- The paper demonstrates that common correctness functions like ROUGE and BLEU yield inconsistent and biased UE evaluations in NLG.
- The paper introduces SP-MoJI, a method that marginalizes over multiple LLM-as-a-judge models to reduce uncertainty bias.
- The paper proposes an Elo rating-based aggregation framework to robustly compare NLG uncertainty estimation methods across varied tasks.
Addressing Pitfalls in the Evaluation of Uncertainty Estimation Methods for Natural Language Generation
Introduction
This paper systematically analyzes the evaluation protocols for uncertainty estimation (UE) in natural language generation (NLG), with a focus on the detection of confabulations—hallucinated outputs arising from predictive uncertainty in LLMs. The authors identify critical weaknesses in current evaluation practices, particularly the reliance on approximate correctness functions (e.g., ROUGE, BLEU, LLM-as-a-judge) and the lack of marginalization over these correctness functions. They propose robust alternatives, including structured tasks with exact correctness, out-of-distribution (OOD) and perturbation detection, and introduce an Elo rating-based aggregation for more objective comparison of UE methods.
Pitfalls in Current Evaluation Protocols
The standard evaluation of NLG UE methods is dominated by selective prediction on QA datasets, where correctness is assessed using approximate metrics such as ROUGE, BLEU, or LLM-as-a-judge. The paper demonstrates that these correctness functions exhibit substantial disagreement, both in binary correctness assignment and in the ranking of UE methods.
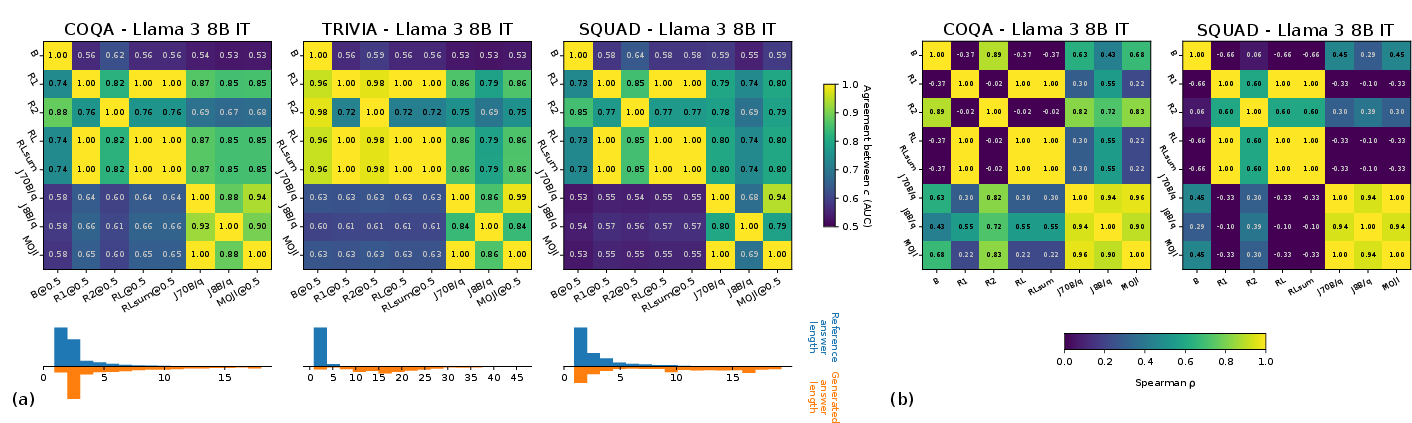
Figure 1: Approximate correctness consistency on selected QA datasets. R indicates ROUGE family, B - BLEU. Judge models are indicated with J, 'q' stands for QA prompt.
The analysis reveals that n-gram-based metrics (ROUGE, BLEU) and LLM-as-a-judge models often disagree, especially due to the short length and ambiguity of reference answers in QA datasets. This disagreement propagates to the ranking of UE methods, leading to inconsistent and potentially misleading conclusions about method performance. The authors further show that the choice of correctness function can be adversarially selected to inflate the apparent performance of certain UE methods, a phenomenon they term "correctness-hacking."
Theoretical analysis in the paper quantifies the impact of label noise and bias on AUROC-based risk correlation experiments. Random label noise uniformly degrades AUROC, while systematic bias in correctness functions can arbitrarily distort the ranking of UE methods, especially when the bias is sample-dependent.
