RLAD: Training LLMs to Discover Abstractions for Solving Reasoning Problems
Abstract: Reasoning requires going beyond pattern matching or memorization of solutions to identify and implement "algorithmic procedures" that can be used to deduce answers to hard problems. Doing so requires realizing the most relevant primitives, intermediate results, or shared procedures, and building upon them. While RL post-training on long chains of thought ultimately aims to uncover this kind of algorithmic behavior, most reasoning traces learned by large models fail to consistently capture or reuse procedures, instead drifting into verbose and degenerate exploration. To address more effective reasoning, we introduce reasoning abstractions: concise natural language descriptions of procedural and factual knowledge that guide the model toward learning successful reasoning. We train models to be capable of proposing multiple abstractions given a problem, followed by RL that incentivizes building a solution while using the information provided by these abstractions. This results in a two-player RL training paradigm, abbreviated as RLAD, that jointly trains an abstraction generator and a solution generator. This setup effectively enables structured exploration, decouples learning signals of abstraction proposal and solution generation, and improves generalization to harder problems. We also show that allocating more test-time compute to generating abstractions is more beneficial for performance than generating more solutions at large test budgets, illustrating the role of abstractions in guiding meaningful exploration.
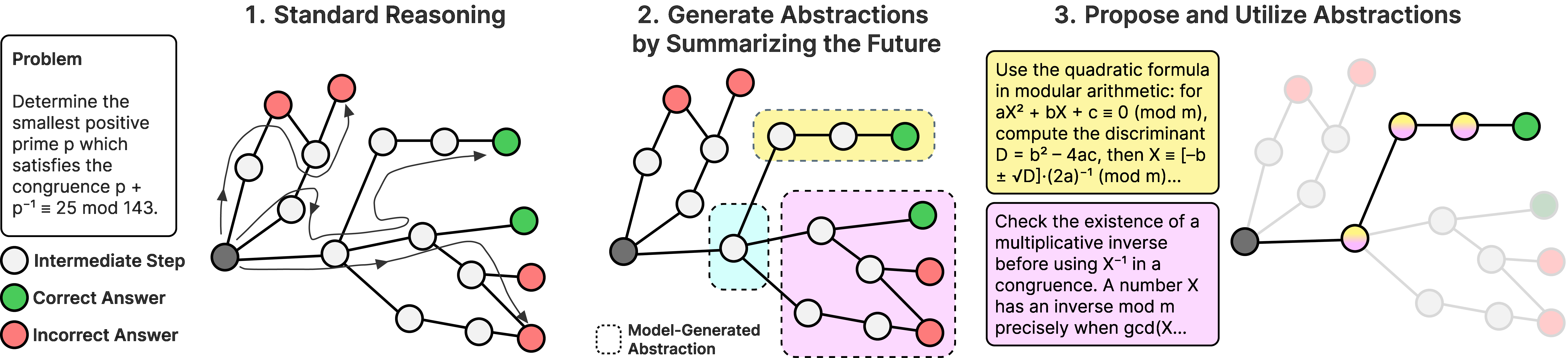
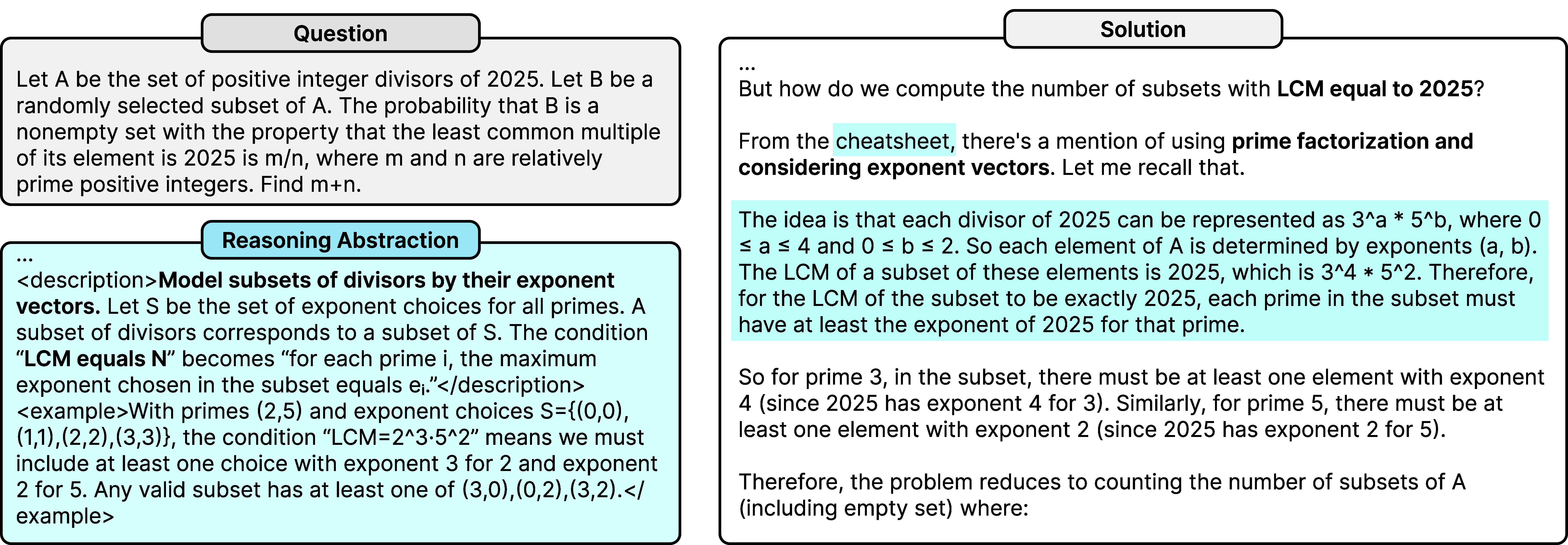
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching AI LLMs to solve hard problems by first writing their own helpful “hints” and then using those hints to guide their thinking. The authors call these hints reasoning abstractions. They are short, clear pieces of advice like mini cheat sheets: useful steps, tricks, or reminders that don’t give away the answer but point the model in the right direction.
