- The paper introduces a conditional diffusion model that fuses 3D point clouds, 2D images, and RF-specific data for precise RF heatmap prediction.
- The paper demonstrates significant improvements in accuracy and speed, reducing median RSSI error by up to 77% and achieving up to 33× inference speedup.
- The paper validates its approach in real-world scenarios, showing robustness to missing data and dynamic changes for practical wireless deployments.
Diffusion2: Generative Diffusion Models for RF Heatmap Prediction in 3D Environments
Introduction and Motivation
Diffusion2 introduces a generative diffusion model for predicting radio frequency (RF) signal heatmaps in complex 3D environments. The motivation is to overcome the limitations of traditional ray-tracing and ML-based approaches, which either require extensive material information and are computationally expensive, or demand large volumes of pre-measured data and retraining for environmental changes. By leveraging 3D point clouds, minimal RF measurements, and a multi-modal conditioning mechanism, Diffusion2 aims to provide accurate, efficient, and generalizable RF heatmap predictions across a wide frequency range, including Wi-Fi and mmWave bands.
Model Architecture
Diffusion2 is built upon a conditional diffusion framework, where the denoising process is guided by a rich, multi-modal condition vector derived from the environment. The architecture consists of two key components:
- RF-3D Encoder: Extracts hierarchical features from 3D point clouds (using MinkUNet18A), 2D images (overview and pre-measured heatmaps via Swin Transformer), and RF-specific properties (transmitter location, mesh structure, frequency via Fourier embedding). These features are fused to form the conditioning input for the diffusion process.
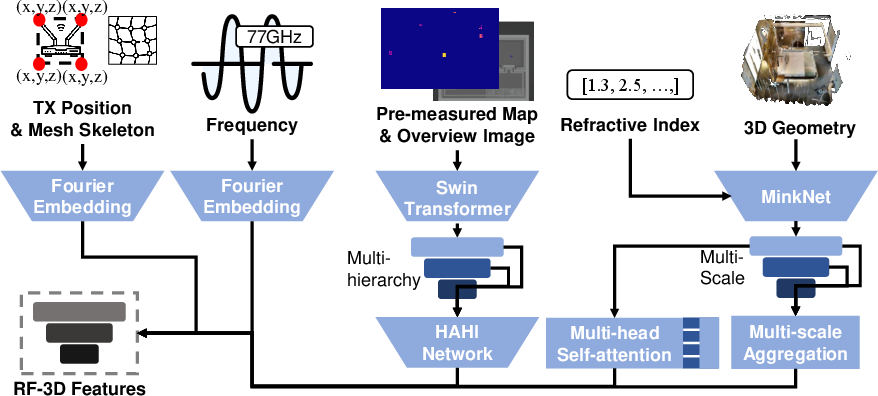
Figure 1: RF-3D Encoder embedding 2D, 3D, and RF signal.
- RF-3D Pairing Block: Integrates the noisy latent prediction with the environment-aware features, ensuring that the denoising step is informed by both the current prediction state and the spatial-temporal context of the environment.
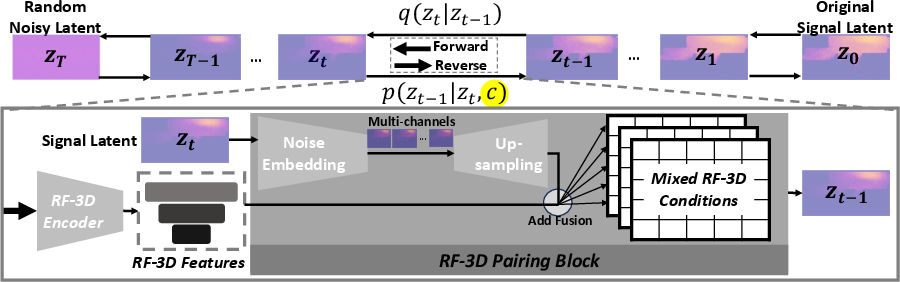
Figure 2: Overview of the diffusion process in Diffusion. RF-3D features condition the denoising process, while different modalities are fused through the RF-3D Pairing Block.
The model operates in latent space for computational efficiency, using a U-Net backbone with temporal layers for video generation. The loss function combines diffusion loss, pixel-wise L1/L2 losses, and RSSI error against pre-measured points.
Diffusion Process and Conditioning
The forward process adds Gaussian noise to the signal latent, while the reverse process reconstructs the RF heatmap by iteratively denoising, conditioned on the RF-3D features. Conditioning is critical for capturing the geometric and physical context, enabling the model to simulate realistic signal propagation effects such as reflection, diffraction, and scattering.
The conditioning vector c is constructed by fusing multi-scale 3D features, hierarchical 2D features, and RF signal embeddings. Spatial alignment between 2D and 3D modalities is achieved via explicit geometric cues and Fourier embeddings, compensating for the lack of camera models in the input data.
