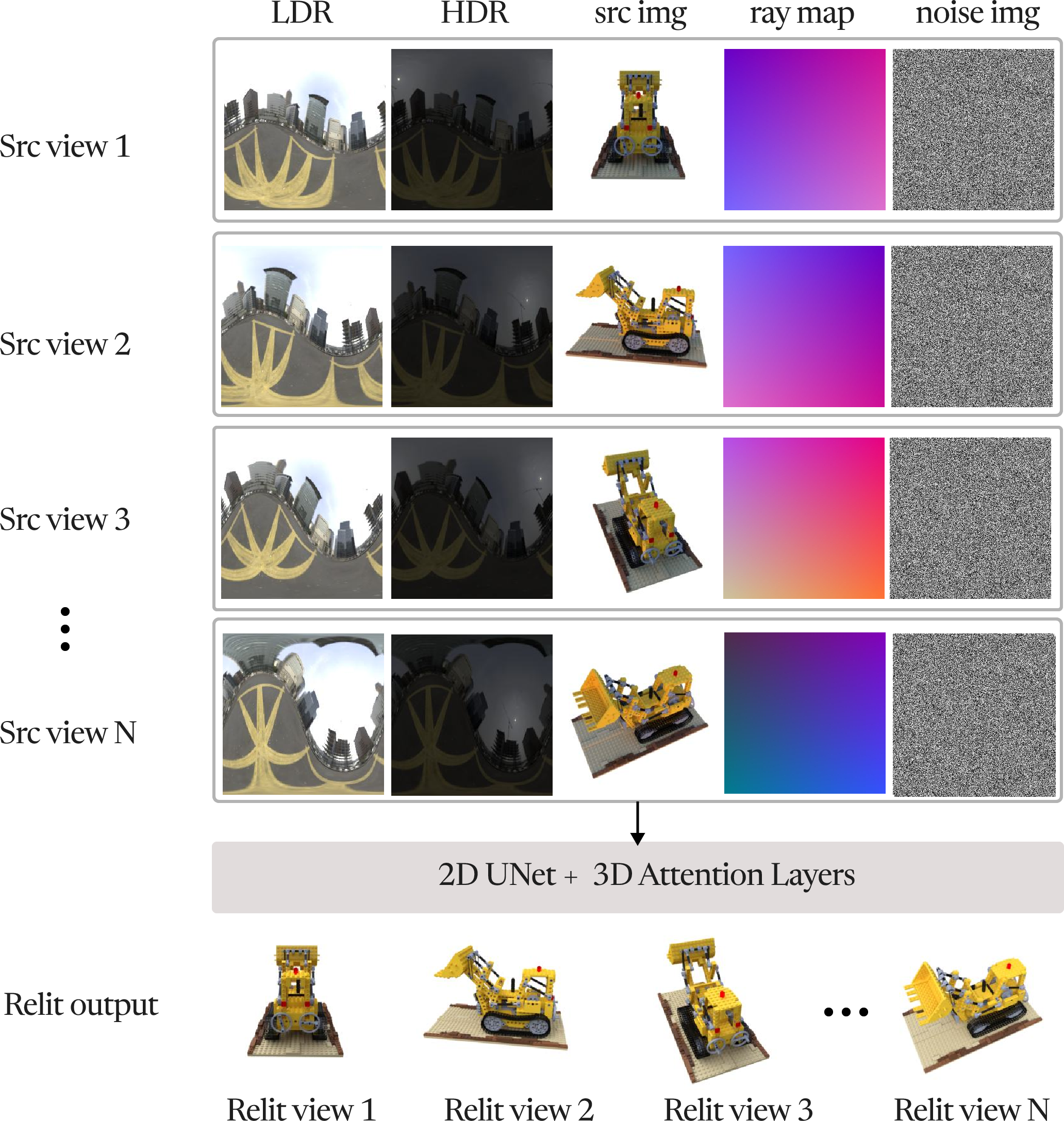
Figure 3: Multi-view relighting diffusion model architecture, with 2D UNet and 3D attention layers for cross-view consistency.