What the researchers wanted to find out
They set out to answer simple questions:
- Can a model learn to invent good hints for a problem and then use those hints to solve it better?
- Does this approach help the model explore different strategies instead of getting stuck on one?
- Is it better to spend extra computing power making more hints or just trying more solutions?
- Do these hints help even stronger models, and do they work outside of math?
How they did it (in everyday terms)
Think of two teammates working together:
- The Hint Writer (abstraction generator): Given a problem, it writes a few short, general pointers—what tactics might work, common mistakes to avoid, useful facts, or steps to try.
- The Problem Solver (solution generator): It reads the problem plus the hint, then tries to solve it by following the hint.
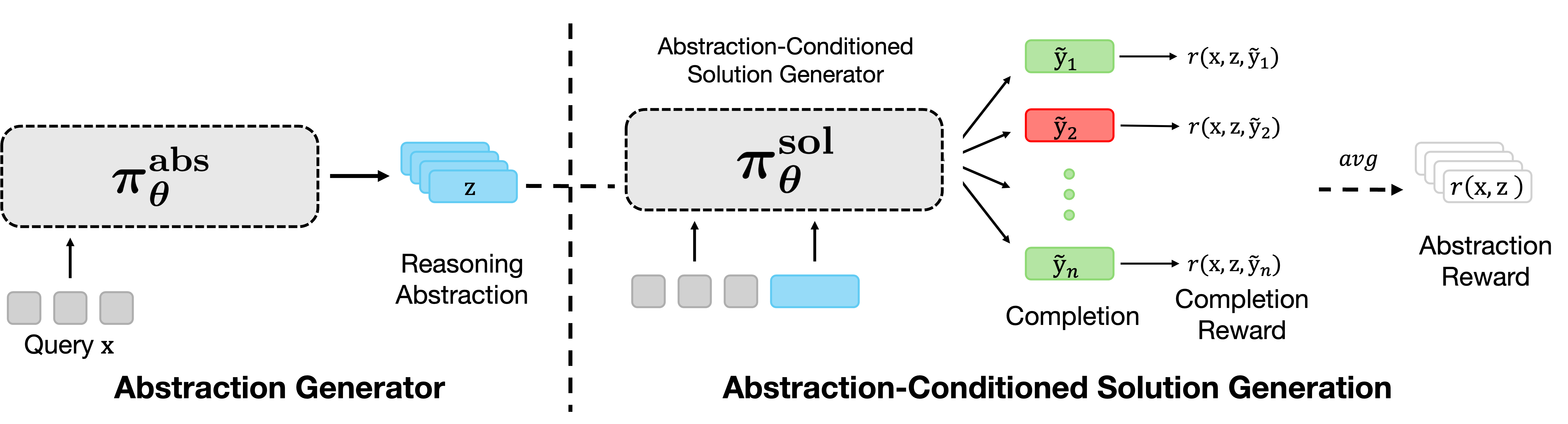
To get this to work well, they trained both teammates using a reward system (this is reinforcement learning, or RL—like practicing a game and getting points when you win):
- The Problem Solver gets a point if it gets the right answer.
- The Hint Writer gets points when its hint actually helps the solver do better than without the hint.
- They also make sure the hint doesn’t reveal the answer. If it does, it’s rejected. The hint must guide, not spoil.
How did they get started? At first, they “warm up” the Hint Writer by showing it good examples of hints. They create these examples by:
- Generating several solution attempts for a problem,
- Summarizing the useful ideas from these attempts into short hints (without the answer),
- Training the Hint Writer to produce hints like those.
Key idea: The model first proposes a few different hints (breadth of strategies), then tries to solve the problem using those hints. This encourages exploring multiple approaches instead of writing longer and longer chains of thought that may wander or repeat themselves.
A few terms in simple language:
- Reinforcement learning (RL): Practice with feedback—models try things, get a score, and adjust to do better next time.
