A Scene is Worth a Thousand Features: Feed-Forward Camera Localization from a Collection of Image Features
Abstract: Visually localizing an image, i.e., estimating its camera pose, requires building a scene representation that serves as a visual map. The representation we choose has direct consequences towards the practicability of our system. Even when starting from mapping images with known camera poses, state-of-the-art approaches still require hours of mapping time in the worst case, and several minutes in the best. This work raises the question whether we can achieve competitive accuracy much faster. We introduce FastForward, a method that creates a map representation and relocalizes a query image on-the-fly in a single feed-forward pass. At the core, we represent multiple mapping images as a collection of features anchored in 3D space. FastForward utilizes these mapping features to predict image-to-scene correspondences for the query image, enabling the estimation of its camera pose. We couple FastForward with image retrieval and achieve state-of-the-art accuracy when compared to other approaches with minimal map preparation time. Furthermore, FastForward demonstrates robust generalization to unseen domains, including challenging large-scale outdoor environments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to figure out where a camera is and which way it’s pointing by looking at images. The method is called FastForward. Its big idea: instead of building a heavy 3D model of a place or training a special network for each scene, it uses a small, smart collection of “features” from a few photos to quickly locate the camera in one go. This makes camera localization fast enough for real-world apps like AR and navigation.
What questions does the paper ask?
Here are the main questions the authors want to answer:
- Can we make camera localization accurate but much faster, without hours of map-building or per-scene training?
- What is the simplest kind of “map” we need to localize a new image well?
- Can a single quick pass of a neural network locate a camera using only a small set of scene features?
Their answer: yes, and the simplest useful “map” is a collection of image features tied to 3D positions, plus a smart way to compare them to the new image.
How does FastForward work?
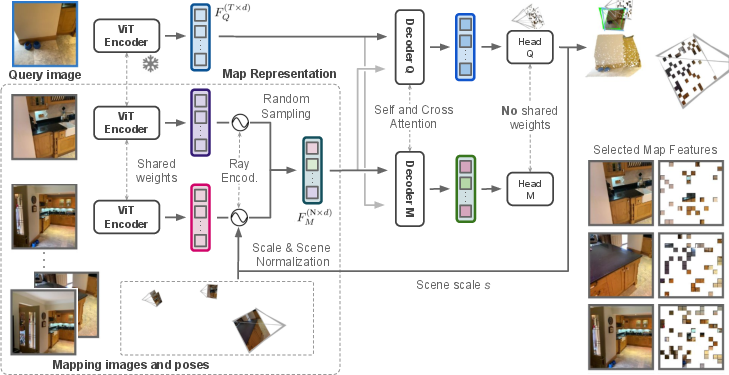
Think of a scene (like a courtyard or a room) as a set of landmarks. Each landmark is a small visual pattern from a photo (a “feature”) and the 3D spot where it exists in the world. FastForward uses these landmarks to understand where a new camera is.
Here’s the approach in everyday terms:
- Making a lightweight scene “map”
- Take a bunch of photos of the place where you know the camera positions (these are “mapping images”).
- From these photos, extract visual “features” using a transformer model (a ViT): these are like distinctive patches (edges, corners, textures) that are good to recognize.
- Don’t keep all features; randomly sample a few thousand of them. This keeps things fast and memory-light.
- Attach a “ray” to each feature that encodes where the photo’s camera was and which direction it was looking. This gives the network context: not just what the feature looks like, but where it came from.
- Normalizing the scene and its scale
- Different datasets have different scales (a statue vs. a city block). To avoid confusion, the system normalizes the scene:
- It sets one camera as the origin (like putting one photo at the center of a coordinate system).
- It scales the scene so the largest camera movement becomes 1. This makes training across many scenes simpler.
- After the network predicts the 3D points for the query image, it multiplies them by the scale factor to get back to the true size.
- Locating the new image
- For the new image (the “query”), FastForward extracts its features with the same encoder.
- A decoder with cross-attention compares query features to the map’s features. Think of this as a “smart matching” process: the network looks back and forth to figure out where each part of the query image belongs in 3D.
- The network predicts 3D coordinates for many pixels in the query image—these are “where this pixel is in the scene.”