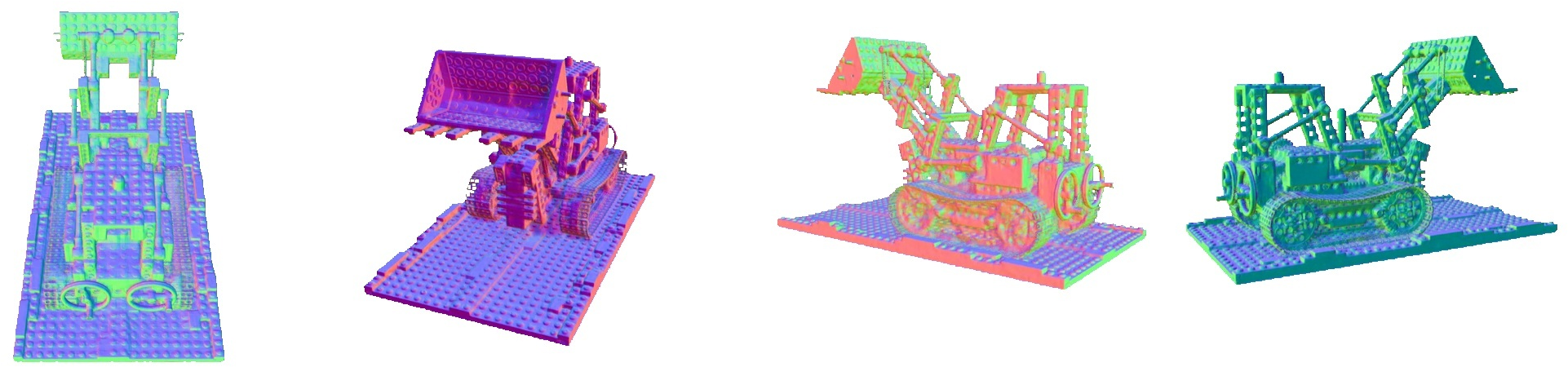
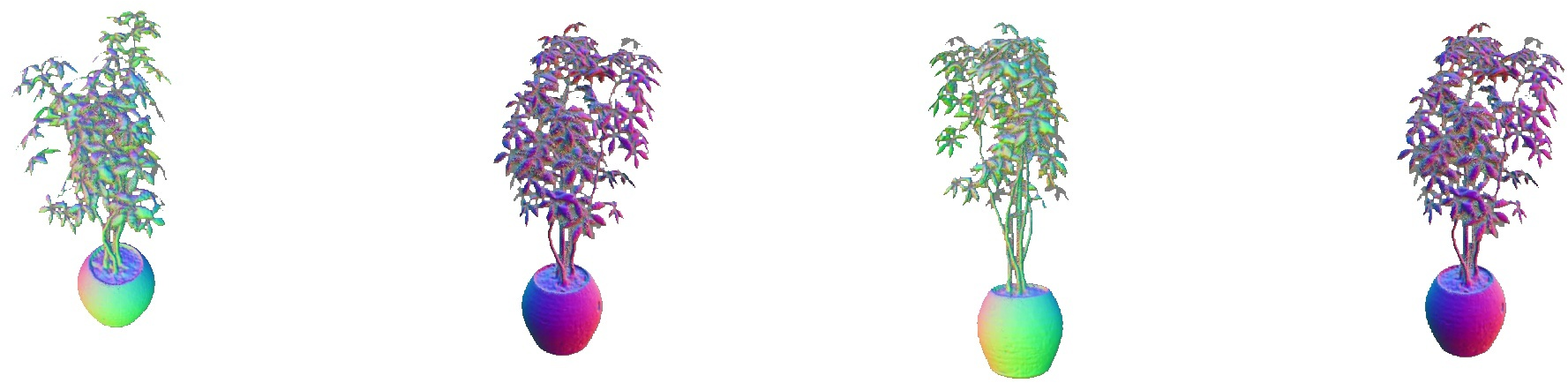
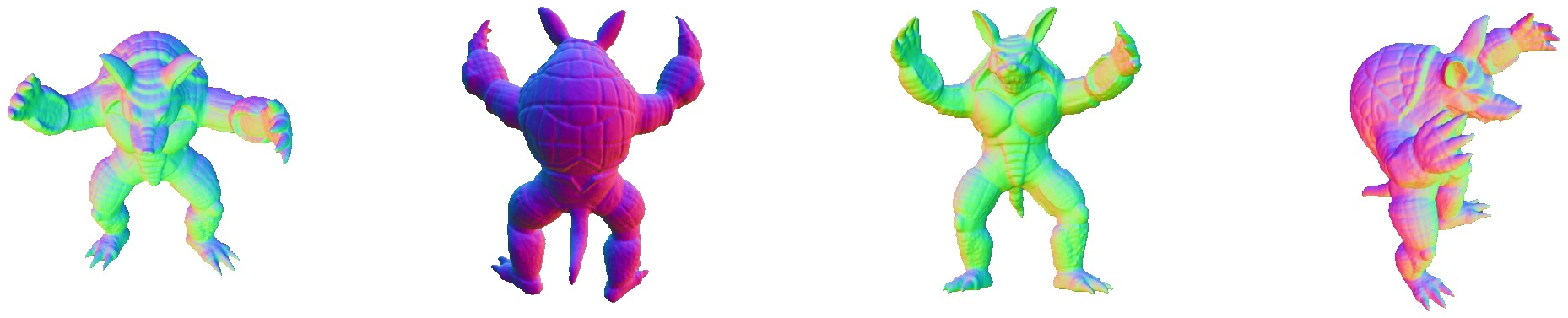
Figure 4: Normal map rendering of relightable NeRFs on TensoIR objects, demonstrating geometric fidelity.
Experimental Results
Benchmarks and Quantitative Evaluation
ROGR is evaluated on the TensoIR (synthetic) and Stanford-ORB (real-world) datasets, outperforming state-of-the-art baselines in most metrics:
- TensoIR: Achieves top PSNR (30.74), SSIM (0.950), and LPIPS (0.069), with interactive rendering speed (0.384s/frame).
- Stanford-ORB: Delivers best PSNR-H (26.21) and SSIM (0.980), and second-best PSNR-L (32.91) and LPIPS (0.027).

Figure 5: Qualitative comparisons on TensoIR, showing superior specular highlight and color fidelity.

Figure 6: Qualitative comparisons on Stanford-ORB, with high-fidelity specular reflections.
Qualitative Analysis
ROGR demonstrates robust relighting of complex real-world objects, accurately reproducing specularities and shadows across diverse materials. The method generalizes to unseen lighting conditions without retraining, a significant advantage over prior approaches.
Ablation Studies
Ablations reveal the necessity of both general and specular conditioning. Removing general conditioning or replacing it with per-image embeddings severely degrades performance and generalization. Lower environment map resolutions blur specular highlights and introduce artifacts. Increasing the number of views and environment maps during training improves consistency and relighting quality, with performance saturating beyond 111 environment maps.


Figure 7: Ablation studies illustrating the impact of conditioning signals and environment map resolution on relighting quality.
Implementation Details