- pass@k: If you try k solutions, did any of them succeed? This captures both accuracy and variety.
- Test-time compute: How many tries or how much thinking time you give the model when it’s solving a problem.
What they discovered and why it matters
Here are the main results the authors report:
- Better performance on tough math:
- On AIME 2025 and other math benchmarks, their method improved accuracy over strong RL baselines. In the abstract, they report an average 44% improvement over a top baseline (DAPO) on AIME 2025.
- Even when the solver wasn’t given hints during testing, the model trained with hints still did better—suggesting it learned generally useful reasoning habits.
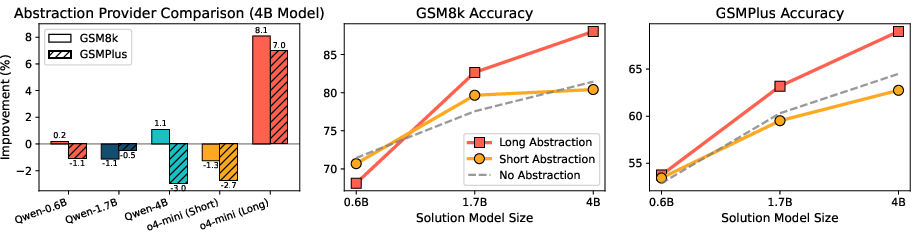
- Hints help even strong models:
- Hints written by a smaller “Hint Writer” improved the success of a stronger “Problem Solver.” This shows hints can transfer from weaker to stronger models.
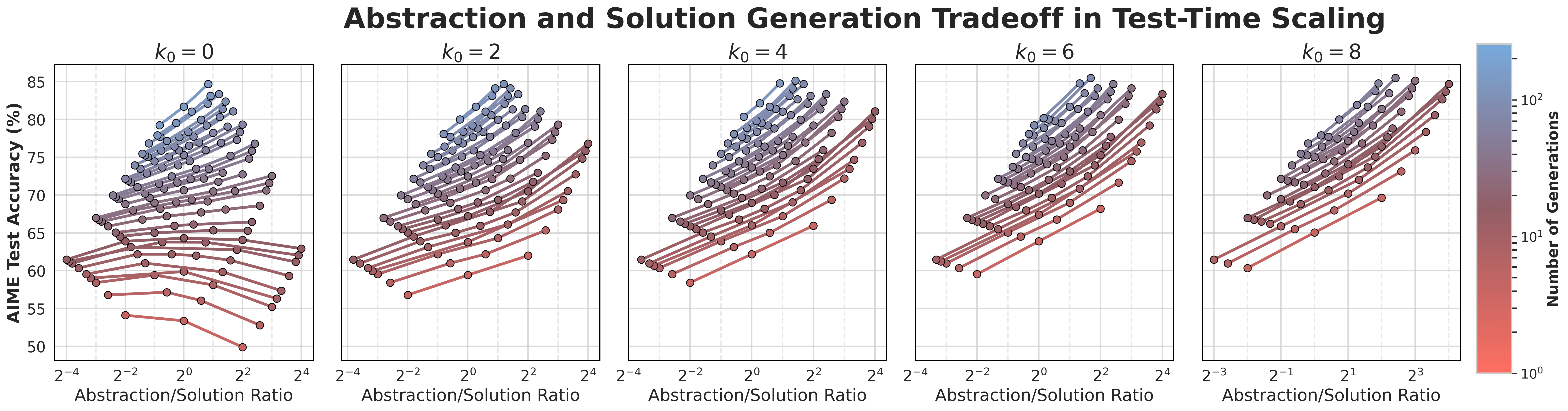
- How to spend extra compute:
- If you have more time/tries, it’s often better to generate more diverse hints than to just try more solutions with the same plan. In other words, breadth (new strategies) beats depth (longer or more of the same).
- Under equal compute, doing “n hints × n solutions per hint” outperformed “n² solutions without hints.”
- More diverse and more faithful solutions:
- When the solver reads a hint, it actually follows it more closely and produces different kinds of solutions (not just minor variations). This helps avoid getting stuck on one line of thought.
- Works beyond math:
- The idea of hints also helped on ARC-AGI (a puzzle/programming-like benchmark) and showed promise across other domains (like legal or healthcare questions), indicating the approach is general.
Why this is important and what could come next
Implications:
- A new way to scale thinking: Instead of only making chains-of-thought longer or sampling more solutions, we can scale by generating better, more varied hints. This adds a powerful new axis for improving problem-solving.
- More robust reasoning: Training with hints seems to build habits that help even without hints later—suggesting a path to more reliable and adaptable reasoning in AI.
- Practical guidance: If you have spare compute, spend more of it on generating diverse, high-quality hints to guide exploration, not just on repeating similar solution attempts.
Possible next steps:
- One model to do both jobs: Right now, hint writing and solving are done by two models. Can a single model reliably do both without forgetting how to write good hints during training?
- Understanding the “transfer” effect: Why does hint-based training also improve performance without hints? Studying this could lead to even better training methods.