Robust Risk Indicators and Improved Evaluation
To address these pitfalls, the authors propose several remedies:
- Exact Correctness on Structured Tasks: For tasks such as code generation or constrained text generation, correctness can be determined non-parametrically (e.g., via unit tests or symbolic verification), eliminating the need for approximate correctness functions and their associated biases.
- Marginalization over Approximate Correctness (SP-MoJI): For tasks where exact correctness is infeasible, the authors introduce Selective Prediction using Mixture of Judges and Instructions (SP-MoJI). This approach averages risk correlation metrics over multiple LLM-as-a-judge variants (different models, prompts, and sampling temperatures), thereby reducing both aleatoric and epistemic uncertainty in correctness labeling.
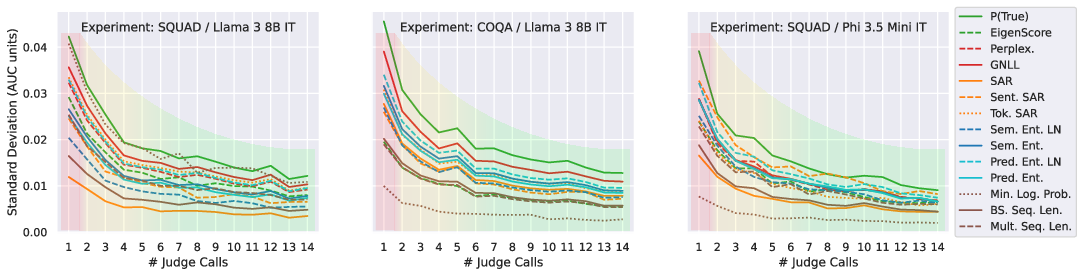
Figure 2: Bootstrap estimate of the standard deviation of mean of AUC performance on selected QA dataset/model combinations. Using SP-MoJI with 4 judges reduces the standard deviation of the performance estimator twofold.
Empirical results show that using an ensemble of 4 judges already halves the standard deviation of performance estimates, and further increases in ensemble size yield diminishing returns.
- OOD and Perturbation Detection: The authors advocate for the inclusion of OOD and perturbation detection tasks, where risk indicators are more robust and less susceptible to the ambiguities of approximate correctness. OOD datasets (e.g., SQuADv2, Known-Unknowns) and controlled perturbations (e.g., word shuffling) provide alternative axes for evaluating the sensitivity of UE methods to distributional shifts and input corruptions.
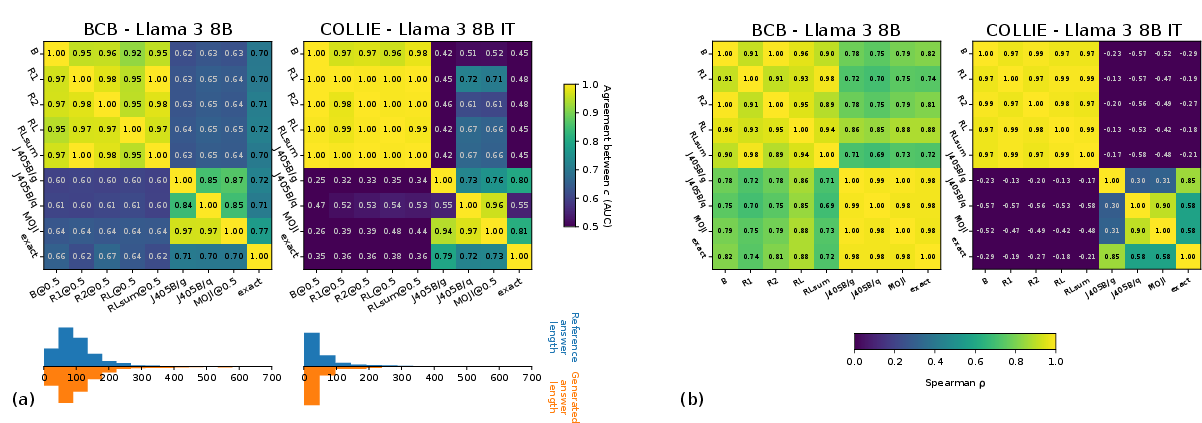
Figure 3: Correctness consistency on structured datasets. R indicates ROUGE family, B - BLEU. Judge models are indicated with J, 'q' stands for QA prompt.