- It also predicts a confidence score for each point, to ignore uncertain areas like sky or shiny surfaces.
- Finally, it uses a standard geometry algorithm (PnP-RANSAC) to compute the camera’s exact position and orientation from the 2D-3D matches. In simple terms: if you know where enough points in the image are in 3D, you can solve where the camera must be.
- Keeping it fast with image retrieval
- Before localization, it quickly picks the top matching mapping images using a global image descriptor (image retrieval). This helps choose the most relevant features without heavy computation.
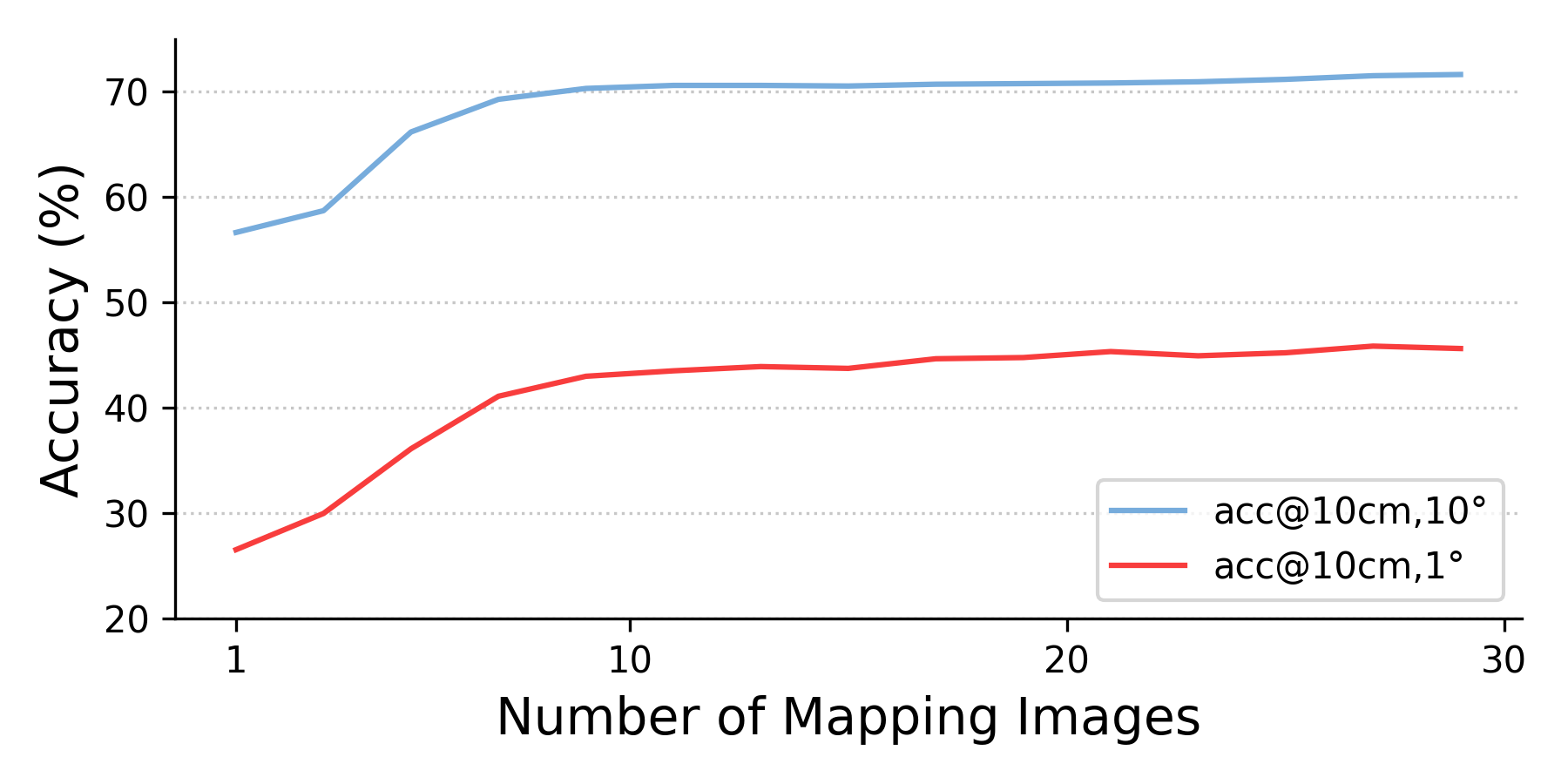
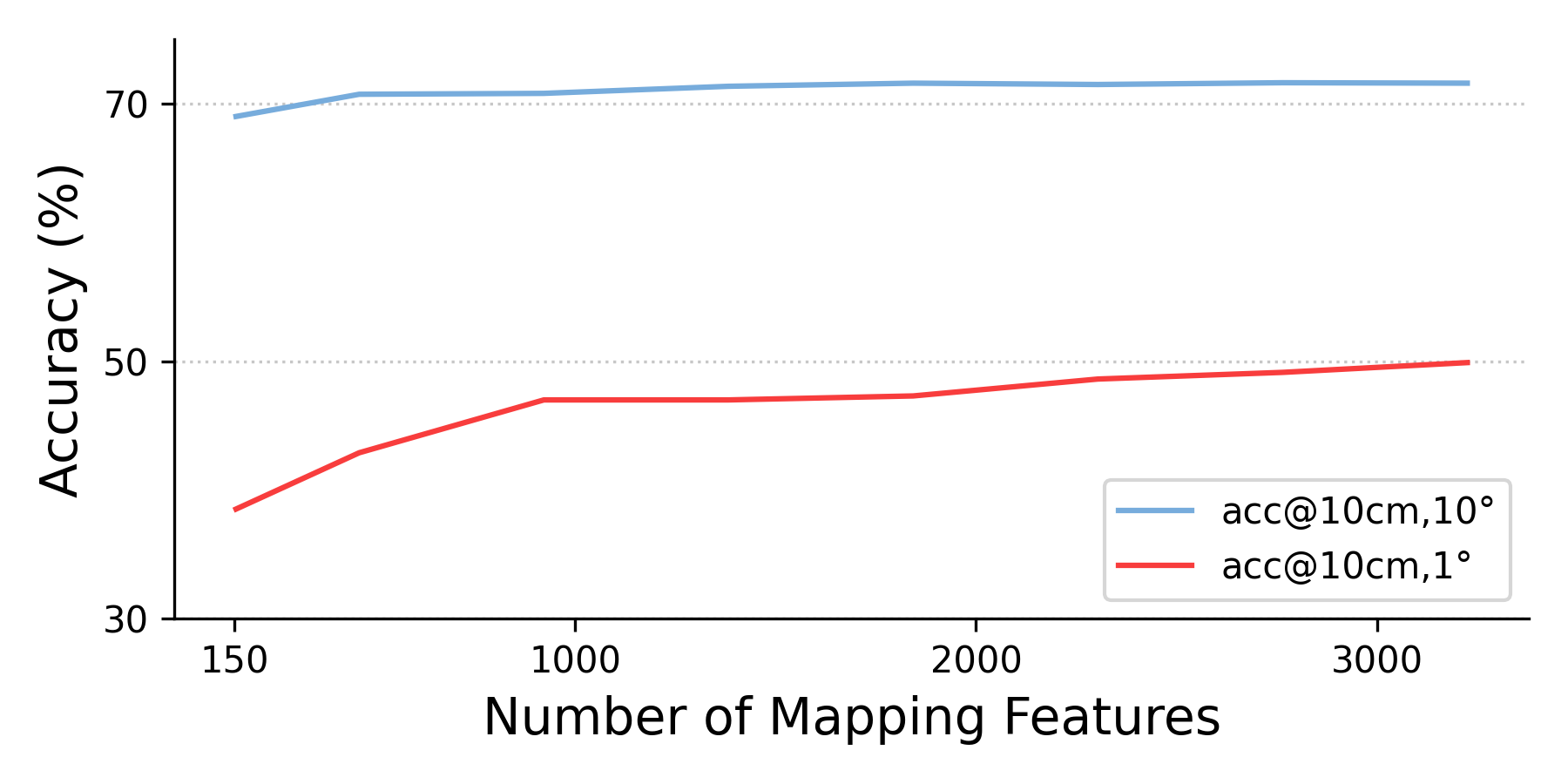
- Even if the scene has many mapping images, the runtime stays almost constant because it always samples the same number of features.
