- The paper introduces a dual-branch diffusion model that leverages explicit 3D geometric guidance through projected point clouds to ensure robust image completion.
- It employs a target-aware masking strategy and joint self-attention to effectively fuse geometric cues with visual content, mitigating challenges like occlusion and viewpoint variation.
- Experimental results demonstrate a 17.1% PSNR improvement and superior geometric consistency compared to existing methods, validating its effectiveness in reference-driven image editing.
Geometry-Aware Diffusion for Reference-Driven Image Completion: GeoComplete
Introduction
GeoComplete introduces a geometry-aware framework for reference-driven image completion, addressing the limitations of prior generative and geometry-based methods. The approach leverages explicit 3D structural guidance via projected point clouds and a dual-branch diffusion architecture, enabling robust synthesis of missing regions with strong geometric consistency. The method is designed to overcome challenges posed by viewpoint variation, occlusion, dynamic content, and camera settings, which often lead to misaligned or implausible completions in existing approaches.
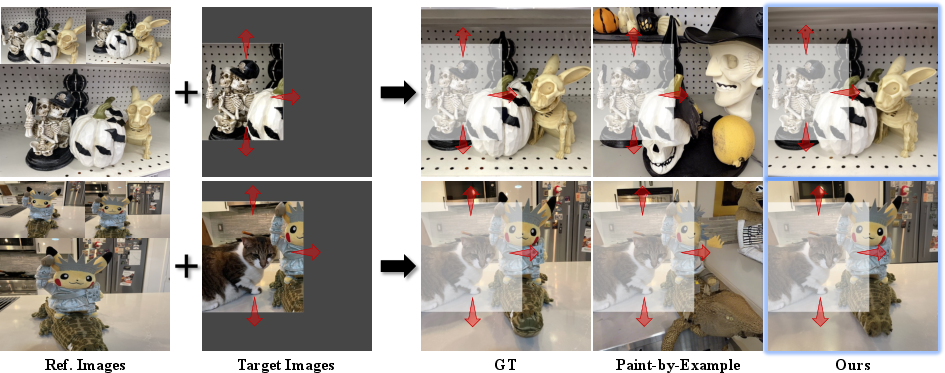
Figure 1: GeoComplete completes missing regions in a target image using reference images, preserving geometric consistency more effectively than Paint-by-Example.
Methodology
Point Cloud Generation
GeoComplete's pipeline begins with point cloud generation from reference and target images. The Visual Geometry Grounded Transformer (VGGT) predicts camera parameters and depth maps in a single forward pass, avoiding error accumulation typical of multi-stage geometry pipelines. To mitigate degradation in dynamic scenes, LangSAM segments and removes dynamic regions using text prompts, which can be user-provided or generated by an LLM. This ensures that geometry estimation focuses on static content, yielding reliable 3D attributes.
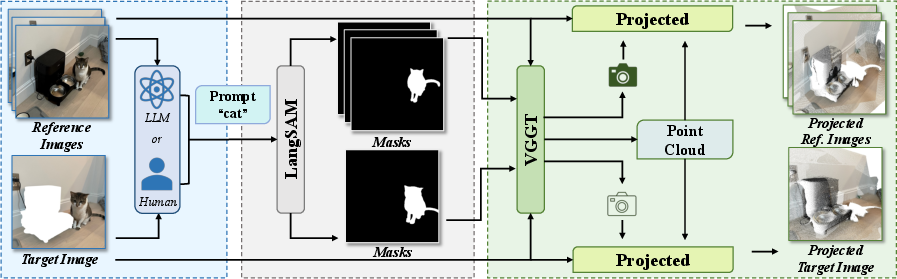
Figure 2: Point cloud generation pipeline: LangSAM segments dynamic objects, VGGT estimates geometry, and the resulting point cloud is projected onto target and reference views.
Dual-Branch Diffusion Architecture
The core of GeoComplete is a dual-branch diffusion model. The target branch encodes the masked target image, while the cloud branch encodes the projected point cloud. Both branches are processed in parallel, and joint self-attention fuses their latent features, allowing geometric cues to guide synthesis. The attention mask is constructed to ensure that masked tokens in the target branch can attend to corresponding cloud-branch tokens, facilitating direct geometric guidance even when visual information is absent.