- Multi-View Diffusion: Trained on 400k synthetic objects, 64 views × 16 illuminations, using 128 TPU v5 chips.
- NeRF Training: Conducted on 8 H100 GPUs for 500k steps, with environment maps at 512×512 resolution and multi-scale specular conditioning.
- Inference: Feed-forward relighting at interactive speeds, supporting arbitrary novel environment maps.
Limitations
ROGR is currently limited to object-centric scenes and does not model subsurface scattering, refraction, or volumetric effects. The use of environment maps assumes distant illumination, which may not capture near-field lighting phenomena. Extending the approach to large-scale scene relighting and more complex material models remains an open direction.
Implications and Future Directions
ROGR advances practical 3D object relighting by enabling efficient, generalizable feed-forward rendering under arbitrary illumination. This has direct applications in graphics, AR/VR, and content creation pipelines, reducing the need for labor-intensive inverse rendering or per-lighting optimization. Future work may focus on expanding material diversity, supporting near-field lighting, and scaling to scene-level relighting.
Conclusion
ROGR introduces a pipeline for reconstructing relightable 3D objects using generative multi-view diffusion and lighting-conditioned NeRFs. The method achieves state-of-the-art performance on synthetic and real-world benchmarks, supporting interactive, high-fidelity relighting under novel environment maps. Its dual-branch conditioning architecture is critical for capturing both diffuse and specular effects, and the approach generalizes efficiently to unseen lighting conditions. ROGR represents a significant step toward practical, scalable 3D relighting in graphics and vision applications.