- Broader domains: Test and refine hint strategies for open-ended tasks, science problems, multi-step planning, and real-world decision-making.
In short: The paper shows that teaching models to write and use their own helpful hints leads to smarter, more flexible problem-solving. It encourages trying different strategies, not just thinking longer, and it works across tasks and even helps stronger models—making it a promising direction for building better reasoning AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research:
- Dependence on stronger external models for warm-start abstractions
- The abstraction generator is initialized using abstractions produced by a stronger model (o4-mini); it is unclear whether the method works end-to-end without such external assistance, or how performance degrades if only in-house/base models are available.
- Reliability of “no-answer-leakage” checks
- Leakage is checked by sampling accuracy with abstraction-only prompts (16 samples) and using an LLM judge; this is not a formal guarantee and may miss partial or indirect leakage. More robust, model-agnostic leakage detection and guarantees are needed.
- Lack of online, joint RL training for abs and sol
- Abstraction training is “batched” offline (RFT) due to compute constraints; the effects of on-policy joint training (e.g., stability, exploration, non-stationarity) are untested. How to design scalable, stable online training remains open.
- Missing selection mechanism for “best abstraction” at inference
- Results report “w/ abs (best)” using oracle selection among 4 abstractions. No deployable policy is provided for selecting among candidate abstractions without ground-truth answers. Learning or estimating abstraction quality online is an open problem.
- No explicit objective or control for abstraction diversity
- The method proposes multiple abstractions but does not include diversity regularization or coverage objectives. How to generate a set of complementary abstractions that spans distinct strategies remains unexplored.
- Limited robustness analysis to wrong or adversarial abstractions
- The impact of misleading, noisy, or adversarial abstractions on solution quality is not studied. Methods to detect, down-weight, or recover from harmful abstractions are missing.
- Unclear generalization beyond math and small ARC sample
- Non-math claims (e.g., RAFT/CLUES/LegalBench) are briefly mentioned without detailed setup, metrics, or ablations; ARC-AGI evaluation uses 90 puzzles. Broader, more rigorous cross-domain evaluations and scaling studies are needed.
- Inference compute accounting and cost modeling
- Iso-compute curves treat abstraction and solution samples symmetrically, but actual token and latency costs differ. A precise cost model (tokens, latency, memory) and compute-optimal policies under real constraints are not provided.
- No formal theory of “abstraction” or guarantees
- Abstractions are defined operationally (improving conditional accuracy), with no formal properties (e.g., sufficiency, minimality, compositionality) or theoretical guidance on when abstractions should help over longer CoTs or more solution sampling.
- Sensitivity to abstraction length, structure, and format
- The paper notes very short abstractions underperform, but does not systematically study length/structure trade-offs, formatting constraints, or controlled compression strategies for compact-yet-useful abstractions.
- Token-level credit assignment within abstractions
- The reward for abs is aggregate solution accuracy, offering no fine-grained signal about which abstraction components were helpful. Techniques for token/segment-level credit assignment or causal attribution are not explored.
- Single-model unification remains unsolved
- A single model trained to both propose and use abstractions lost abstraction capability during RL. Strategies to prevent this (e.g., alternating objectives, multi-head decoders, adapter routing, mid-training curricula) remain open.
- Mechanism behind “training with abs improves w/o abs” is unclear
- The model’s performance without abstractions improves after training with abstractions, but the cause (regularization, implicit strategy learning, distributional smoothing) is not analyzed. Mechanistic and representational studies are needed.
- Abstraction adherence and semantic diversity rely on LLM judges
- Adherence classification and solution similarity use LLMs/embeddings, which can be biased. Human evaluation, task-specific automatic metrics, and robustness checks across judge models are absent.
- No comparison to strong plan/hint-generation baselines
- The method is not compared to strong prompt-planning baselines (e.g., Plan-and-Solve, ReAct variants, retrieved plan libraries, curriculum hints) or learned scaffolds. Head-to-head comparisons could clarify where abstractions uniquely help.
- Limited analysis of reward design side effects
- Zeroing rewards for no-abstraction prompts to force conditioning may have unintended effects (e.g., shortcutting via superficial references, over-dependence on guidance). Auditing for reward hacking and verifying genuine utilization are open tasks.
- Coverage of solution-space “reasoning graph” is not operationalized
- While the paper conceptualizes reasoning as a graph, it lacks algorithms to select abstractions that provably cover diverse subgraphs (e.g., submodular selection, DPPs, bandit exploration of substructures).
- Stability to abs–sol strength asymmetries
- Training stability when abs and sol differ greatly in capability (too strong/weak) is discussed but not deeply analyzed. Adaptive curricula, capability matching, or automatic rebalancing strategies remain to be developed.
- Limited ablations on warm-start data quality
- The pipeline for generating seed abstractions (models, prompts, filtering) is critical but under-ablated. How seed quality, diversity, and domain-coverage affect final performance is unknown.
- No study of iterative or interactive abstraction refinement
- Abstractions are generated once per problem. Iterative refine-and-use cycles, hierarchical abstractions, or interactive subgoal updates during solution generation are not explored.
