- The paper introduces minimal-dissipation learning, linking thermodynamic principles to improved training efficiency in persistent chain EBMs.
- It demonstrates that employing quasi-static and discontinuous protocols minimizes excess work and mitigates biases in approximate MLE objectives.
- The study establishes a framework for optimizing learning rates via natural gradient flows and stochastic thermodynamics, enhancing energy efficiency.
Minimal-Dissipation Learning for Energy-Based Models
Introduction
The study explores the intriguing intersection of machine learning and thermodynamics, particularly focusing on energy-based models (EBMs). EBMs, inspired by statistical physics, encompass various machine learning architectures including the Hopfield network and Boltzmann machines. These frameworks connect machine learning methodologies with thermodynamic quantities, such as entropy production, which can determine computational energy requirements akin to Landauer's principle. The research primarily investigates the minimization of energy dissipation—termed minimal-dissipation learning—during the training of a specific EBM class: persistent chain EBMs. Through this study, a theoretical foundation is developed for training generative models with minimal thermodynamic excess work, which directly correlates to biases in approximate maximum-likelihood estimation (MLE) objectives.
Theory of Energy-Based Models
Energy-based models are defined by an energy function E(x,θ), linking samples to the Boltzmann distribution. The challenge arises due to the intractable normalization factor, or partition function, involved in computing probabilities. Training such models requires approximating gradients through methods like Markov chain Monte Carlo (MCMC), typically constrained by computational infeasibility when requiring convergence. Persistent chain EBMs utilize a continuous storage and update approach within a replay buffer to maintain convergence with the Gibbs distribution, setting a foundational framework for further explorations into optimizing training via thermodynamic insights.
Thermodynamic Perspective on EBM Training
The relationship between MLE bias and thermodynamic excess work allows EBM training to be considered within the framework of stochastic thermodynamics. Specifically, persistent chain EBMs enable dynamic connections to be drawn where minimizing work dissipation aligns with optimizing computational efficiency.
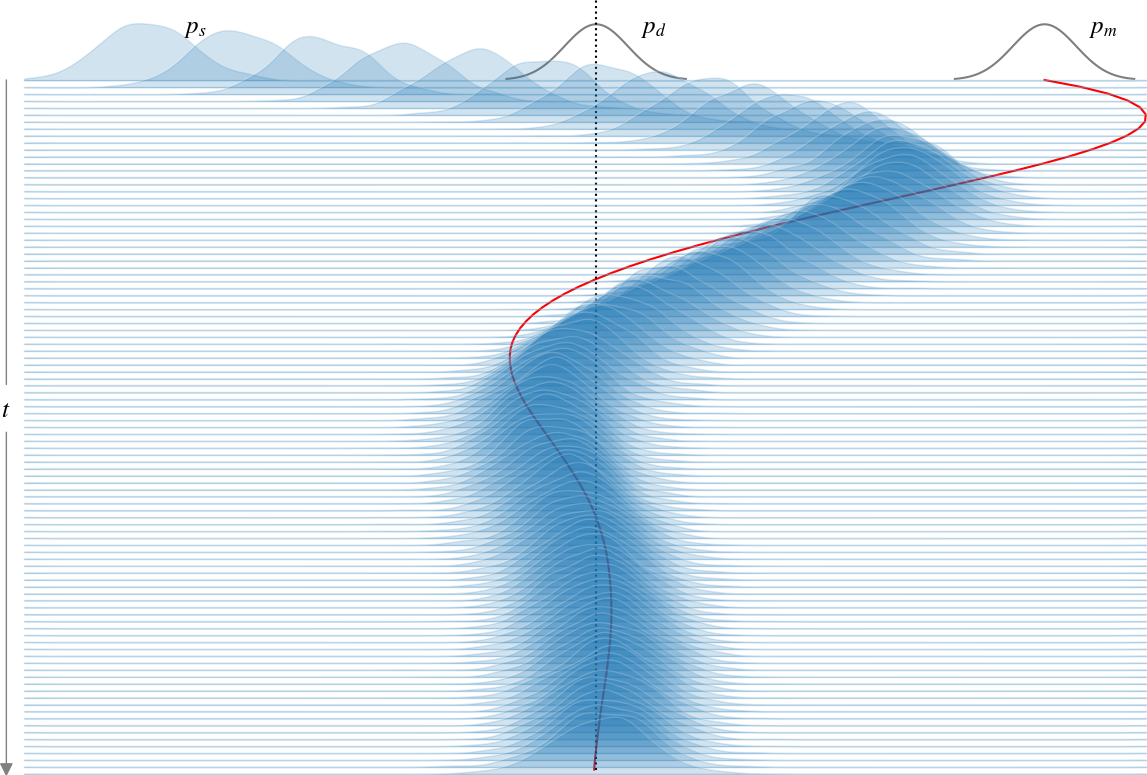
Figure 1: The harmonic trap EBM is trained with a constant learning rate using the approximate MLE objective. The sample distribution, ps, evolves according to Langevin dynamics, while the model distribution pm is updated according to the MLE gradient flow.
