- The paper presents GRACE, a novel IRL framework that uses LLM-powered evolutionary search to generate executable reward functions from expert demonstrations.
- The paper demonstrates that GRACE achieves sample-efficient reward recovery and strong policy performance, often rivaling ground-truth signals in environments like MuJoCo.
- The paper highlights the interpretability and modularity of code-based rewards, enabling transparency and function reuse across various reinforcement learning tasks.
An Analysis of "GRACE: A LLM Framework for Explainable Inverse Reinforcement Learning"
Introduction
The paper "GRACE: A LLM Framework for Explainable Inverse Reinforcement Learning" introduces a novel approach to Inverse Reinforcement Learning (IRL) that leverages the capabilities of LLMs for creating interpretable reward functions through evolutionary search. Traditional IRL methods typically involve deep neural networks to infer reward models based on expert demonstrations, which often result in opaque, black-box representations that are challenging to interpret and debug. GRACE addresses this limitation by generating reward functions as executable code, providing a transparent and verifiable framework suitable for modern RL applications.
Methodology
GRACE operates by integrating LLMs within an evolutionary search framework to iteratively refine a reward function represented as Python code. This method unfolds in three distinct phases: initialization, reward refinement, and active data collection.
Initialization Phase involves utilizing an LLM to analyze expert and random trajectories to generate an initial set of reward programs. The generated code is treated as a population of possible reward functions.
Reward Refinement Phase applies an evolutionary search method inspired by genetic algorithms. It uses LLM-powered mutations to iteratively refine the reward code based on discrepancies observed in expert versus negative trajectory data (Figure 1). The fitness of a reward function is calculated using a discriminator from AIRL methodology, promoting transferable and effective reward structures.
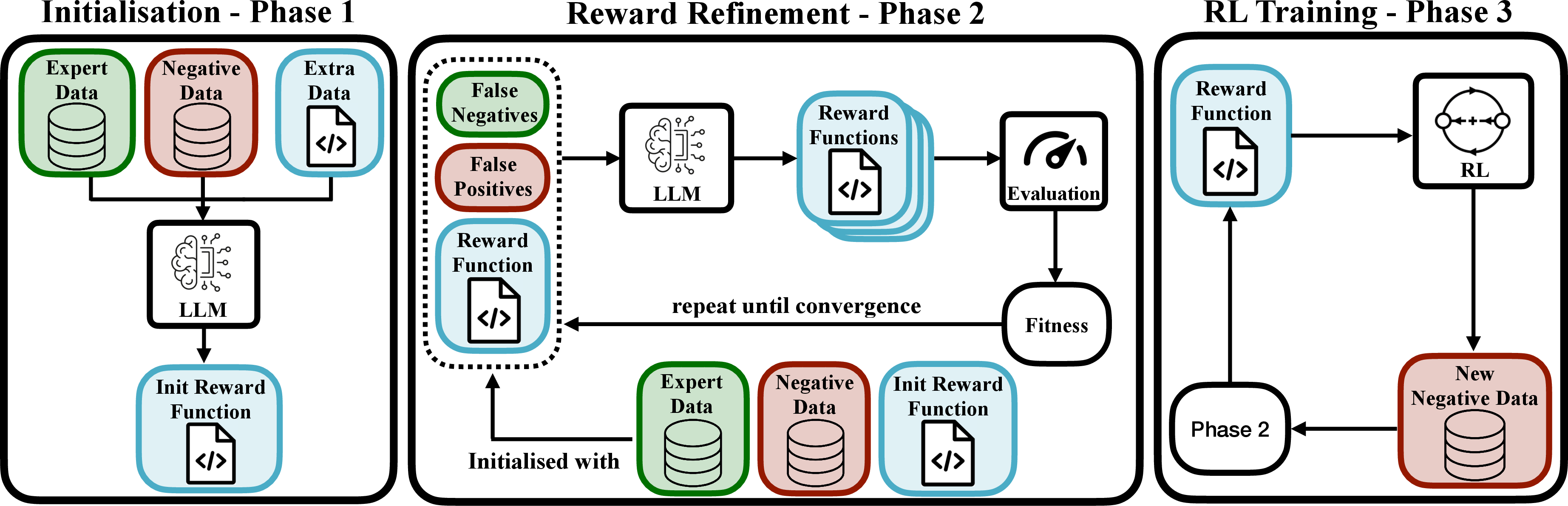
Figure 1: Overview of the GRACE framework. (a) The expert, negative, and extra data (if any) is used to generate an initial set of possible reward functions. (b) The expert and negative states are used to mutate reward functions through an evolutionary procedure. The rewards are iteratively refined by feeding low-fitness examples to the reward. (c) An agent is trained with online RL using the converged reward; the data it sees during the training is added to D− and used to further improve the reward.