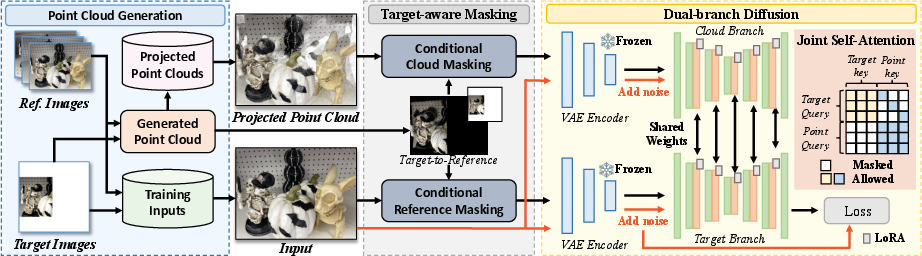
Figure 3: GeoComplete framework overview: point cloud construction, target-aware masking, and dual-branch diffusion with joint self-attention for geometry-guided synthesis.
Target-Aware Masking
GeoComplete introduces a target-aware masking strategy during training. Informative regions—areas visible in references but missing in the target—are identified via 3D projection. Conditional reference masking randomly occludes these regions in the reference images, while conditional cloud masking applies random padding to redundant regions in the projected point cloud. This encourages the model to learn from complementary content and prevents over-reliance on potentially inaccurate geometry.
Experimental Results
Quantitative Evaluation
GeoComplete is evaluated on RealBench and QualBench, challenging datasets with significant viewpoint and appearance variation. The method achieves a 17.1% PSNR improvement over state-of-the-art methods, with substantial gains in SSIM, LPIPS, DreamSim, DINO, and CLIP metrics. User studies confirm superior realism, geometric consistency, and visual coherence.
Qualitative Analysis
GeoComplete consistently reconstructs fine details and maintains scene-level alignment, outperforming generative baselines such as RealFill and Paint-by-Example, which often hallucinate or misalign content due to lack of explicit geometry.

Figure 4: Qualitative comparison: GeoComplete synthesizes missing regions with superior geometric consistency compared to TransFill, RealFill, and Paint-by-Example.

Figure 5: Additional qualitative results: GeoComplete preserves spatial alignment and fine details under large viewpoint changes.
Ablation and Robustness
Ablation studies demonstrate that removing geometric guidance, joint self-attention, or target-aware masking leads to significant drops in all metrics. Robustness experiments show that conditional cloud masking and joint self-attention mitigate the impact of noisy or sparse point clouds and segmentation errors, maintaining strong performance even under degraded upstream predictions.
Implementation Considerations
GeoComplete is implemented atop Stable Diffusion 2 Inpainting, fine-tuned per scene using LoRA with a rank of 8. The pipeline requires VGGT and LangSAM for geometry and segmentation, with preprocessing overhead under 30 seconds per scene. Training for 2,000 steps (72 minutes on four 24GB GPUs) yields optimal results, but promising reconstructions are achieved within 500 steps (18 minutes), outperforming RealFill at equivalent steps.
Resource Requirements
- Four NVIDIA GPUs (24GB each) for training and inference
- VGGT and LangSAM for geometry and segmentation
- Per-scene fine-tuning (batch size 16, 2,000 steps)
- Preprocessing: <30s per scene
Limitations
Completion quality depends on the accuracy of geometry estimation and the visual quality of reference images. Degradations such as rain, haze, or low-light conditions can adversely affect both geometry and appearance guidance. Conditional cloud masking mitigates, but does not eliminate, the impact of inaccurate point clouds.
Implications and Future Directions
GeoComplete demonstrates that explicit 3D geometric priors are critical for spatially consistent image completion in complex scenes. The dual-branch diffusion architecture and target-aware masking provide a unified solution for leveraging both visual and geometric cues. The framework's robustness to upstream errors and its superior performance suggest that geometry-aware generative models will be central to future advances in reference-driven image editing, occlusion removal, and scene understanding.
Potential future developments include:
- Pre-training LoRA parameters on large-scale datasets for faster per-scene adaptation
- Integration of degradation-robust priors or restoration modules to handle adverse conditions
- Extension to video completion and multi-modal scene synthesis
Conclusion
GeoComplete sets a new standard for reference-driven image completion by explicitly conditioning generative diffusion models on projected 3D geometry and employing a dual-branch architecture with joint self-attention. The method achieves substantial improvements in geometric consistency and perceptual quality over prior approaches, with demonstrated robustness to upstream errors. These results underscore the importance of geometry-aware conditioning in generative models and open avenues for further research in spatially consistent image and scene synthesis.