Video Diffusion for Dynamic Environments
Diffusion2 extends to video generation by incorporating temporal layers and cross-attention mechanisms, allowing the model to adapt to dynamic changes in the environment (e.g., human movement). The temporal layers process frame-to-frame differences in both the noisy latent and RF-3D features, enabling temporally consistent RF heatmap sequences.
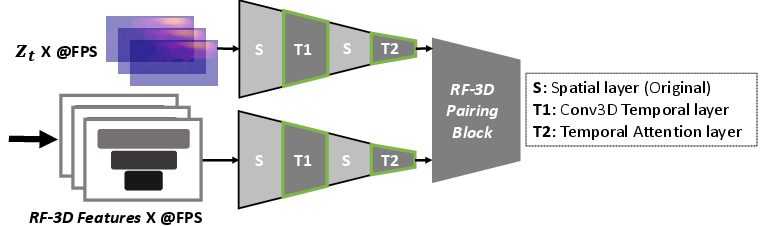
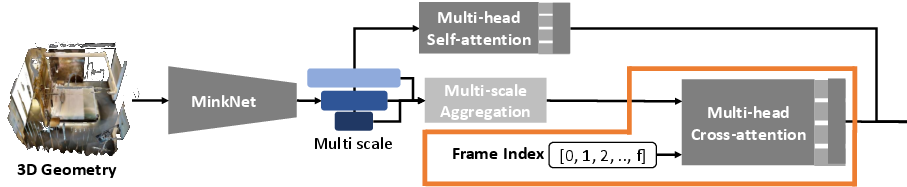
Figure 3: Two temporal layers denoted as T1 and T2 in processing both RF-3D Features and noisy latent zt.
Experimental Evaluation
Accuracy and Efficiency
Diffusion2 demonstrates strong performance across synthetic and real-world datasets:
- Median RSSI error: 1.9 dB (Wi-Fi), 1.20 dB (mmWave), outperforming NeRF2, MRI, and DiffusionDepth by 51–77%.
- Inference speed: 0.59 seconds for 200,000 receivers, achieving a 27× speedup over AutoMS and 33× over NeRF2.

Figure 4: Results for Diffusion, AutoMS, NeRF2, and MRI for one example environment at two frequencies.
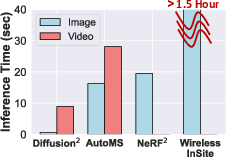
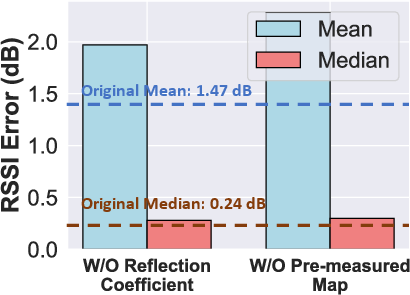
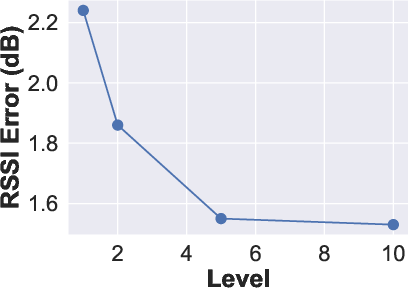
Figure 5: Inference time of the RF signal map generation.
Multi-Frequency Generalization
Training with multiple frequencies significantly improves generalization and physical plausibility of the predicted heatmaps. The model can infer RF maps for unseen frequencies with minimal degradation in accuracy.
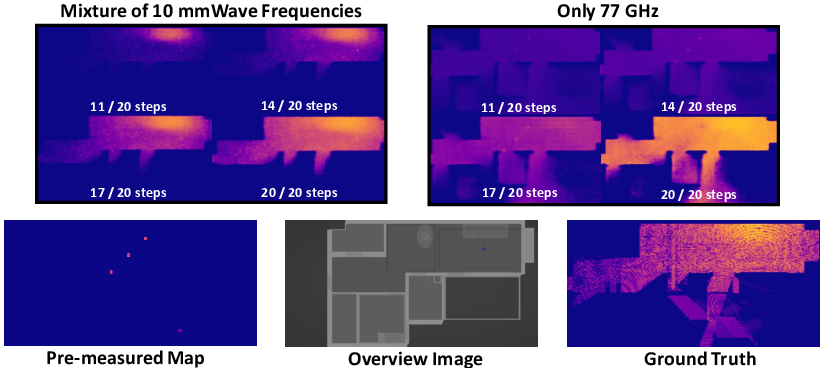
Figure 6: Effect of frequency diversity in training: 10 frequencies (77–77.072 GHz) vs. a single frequency (77 GHz). Results at steps 11, 14, 17, and 20 of a 20-step diffusion process.
Real-World Validation
Diffusion2 is validated in three real-world indoor scenarios using smartphone-based 3D scans and mmWave RSSI measurements. It consistently achieves lower median errors than AutoMS, NeRF2, and MRI, even in challenging locations (e.g., behind walls, outside doors).