- Dataset construction and contamination checks
- Potential train–test contamination for benchmarks (e.g., AIME, AMC, OmniMATH subsets) is not discussed; rigorous decontamination and transparent data splits would strengthen claims.
- Transfer across model families and sizes
- Weak-to-strong transfer is shown for one pairing (abs from smaller model, sol as o4-mini). Systematic study across architectures, sizes, and families (including open models) is missing.
- Failure case analysis and gating
- Cases where abstractions hurt performance (e.g., some AMC w/ abs avg drops) are not dissected. Methods to predict when to use abstractions, fallback policies, and confidence-based gating are needed.
- Scaling with constrained token budgets
- Experiments use up to 32k tokens; the approach’s effectiveness with tighter budgets (e.g., 2–4k) and techniques for ultra-compact abstractions or compressed solution traces are open.
- Multi-task or continual learning with reusable abstractions
- The reusability of abstractions across related problems or tasks (e.g., caching, retrieval, library building) is not investigated; learning persistent, general libraries remains open.
- Safety and bias of abstraction content
- Abstractions may encode flawed heuristics or biased procedures; there is no auditing of abstraction content for harmful patterns or systematic errors and their downstream effects.
- Alternative training signals
- The work uses 0/1 accuracy; richer signals (unit test coverage, intermediate step verification, reward shaping for proper abstraction use) and their impact on learning dynamics are unexplored.
- Integration with tool use and external memory
- How abstractions interact with tools (calculators, solvers), external knowledge bases, or memory-augmented agents is not studied; hybrid pipelines may yield further gains.
- Formalizing compute allocation between abstractions and solutions
- The “normalization offset” k0 is heuristic; optimizing compute allocation under realistic cost functions and uncertainty models, with theoretical or empirical guarantees, is an open direction.
Practical Applications
Practical Applications of “Training LLMs to Discover Abstractions for Solving Reasoning Problems”
Below are actionable, real-world applications derived from the paper’s findings and methods. The items are grouped by deployment horizon and linked to sectors, with notes on potential tools/workflows and assumptions that affect feasibility.
Immediate Applications
These can be deployed now with existing LLMs, RL pipelines, and moderate engineering effort.
- Abstraction-augmented tutoring systems
- Sector: Education
- Use case: Personalized “hint-first” math and STEM tutors that generate diverse, high-level strategies (lemmas, pitfalls, launchpoints) before showing worked solutions; improves pass@k and reduces solution drift.
- Tools/workflows: An “Abstraction Generator” microservice (RLAD-trained), a Solution Generator tuned to follow hints; classroom or MOOC integration; adaptive test-time compute allocation (more hints when student struggles).
- Assumptions/dependencies: Reliable ground-truth checking for correctness, strong instruction-following models (e.g., Qwen3-family), guardrails to prevent answer leakage.
- IDE plugin for strategy-aware code assistants
- Sector: Software
- Use case: Generate “strategy cards” for coding tasks (algorithm outlines, common pitfalls, test scaffolds) and condition code synthesis on them; improves ARC-like program synthesis and debugging.
- Tools/workflows: Abstraction-conditioned CoT prompts; an IDE extension that surfaces multiple abstractions per task and lets users pin or refine one; weak-to-strong pipeline (small model generates abstractions, large model codes).
- Assumptions/dependencies: Availability of unit tests or correctness checks; existing code LLMs capable of following constraints; answer leakage judges or rules.
- Multi-agent “hint + solver” architecture for enterprise workflows
- Sector: Cross-industry (support, operations, analytics)
- Use case: A lightweight agent proposes procedural abstractions (checklists, heuristics, failure modes), and a solver agent executes them for troubleshooting, root-cause analysis, or report drafting.
- Tools/workflows: RLAD two-player framework; structured memory of reusable abstractions per workflow; test-time compute policies that favor new strategy exploration when retries saturate.
- Assumptions/dependencies: Domain-specific reward signals or QA processes; consistent format for abstractions; monitoring to avoid hallucinations.
- Legal research assistance with principle-oriented guidance
- Sector: Legal
- Use case: Generate input-dependent procedural and doctrinal “abstractions” (key tests, relevant filings, pitfalls) to guide argument generation, memo drafting, and case comparison; aligns with the paper’s gains on LegalBench.
- Tools/workflows: Abstraction-first prompting; retrieval of case law followed by hint synthesis; solution generator that references hints (“blind-follow” vs. “caution alert” patterns).
- Assumptions/dependencies: Up-to-date legal corpora; human oversight; strict leakage controls (no premature conclusions presented as hints).
- Safety and guardrails via “caution abstractions”
- Sector: Consumer chatbots, enterprise AI, healthcare triage (non-diagnostic)
- Use case: Before answering, generate a “caution abstraction” that enumerates known pitfalls, misinterpretations, safety considerations; improves adherence and reduces hallucinations.
- Tools/workflows: Caution-abstraction templates; adherence scoring (LLM-as-judge); policies that require a vetted abstraction before final answer.