To achieve minimal-dissipation learning, this work primarily examines the harmonic trap—a personified EBM to elucidate the process. The harmonic trap's dynamics reveal oscillation inefficiencies during training (Figure 1), leading to further analysis on minimizing these inefficiencies by slowing down learning rates quasi-statically, as portrayed in Figure 2.
Practical Implications and Protocols
The quest for minimal excess work extends beyond continuous protocols to include discontinuous methods, where traditional thermodynamic approaches, like those of Schmiedl and Seifert, are applied. The study demonstrates that genuine learning of unknown parameters is feasible when initializing the system in equilibrium, and employing discontinuous training protocols.
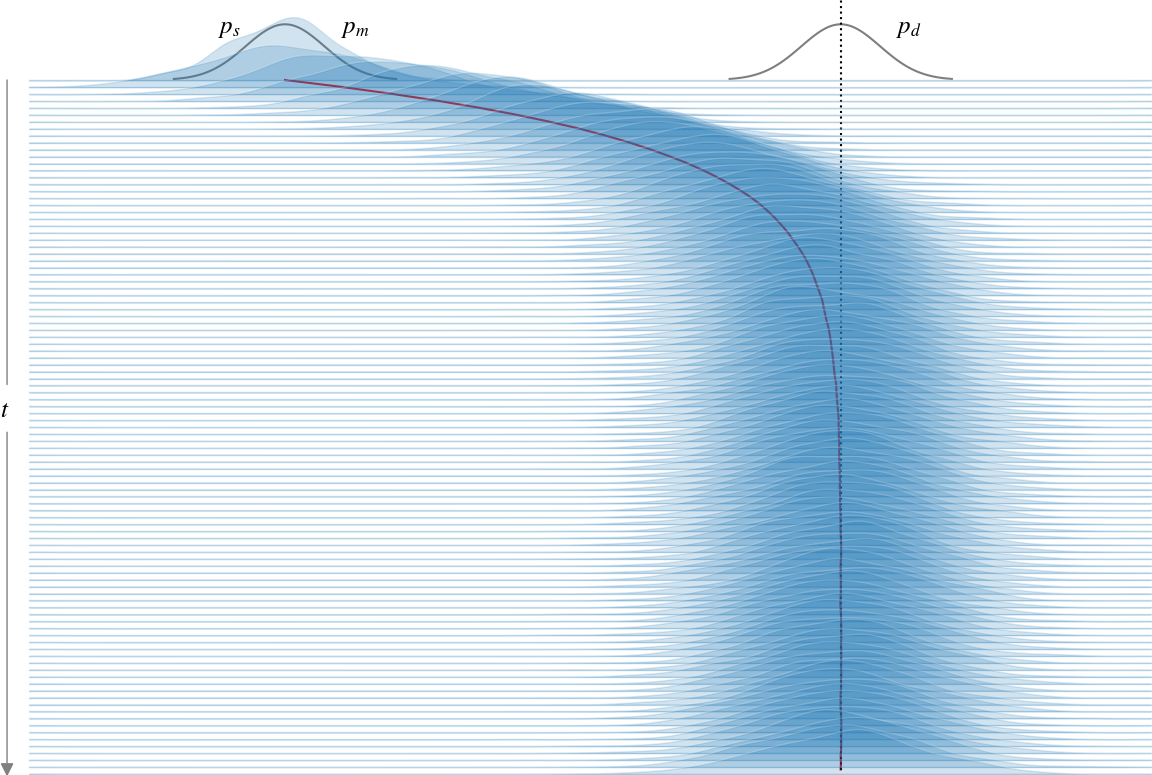
Figure 2: The harmonic trap EBM is trained using the approximate MLE objective with a quasi-static protocol, maintaining ps≈pm throughout training.