What did they find?
The authors tested FastForward on several datasets, comparing it to different types of methods:
- Structure-based methods: build a full 3D model of the scene (accurate but slow to prepare).
- SCR and APR methods: train a network per scene (moderately fast but need scene-specific training).
- RPR methods: estimate the camera relative to other photos (no per-scene training, but often less accurate).
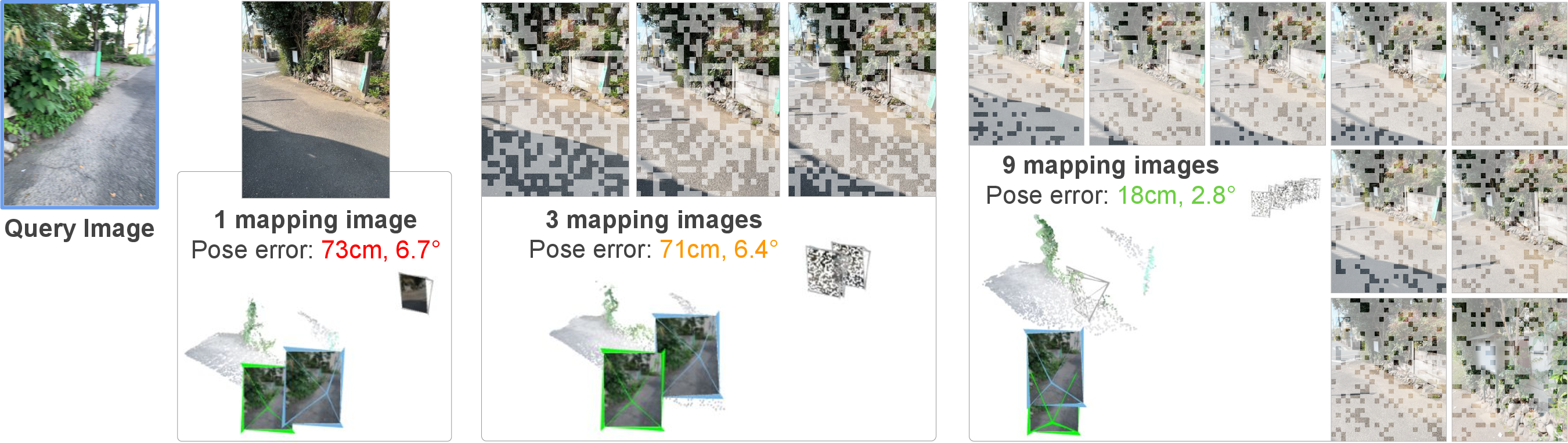
Across multiple benchmarks, FastForward:
- Cambridge Landmarks (outdoor, large scale)
- Achieved the best accuracy among methods that don’t need per-scene training (“Unseen” group), beating others like Reloc3r and MASt3R variants.
- Great at keeping translation errors low while being fast to prepare (only a quick retrieval step).
- Wayspots (small outdoor places)
- Strong improvement in translation accuracy (how far off the camera is), with much lower median errors than other methods.
- Map preparation took seconds versus minutes for training-based methods (ACE, GLACE).
- Indoor6 (indoor scenes with tricky lighting and repeating patterns)
- Highest acceptance rates under strict thresholds (10 cm, 10°), even surpassing methods that need hours of map building.
- RIO10 (indoor, changing over time)
- Competitive with top methods that use full images, and best at the more forgiving threshold (20 cm, 20°), showing robustness when the scene changes.
In short: FastForward is fast and accurate, especially compared to methods that don’t need per-scene preparation; and it’s competitive with heavier methods in many situations.
Why is this important?
This matters because it makes camera localization practical and scalable:
- Speed: It can localize a given image with just a single network pass, and map preparation is mostly just running a quick image retrieval—no hours-long 3D reconstruction or per-scene training.
- Efficiency: It uses only a few thousand features instead of full dense models, keeping memory and compute low.
- Generalization: The scale normalization lets the model handle scenes that are bigger or smaller than those it saw during training, including outdoor city spaces.
- Reliability: Predicting confidence scores helps avoid bad matches in tough areas.
What impact could this have?
- Augmented reality: Faster and more reliable placement of virtual objects in the real world without heavy scene setup.