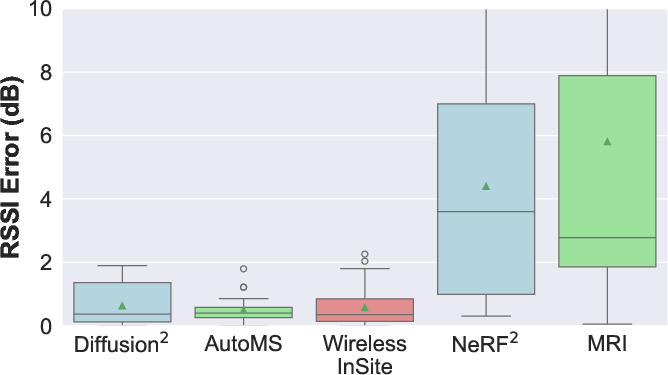
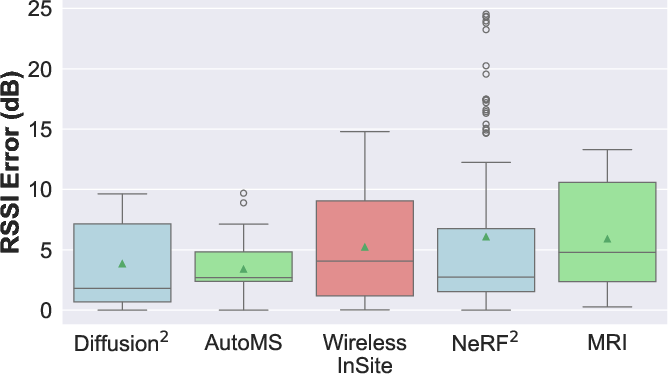
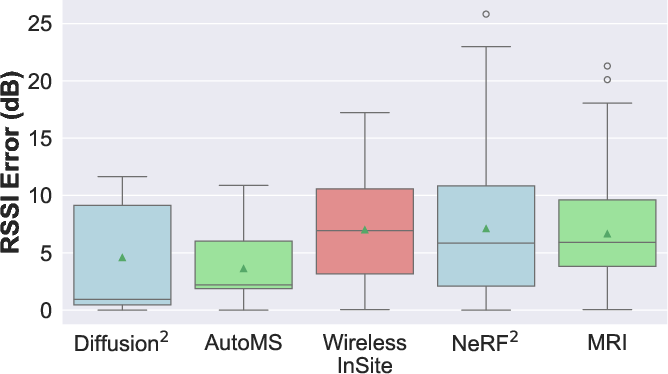
Figure 7: Scenario {1}.
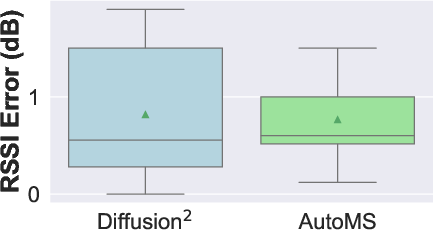
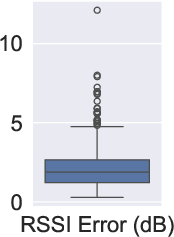
Figure 8: Real-world (Scenario {3}).
Robustness and Ablation
Ablation studies confirm the importance of each encoder component. The model is robust to missing 3D data (up to 20% removed), unseen material conditions, and incomplete input features (reflection coefficients, pre-measured maps). Increasing the number of training frequencies reduces RSSI error by 31.69%.
Implementation Details
- 3D Data: 3D-FRONT dataset, augmented for diversity.
- RF Simulation: AutoMS for amplitude and phase generation.
- Training: PyTorch, batch size 16, single NVIDIA A100 GPU, 20 epochs, Adam optimizer.
- Diffusion Steps: 1,000 for training, 20 for inference.
- Memory: ~40 GB GPU, ~1 day training time.
- Video Generation: DIMOS for human locomotion, 8 frames per video.
Limitations
The main limitation is the challenge of collecting finely paired 3D and RF datasets in diverse environments. The reliance on simulated data may introduce distribution gaps when deployed in real-world scenarios. However, the model demonstrates strong generalization and robustness in practical settings.
Implications and Future Directions
Diffusion2 represents a significant advancement in RF heatmap prediction, combining the strengths of ray-tracing and ML-based methods. Its ability to generalize across environments, frequencies, and dynamic scenarios with minimal measurement overhead opens new possibilities for wireless diagnosis, deployment optimization, and smart environment provisioning. Future work may focus on further reducing the domain gap between simulated and real data, integrating additional sensing modalities, and scaling to larger, more complex environments.
Conclusion
Diffusion2 establishes a new paradigm for RF signal propagation modeling in 3D environments, leveraging conditional diffusion and multi-modal feature fusion. It achieves high accuracy, efficiency, and generalizability, supporting both static and dynamic scenarios across a wide frequency range. The model's robustness to incomplete data and environmental changes positions it as a practical tool for real-world wireless applications and a foundation for future research in generative physical modeling.