These protocols reveal that careful learning rate scheduling—derived from thermodynamic metrics—can guide learning processes close to theoretical energy-efficiency limits (Figure 3). When compared with quasi-static processes, optimal protocols exhibit a superior ability to minimize excess work.

Figure 3: The harmonic trap EBM is trained with minimal entropy production using a continuous protocol, yet does not strictly learn θ∗, as prior knowledge of θ∗ is required.
Generalization and Future Directions
A general framework for scheduling learning rates across general potentials involves utilizing natural gradient flows, which link stochastic thermodynamics with information geometry—achieving a novel harmony in minimizing training dissipation. Although initially tailored for systems like the harmonic trap, the learning schedule's application to broader EBM classes signifies a potential upsurge in computational efficiency alongside reduced energy expenditure.
Conclusion
This research substantiates that EBMs can be trained in a manner compliant with minimal thermodynamic excess work, broadening the scope of machine learning frameworks. The findings advocate for leveraging thermodynamic principles to inform hyperparameters like learning rates, contributing to both energy efficiency and advanced methodological developments within the field of persistent chain EBMs. Progress in analog computing combined with these protocols suggests a promising future for designing computational architectures centered around stochastic thermodynamics.
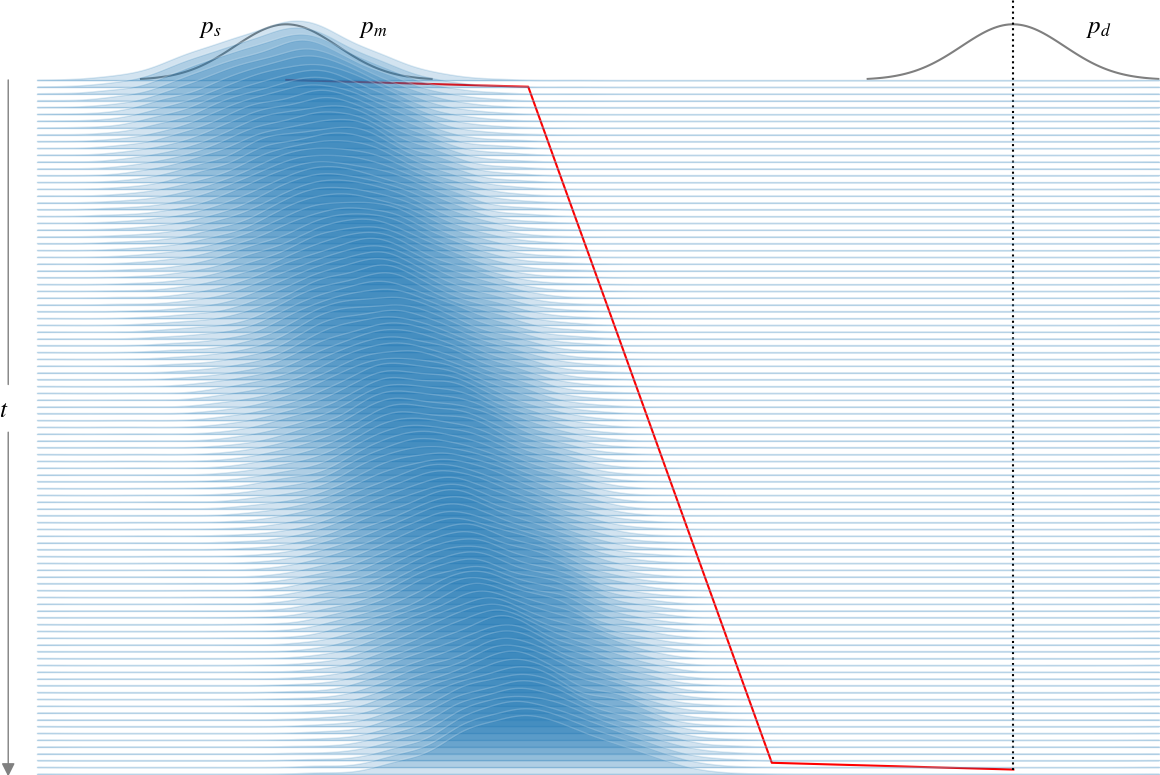
Figure 4: The harmonic trap EBM with minimal excess work using a discontinuous protocol allows for learning without prior knowledge of θ∗, by initializing in equilibrium.