- Robotics and navigation: Quick, accurate positioning using simple visual maps, useful for drones, robots, or phones.
- Large-scale mapping: Easier to expand to new places since minimal preparation is required.
- Energy and cost: Less compute and time means cheaper and greener deployments.
The authors also note that choosing mapping images (via retrieval) is important. Though retrieval is fast, future work could explore smarter ways to pick reference images without any retrieval at all. Still, FastForward shows that “a scene is worth a thousand features”—you don’t need a huge 3D model; a small, well-encoded set of features can be enough to locate a camera quickly and accurately.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The following points highlight what remains missing, uncertain, or unexplored in the paper, with concrete directions for future research:
- Robustness to mapping-pose errors is not evaluated; the method assumes accurate mapping poses. How sensitive is performance to pose noise, drift, or scale errors in SLAM/SfM-derived mapping poses?
- The retrieval step is external and not integrated; no joint optimization of retrieval, feature selection, and localization. Can retrieval be learned end-to-end with the localization network to select the most informative mapping images/features for a given query?
- Feature sampling from mapping images is purely random and uniform; no learned or geometric/semantic-informed sampling strategy. Would active/importance sampling, spatial coverage constraints, or uncertainty-aware selection improve accuracy and efficiency?
- Fixed-size map representation N is used irrespective of scene scale or map density. How to adaptively allocate N given scene complexity, coverage, and predicted query uncertainty, especially for city-scale maps?
- No analysis of the trade-off between N (map features), K (retrieved images), and accuracy/latency on diverse scene scales; only limited ablations (Appendix) are mentioned. Can we derive policies for adaptive K and N at runtime?
- The approach relies on known intrinsics and a pinhole model in ray encoding; effects of intrinsics errors, lens distortion, wide-FoV/fisheye, and rolling shutter are untested. How to make the method robust to unknown/approximate intrinsics and non-pinhole cameras?
- Scene/scale normalization uses max-translation s; robustness to outliers or degenerate camera distributions (e.g., linear trajectories) is not studied. Are robust scale estimators or learned normalization preferable?
- Metric scale recovery depends on mapping poses being metric; when SfM provides arbitrary scale, predicted metric pose remains ambiguous. Can auxiliary sensors (IMU/GNSS/barometer) or learned priors enforce real-world scale?
- Sensitivity to retrieval errors (low-overlap neighbors, visually confusing distractors) is only briefly tested; accuracy drops notably without retrieval. Are there retrieval confidence gates or query-conditioned map expansion strategies that mitigate failure?
- Handling of dynamic environments is limited; sparse map features may miss fine details needed under large scene changes (RIO10 observations). Can temporal reasoning, change detection, or semantics help discount moved objects and emphasize stable structures?
- The method predicts dense query 3D coordinates but uses PnP-RANSAC with up to 100k correspondences; computational cost, RANSAC parameter sensitivity, and on-device feasibility are not quantified. Can we prune correspondences with learned inlier scoring or use differentiable/iterative PnP to reduce cost?
- Confidence predictions are used for filtering but not calibrated or analyzed for reliability across domains; no study of calibration, threshold sensitivity, or uncertainty-aware PnP formulations.
- No explicit treatment of occlusions or visibility reasoning between query and mapping features; can learned visibility masks or geometric consistency checks reduce outliers?
- Mapping features are tied to a frozen DUSt3R encoder; impact of encoder choice, partial fine-tuning, adapters, or distillation for on-device constraints is not explored.
- Incremental mapping and lifelong operation are not addressed: how to insert/remove mapping images, refresh features, and maintain a compact map over time without costly recomputation?
- The ray encoding omits camera positional uncertainty and ignores higher-order effects (e.g., rolling shutter time offsets); alternative encodings (e.g., pose covariances, per-token positional embeddings) are not compared.
- No analysis of the effect of image resolution and ViT patch size (16) on fine-grained localization, especially for small or far structures; does multi-scale tokenization or super-resolution help?
- The mapping head is only a training-time supervisory MLP; enforcing multi-view consistency, cycle-consistency, or cross-head consistency at inference is not attempted. Could joint optimization of mapping and query heads improve stability?