Active Data Collection Phase involves using the best-performing reward function to train an RL agent and collect additional trajectory data. This data is utilized to further refine the reward functions, identifying and correcting potential edge cases or failure modes.
Experimental Results
The empirical evaluation of GRACE spans three environments: BabyAI for procedural reasoning, MuJoCo for continuous control, and AndroidWorld for real-world applications. The results indicate several strengths of GRACE:
Sample Efficiency: GRACE successfully recovers robust reward functions with few expert demonstrations, significantly outperforming traditional IRL baselines like GAIL in terms of data efficiency.
Policy Learning Performance: Across MuJoCo tasks, GRACE-derived reward functions lead to strong policy performance, often matching or exceeding those achieved via ground-truth reward signals (Figure 2).
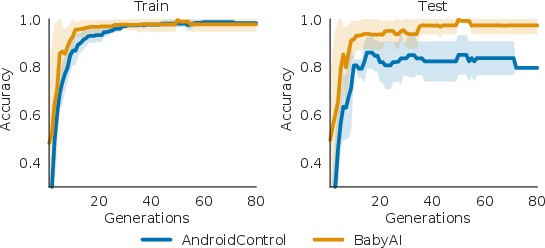
Figure 2: Fitness vs Number of generations. Evolution of train and test fitness across evolution generations, as defined by Algorithm~\ref{alg:grace}, for BabyAI and AndroidControl (multi-level settings).
Interpretability and Modularity: The code-based rewards not only offer transparency into the decision-making process but also exhibit modularity, allowing for function reuse across tasks and environments (Figure 3).
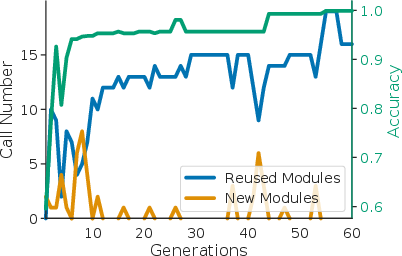
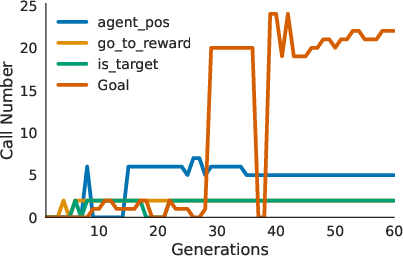
Figure 3: Module and function reuse across generations. On the left, the number of newly created modules and the number of existing and reused modules from prior rewards are contrasted with accuracy in the reward population. On the right, the number of times a module is reused is shown for a selected set of modules.
Discussion and Future Directions
The GRACE framework demonstrates powerful capabilities in generating interpretable, effective reward functions from limited expert data, addressing key challenges in the conventional IRL paradigm. However, its reliance on code generation poses limitations when dealing with high-dimensional state spaces, where neural networks may offer superior performance due to their ability to learn distributed representations from raw sensory data.
Future research could explore hybrid systems that integrate code-based rewards with neural networks for perception tasks, thus leveraging the strengths of both interpretable and black-box models. Additionally, extending GRACE to utilize toolkits for predefined models could enhance programmatic reasoning capabilities in complex environments.
Conclusion
GRACE represents a significant advancement in the domain of IRL by enabling explainable, code-based rewards through LLM-driven evolutionary search. This framework not only provides sample-efficient and robust reward generation but also enhances transparency and modularity, paving the way for scalable and interpretable RL solutions in diverse applications. Through strategic evolution and high-level reasoning, GRACE exemplifies the next step in bridging the gap between expert insights and automated learning in AI systems.