- Assumptions/dependencies: High-quality judges to detect leakage and hallucination risks; policy hooks in UX to surface caution content.
- Weak-to-strong cost-saving pipelines
- Sector: Enterprise AI
- Use case: Small, cheaper abstraction generator steers a larger, expensive solver (demonstrated gains with o4-mini); reduce inference cost while increasing accuracy.
- Tools/workflows: Orchestration that pairs “abs → sol” with configurable budgets; caching and re-use of abstractions for similar problems.
- Assumptions/dependencies: Strong solver compatible with abstraction format; robust evaluation to confirm strategy transfer.
- Test-time compute allocation policies
- Sector: Platform engineering, AI ops
- Use case: Implement compute-optimal scheduling that shifts budget from additional solution samples to additional diverse abstractions once local retries saturate; empirically improves pass@k.
- Tools/workflows: Inference scheduler using iso-compute curves (m abstractions × k solutions per abstraction); dynamic tuning of m:k ratio; pass@k tracking dashboards.
- Assumptions/dependencies: Telemetry and performance analytics; business rules to cap cost; support for parallel sampling.
- Knowledge management through “Reasoning Cards”
- Sector: Consulting, product management, research orgs
- Use case: Synthesize reusable procedural/factual “cards” (abstractions) from past engagements to guide future problem-solving; improve consistency and onboarding.
- Tools/workflows: Abstraction library with tags (techniques, pitfalls, lemmas); retrieval augmented abstraction-conditioning; governance for card quality.
- Assumptions/dependencies: Processes to curate cards; permissioning and provenance; basic correctness checks.
- Program synthesis and data engineering scaffolds
- Sector: Software, Data
- Use case: Generate high-level plan abstractions for ETL, data validation, schema migration; condition solution generation on plan to reduce drift and underthinking.
- Tools/workflows: Abstraction-first pipelines for DSL or SQL tasks; unit-test coverage metrics; adherence scoring to ensure solver follows the plan.
- Assumptions/dependencies: Availability of test cases; solver’s ability to respect constraints; domain-specific tokens (e.g., schema names).
- Policy and legislative analysis “procedural hints”
- Sector: Public policy
- Use case: Produce abstractions summarizing procedural constraints, precedent, stakeholders, and common pitfalls before drafting analyses; promote breadth over single-track reasoning.
- Tools/workflows: Abstraction generator tuned on policy corpora; human-in-the-loop review; adherence tracking.
- Assumptions/dependencies: Trust in sources; valence framing to avoid bias; strict leakage guardrails.
Long-Term Applications
These require further research, scaling, domain validation, or regulatory approvals.
- Unified “Abstraction + Solution” single-model training
- Sector: Foundation models, model training
- Use case: Overcome the observed collapse of abstraction skills during RL by mid-training or new objectives that preserve both proposal and utilization capabilities in one model.
- Tools/workflows: Novel RL objectives, offline RL pipelines, curriculum mixing of hint-only and hint-conditioned traces; stability/regularization methods.
- Assumptions/dependencies: Access to large-scale training compute and corpora; robust evaluation; stable reward signals.
- Persistent cross-task memory of abstractions
- Sector: AI agents
- Use case: Accumulate and generalize abstractions across tasks (dynamic memory); retrieve and adapt them for new problems; akin to a reusable skill library.
- Tools/workflows: Semantic indexing for abstractions; meta-learning for hint adaptation; “abstraction adherence” telemetry; long-term memory management.
- Assumptions/dependencies: Reliable similarity metrics; drift control; privacy-safe storage.
- Clinical decision support “protocol abstractions”
- Sector: Healthcare
- Use case: Generate validated diagnostic/treatment abstractions (pathways, contraindications, pitfalls) as structured hints to guide clinician reasoning; reduce cognitive load.
- Tools/workflows: Integration with EHRs; adherence scoring; multi-modal inputs (labs, imaging); clinical QA loops.
- Assumptions/dependencies: Regulatory approval; gold-standard rewards and datasets; rigorous RCTs; explainability and safety standards.
- Robotics and autonomous systems planning
- Sector: Robotics, logistics
- Use case: Use natural-language abstractions as high-level task decompositions that guide low-level planners; broader exploration of strategies over depth-only replanning.
- Tools/workflows: LLM-to-planner interfaces; symbolic/constraint solvers; simulation-to-real transfer with abstraction conditioning.
- Assumptions/dependencies: Stable mapping from text hints to control policies; safety; domain-specific reward functions.
- Scientific discovery and theorem proving
- Sector: Academia, R&D
- Use case: Generate intermediate lemmas and conjecture abstractions; compose multiple strategy paths for proof attempts; improve exploration of the research search space.
- Tools/workflows: Integration with formal systems (Isabelle/Lean); hint-conditioned prover agents; weak-to-strong pairing (small abstraction, strong prover).
- Assumptions/dependencies: Formal verification infrastructure; correctness signals; interpretability standards.
- Compute-optimized inference orchestration platforms
- Sector: AI infrastructure
- Use case: Production systems that dynamically allocate m:k (abstractions vs. solutions) based on saturation signals; cost-aware autoscaling for pass@k gains.