On structured tasks, approximate correctness functions (including LLM-as-a-judge) often fail to match the exact ranking of UE methods, especially when semantic equivalence is not captured by surface-level similarity.
Aggregation via Elo Rating
Given the variability and sometimes contradictory results across datasets, models, and correctness functions, the paper introduces Elo rating as an aggregation mechanism for UE method comparison. Each dataset/model/risk-indicator combination is treated as a "game" between two methods, with Elo updates reflecting relative performance. This approach enables probabilistic interpretability, indirect comparisons across partially overlapping experimental suites, and robust aggregation over heterogeneous tasks.
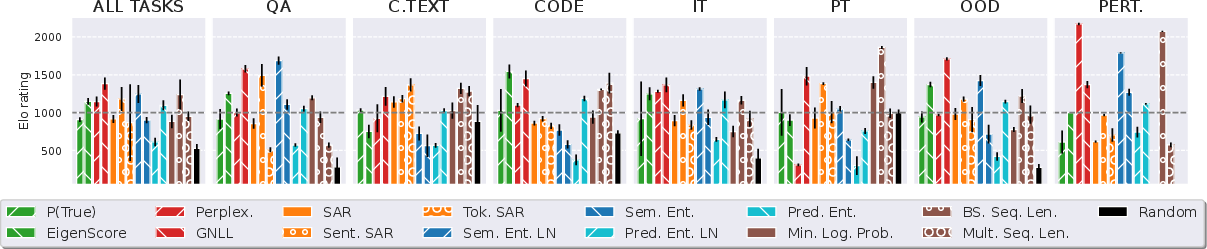
Figure 4: Elo ratings of NLG uncertainty estimation methods. Methods are grouped by color according to their category. The line at 1000 Elo indicates the average rating.
The Elo-based aggregation reveals that no single UE method dominates across all tasks. Simple heuristics (e.g., sequence length, G-NLL) are competitive outside the QA domain, and method preference is highly task-dependent. Notably, length normalization is generally detrimental except in perturbation detection, and semantic entropy methods that ignore sequence likelihoods can outperform more complex approaches in certain settings.
Empirical and Theoretical Implications
The findings have several implications:
- Evaluation Instability: The lack of marginalization over correctness functions and the use of ambiguous QA datasets introduce significant instability and bias in UE method evaluation. This undermines the reliability of reported results and can be exploited to "hack" benchmarks.
- Task-Dependence: The performance of UE methods is highly sensitive to the nature of the task and the risk indicator. There is no universally superior method; evaluation must be contextualized.
- Aggregation Necessity: Elo rating provides a principled way to aggregate heterogeneous results, mitigating the risk of cherry-picking and enabling more robust conclusions.
- Resource Considerations: The computational overhead of SP-MoJI is modest, as judge model evaluations are short and can be parallelized. The overall experimental suite required approximately 600 GPU-hours for generation and uncertainty computation, with judge evaluations adding negligible cost.
Limitations and Future Directions
The paper highlights several open challenges:
- Judge Model Bias: Even large LLM-as-a-judge models can exhibit biases and inconsistencies, especially when prompts are not carefully adapted to the task (e.g., structured generation).
- OOD Dataset Construction: Creating realistic OOD datasets for text remains non-trivial, and current benchmarks may not fully capture the spectrum of distributional shifts encountered in practice.
- Active Learning Evaluation: The extension of these evaluation protocols to active learning scenarios is left for future work, as is the analysis of rank correlation metrics beyond AUROC.
Conclusion
This work provides a rigorous critique of prevailing evaluation practices for uncertainty estimation in NLG, demonstrating that current protocols are vulnerable to bias, instability, and manipulation. By introducing robust risk indicators, advocating for marginalization over correctness functions, and proposing Elo-based aggregation, the authors offer a comprehensive framework for more reliable and interpretable evaluation of UE methods. The results underscore the necessity of task-aware, statistically principled evaluation and suggest that future progress in NLG UE will depend as much on improved evaluation methodology as on novel algorithmic advances.