- Failure modes are only qualitatively shown; there is no quantitative stratification by texture level, viewpoint change, lighting, or overlap, nor tail-risk analysis (catastrophic outliers) beyond medians.
- Hardware and runtime details are limited; end-to-end latency, memory footprint, and energy on mobile/edge devices compared to SCR/SfM/RPR baselines are not reported.
- Generalization to adverse conditions (nighttime, weather, severe illumination shifts) and extreme outdoor scales is not systematically evaluated; training data coverage vs. test conditions is unclear.
- The method assumes accurate query intrinsics for PnP; procedures for unknown or changing intrinsics at query time (e.g., web images) are not provided.
- The approach is tested on validation for RIO10 due to submission limits; test-set generalization remains unknown and comparisons are not conclusive.
- No semantic priors are used; can integrating semantics (e.g., building edges, ground planes) improve robustness to dynamics and repetitive patterns?
- Theoretical conditions for sufficiency of “a few hundred features” are not established; what scene complexity/visibility/overlap guarantees are required for reliable pose estimation?
- Map compression/quantization trade-offs and storage budget vs. accuracy are not analyzed; how small can the per-scene map be made for deployment without significant degradation?
- Comparison fairness across baselines’ mapping times and hardware is not fully standardized; reproducible, hardware-normalized mapping and inference budgets are missing.
- The method does not consider temporal continuity for video queries (tracking-based priors, pose smoothing, incremental refinement). Can multi-frame inference further reduce N and improve robustness?
- Robustness to severe occlusions and viewpoint extrapolation (query outside convex hull of mapping views) is not studied; how does performance degrade with reduced overlap?
- Potential integration with geometric verification (e.g., epipolar constraints) at feature level is not explored; can hybrid geometric-neural constraints improve outlier rejection before PnP?
Practical Applications
Below is an overview of practical, real-world applications enabled by the paper’s FastForward method for feed-forward camera localization from a sparse collection of 3D-anchored image features. Each item specifies sector(s), use case, potential tools/products/workflows, and assumptions/dependencies.
Immediate Applications
- Sectors: AR/VR, Entertainment, Retail, Tourism, Education Application: Rapid AR scene setup with “map-light” localization Description: Deploy location-based AR experiences (e.g., museum labels, retail signage, tourism guides) with minutes of prep by capturing a small set of mapping images with poses and running FastForward for reliable relocalization. Potential tools/workflows: “FastForward Localizer” SDK for Unity/Unreal/ARKit/ARCore; server- or edge-inference microservice; automatic image-retrieval (GeM-AP) to select top-K mapping images; content authors upload 20–100 mapping frames and publish an index. Assumptions/dependencies: Mapping images need poses (ARKit/ARCore/VIO/SLAM); camera intrinsics available; modest texture and viewpoint overlap; GPU or fast edge/Cloud inference; privacy-compliant handling of stored features.
- Sectors: Robotics (AMRs, drones), Warehousing, Manufacturing Application: Fast relocalization and SLAM re-initialization Description: Use FastForward as a drop-in relocalization module when VIO/SLAM tracking is lost, or to quickly tie a robot to a previously traversed map without full SfM. Potential tools/workflows: ROS node providing 6-DoF pose via 2D–3D correspondences + PnP-RANSAC; periodic “light mapping” lap to refresh the feature map; combine with odometry for filtering. Assumptions/dependencies: Initial mapping pass with reliable poses (and metric scale if needed); retrieval index built for the environment; sufficient scene texture; onboard compute or low-latency offboard service.
- Sectors: Energy/Utilities, Infrastructure Inspection, Telecom Application: UAV/UGV inspection localization with minimal pre-mapping Description: First flight builds a sparse feature map from posed frames; subsequent sorties localize quickly for repeated shot framing and change detection. Potential tools/workflows: Flight planner integration; batch build retrieval index post-flight; cloud-backed relocalization API for field devices. Assumptions/dependencies: Stable poses for mapping pass (e.g., GPS+VIO, RTK where available); consistent camera intrinsics; moderate viewpoint overlap; operational bandwidth for retrieval and inference.