- Tools/workflows: Schedulers using iso-compute frontiers; policy rules for budget caps; on-line learning of allocation strategies.
- Assumptions/dependencies: Good observability; stable performance predictors; governance for cost/latency trade-offs.
- Organizational “strategy marketplaces”
- Sector: Enterprise
- Use case: Curate and share proven abstractions (“strategy cards”) across teams; marketplace to rate reuse; plug-in to agents and copilot tools.
- Tools/workflows: App for browsing, tagging, applying abstractions; integration with auth/RAG; quality ranking; feedback loops.
- Assumptions/dependencies: Incentives for contribution; QA; privacy control and IP rights.
- Auditing and interpretability via abstraction adherence
- Sector: Compliance, risk
- Use case: Use adherence metrics to monitor whether models follow approved strategies; increase transparency in regulated environments (finance, healthcare).
- Tools/workflows: LLM-judge pipelines; adherence dashboards; policy exceptions handling.
- Assumptions/dependencies: Robust judges; human review; governance frameworks.
- Cybersecurity and red-teaming with procedural checks
- Sector: Cybersecurity
- Use case: Generate security “playbook abstractions” (attack chains, common misconfigurations, mitigation steps) to guide automated pentesting or triage reasoning; leverage breadth of strategies.
- Tools/workflows: Strategy-conditioned exploit simulation; coverage metrics; caution abstractions to prevent unsafe execution.
- Assumptions/dependencies: Strict safety controls; sandboxing; validated rulesets.
- Financial analysis and compliance checklists
- Sector: Finance
- Use case: Strategy abstractions for risk assessment, audit procedures, compliance tests; condition report generation on these to reduce drift and omission errors.
- Tools/workflows: Abstraction stores aligned to regulatory frameworks (e.g., Basel III, SOX); validation workflows; adherence and coverage tracking.
- Assumptions/dependencies: Legal/regulatory alignment; vetted datasets; strong correctness signals.
Notes on Assumptions and Dependencies
- Correctness and rewards: The approach depends on access to reliable ground-truth or proxy rewards (0/1 accuracy, unit-test coverage, rule-based checks).
- Instruction-following capacity: Benefit is largest when the solution generator can understand and apply abstractions; weaker models may underutilize hints.
- Answer leakage control: Requires prompts and LLM-judge checks to ensure abstractions don’t reveal answers.
- Domain adaptation: Abstractions vary by domain (procedural vs. factual proportion); sector-specific tuning is needed.
- Compute budgets: Gains hinge on test-time compute allocation; performance improves by shifting budget to diverse abstractions when retries saturate.
- Safety and governance: For regulated sectors (healthcare, finance), human oversight, evaluation standards, and compliance processes are prerequisites.
- Infrastructure: RLAD training (two-player RL) and orchestration pipelines are needed to produce and use abstractions robustly; offline RL or batched RFT may be used when on-policy is infeasible.
Overall, the paper’s abstraction-first paradigm (RLAD) offers a practical way to broaden LLM reasoning strategies, improve pass@k, and more efficiently allocate test-time compute—yielding immediate wins in education, software, and enterprise reasoning, and promising long-term impact in healthcare, robotics, scientific discovery, and regulated decision-making.
Glossary
- Abstraction adherence: The degree to which a generated solution follows the guidance or strategy specified by an abstraction. "higher abstraction adherence than baselines."
- Abstraction generator: A model component that proposes candidate reasoning abstractions for a given problem. "we jointly train two LLMs via RL post-training: (1) an abstraction generator, and (2) an abstraction-conditioned solution generator."
- Abstraction-conditioned solution generator: A model that produces solutions while conditioning on the provided abstraction to guide its reasoning. "we jointly train two LLMs via RL post-training: (1) an abstraction generator, and (2) an abstraction-conditioned solution generator."
- AIME 2025: A math reasoning benchmark derived from the American Invitational Mathematics Examination. "AMC 2023, AIME 2025, and DeepScaleR Hard"
- AMC 2023: A math reasoning benchmark derived from the American Mathematics Competitions. "AMC 2023, AIME 2025, and DeepScaleR Hard"
- ARC-AGI: A benchmark of program synthesis puzzles used to assess abstract reasoning and general intelligence. "We also evaluate abstractions on the ARC-AGI benchmark."
- Asymmetric clipping: A reinforcement learning stabilization technique that clips policy updates differently depending on direction or magnitude. "include token-level policy loss normalization and asymmetric clipping."
- BARC: A benchmark suite related to ARC-AGI variations. "ARC-AGI 1, ARC-AGI 2, and BARC"
- Chain-of-thought (CoT): A prompting and training paradigm where models produce explicit intermediate reasoning steps. "state-of-the-art long chain-of-thought RL approaches (i.e., DAPO~\citep{yu2025dapo})"
- CLUES: A benchmark suite for evaluating reasoning and understanding tasks. "over 37 tasks from RAFT~\citep{alex2021raft}, CLUES~\citep{menon2022clues}, and LegalBench~\citep{guha2023legalbench}."
- Compute-optimal strategy: An allocation of limited inference compute across components (e.g., abstractions vs. solutions) to maximize performance. "This corresponds to a ``compute-optimal strategy''~\citep{snell2024scaling}"
- DAPO: A reinforcement learning post-training baseline for long chain-of-thought reasoning used as a comparison point in the paper. "state-of-the-art long chain-of-thought RL approaches (i.e., DAPO~\citep{yu2025dapo})"
- DeepScaleR [Hard]: A subset of hard math problems from the OmniMATH mixture used as an evaluation benchmark. "\multicolumn{3}{c}{DeepScaleR [Hard]}"
- DPO: Direct Preference Optimization, an offline RL method for aligning LLMs using preference signals. "offline RL methods (e.g., DPO~\citep{rafailov2023direct}, STaR~\citep{zelikman2022star})."
- GRPO: An on-policy reinforcement learning algorithm used for post-training LLMs on reasoning tasks. "on-policy RL (e.g., GRPO~\citep{shao2024deepseekmath})"
- Iso-compute frontiers: Curves showing performance trade-offs under fixed total compute when varying allocation between components (e.g., abstractions vs. solutions). "Figure~\ref{fig:abstraction_ratio} shows these iso-compute frontiers for different values of the compute budget."
- KL-constrained RL fine-tuning: RL post-training that constrains policy updates via a KL-divergence penalty to stay close to a reference model. "When utilizing KL-constrained RL fine-tuning, is now trained to closely mimic the distribution of responses as the reference LLM..."
- LegalBench: A benchmark suite for evaluating legal reasoning tasks. "over 37 tasks from RAFT~\citep{alex2021raft}, CLUES~\citep{menon2022clues}, and LegalBench~\citep{guha2023legalbench}."
- Memory-augmented agents: Agentic LLM systems that retrieve and use stored memories to inform future decisions or reasoning. "and memory-augmented agents~\citep{Sch_fer_2020} to encode prior problem-solving knowledge."
- OmniMATH: A large mixture of math problems used in training and evaluation of reasoning models. "which itself is a subset of hard problems from the OmniMATH mixture"
- Offline RL: Reinforcement learning using fixed datasets without online interaction during training. "offline RL methods (e.g., DPO~\citep{rafailov2023direct}, STaR~\citep{zelikman2022star})."
- On-policy RL: Reinforcement learning where the policy being optimized is the one used to generate training data. "on-policy RL (e.g., GRPO~\citep{shao2024deepseekmath})"
- Pass@k: A metric that counts a problem as solved if any of k sampled solutions is correct. "We also measure the pass@k metric, where for problem , we sample solutions..."
- RAFT: A benchmark suite for realistic few-shot tasks assessing classification and reasoning. "over 37 tasks from RAFT~\citep{alex2021raft}, CLUES~\citep{menon2022clues}, and LegalBench~\citep{guha2023legalbench}."
- Retrieval-Augmented Generation (RAG): A paradigm where a model retrieves external documents to condition its generation. "Existing retrieval-augmented generation (RAG) pipelines assume a static corpus..."
- RFT: Reinforcement Fine-Tuning; here, a batched offline RL approach used to optimize the abstraction generator. "we opt to use ``batched'' offline RL via RFT~\citep{yuan2023scaling}"
- Scratchpads: Intermediate computation notes generated alongside reasoning to help solve problems. "scratchpads~\citep{nye2021workscratchpadsintermediatecomputation}"
- Semantic similarity: A measure of how similar two texts are in meaning, often computed via embeddings. "We compute semantic similarity by encoding solutions into vector representations..."
- SFT: Supervised Fine-Tuning; training on labeled examples to initialize or improve a model before RL. "we warmstart the abstraction generator by running supervised fine-tuning (SFT)"
- STaR: A training method that uses generated solutions with self-reflection to improve reasoning ability. "offline RL methods (e.g., DPO~\citep{rafailov2023direct}, STaR~\citep{zelikman2022star})."
- Test-time compute: The amount of computational budget used at inference (deployment) time, e.g., number/length of samples. "Scaling test-time compute and exploration."
- Two-player RL training paradigm: A cooperative setup where an abstraction proposer and a solution generator are jointly optimized via RL. "This results in a two-player RL training paradigm, abbreviated as , that jointly trains an abstraction generator and a solution generator."
- Warmstart: Initializing training from a model already trained on related data or tasks to stabilize or accelerate RL. "we warmstart the abstraction generator by running supervised fine-tuning (SFT)"
- Weak-to-strong generalization: Using artifacts produced by a weaker model (e.g., abstractions) to improve a stronger model’s performance. "We next evaluate the weak-to-strong generalization of our method..."
- max@k coverage: A program-synthesis evaluation metric measuring the proportion of unit tests passed across k samples. "pass@k accuracy and max@k coverage on the ARC-AGI benchmark."
Collections
Sign up for free to add this paper to one or more collections.