- Sectors: AEC (Architecture, Engineering, Construction) Application: On-site device localization for BIM/AR overlays Description: Align mobile devices with design models without lengthy scanning, enabling quick measurements, issue tagging, and progress tracking. Potential tools/workflows: Site foreman captures a quick mapping walk; feature pack stored per floor/zone; AR viewer fetches top-K mapping images and runs FastForward to localize. Assumptions/dependencies: Metric scale is required if absolute measurements are needed; capture coverage of key viewpoints; dynamic changes (new walls/furniture) may require refreshing mapping images.
- Sectors: Media & VFX, Live Events Application: Markerless on-set camera tracking from a few stills Description: Use a sparse feature map of the set to localize production cameras for pre-viz and lightweight matchmoving without full photogrammetry. Potential tools/workflows: Plug-in for Nuke/Unreal/Blender; mapping session from stills with known intrinsics; live relocalization during takes. Assumptions/dependencies: Good calibration and intrinsics; limited scene reconfiguration during shots; feature-rich set elements.
- Sectors: Logistics, Retail Operations Application: Quick in-store AR planogram and signage alignment Description: Localize handheld devices against a sparse map to overlay product layouts and instructions with minimal store downtime. Potential tools/workflows: Store associates capture aisle images; back office auto-builds retrieval index; devices localize for audits and guided restocking. Assumptions/dependencies: Periodic refresh due to planogram changes; robust retrieval in repetitive environments; adequate lighting/texture.
- Sectors: Smart Campus/Hospitals/Airports Application: Pop-up indoor navigation and wayfinding Description: Volunteers or staff quickly capture mapping images to enable localization-based guidance for visitors, with minimal infrastructure. Potential tools/workflows: Capture app to build feature packs per corridor/floor; web dashboard to manage retrieval indices; client app for live assist. Assumptions/dependencies: Sufficient coverage; signage or landmarks with texture; accessibility and privacy compliance.
- Sectors: SLAM/Mapping Software Application: Pose prior and correspondence seeding for SfM/VIO Description: Use predicted scene coordinates and confidences to seed PnP in mapping pipelines, improving robustness and cutting compute. Potential tools/workflows: Integrate FastForward outputs as initial correspondences; adaptive sampling of mapping features; fall back to standard matching when confidence is low. Assumptions/dependencies: Consistent intrinsics; calibrated confidence thresholds; retrieval quality affects correspondence validity.
- Sectors: Security/Forensics Application: Image geolocation within a known facility Description: Place a query frame within a pre-captured environment to verify location claims or reconstruct sequences. Potential tools/workflows: Controlled capture to build feature maps of critical areas; casework app performing retrieval + relocalization for submitted imagery. Assumptions/dependencies: Legal/privacy constraints; stable scene appearance; known intrinsics or calibration procedure.
- Sectors: Academia (CV, Robotics, HCI) Application: Rapid prototyping and benchmarking for localization research Description: Use FastForward as a strong retrieval-based baseline that needs no per-scene training; test generalization and scale normalization strategies. Potential tools/workflows: Open-source pipeline wrapper; ready-to-run retrieval indices for standard datasets; ablation tooling for N and top-K. Assumptions/dependencies: Datasets with camera poses and intrinsics; GPU availability for fair comparisons.
Long-Term Applications
- Sectors: AR Cloud, Platforms, Telecommunications Application: City-scale “feature-only” AR clouds with low map overhead Description: Maintain vast, continuously updated localization maps by storing sparse 3D-anchored features and retrieval indices, enabling scalable, fast onboarding. Potential tools/workflows: Distributed retrieval services; incremental map refreshing from crowd-sourced captures; feature aging/pruning policies. Assumptions/dependencies: Scalable distributed indices; strong privacy and data governance; robust handling of dynamic scenes and seasonal appearance.
- Sectors: Automotive, Mobility, Smart Infrastructure Application: Map-light, camera-based localization for GPS-denied or complementary positioning Description: Provide lane-level relocalization without full HD map dependency by leveraging sparse features along routes. Potential tools/workflows: Fleet data to bootstrap and refresh feature maps; fusion with GNSS/IMU; backend monitoring of drift and coverage gaps. Assumptions/dependencies: Road-scale retrieval at low latency; domain adaptation for weather/night; safety certification and redundancy requirements.
- Sectors: Consumer Devices, Edge AI Application: Fully on-device feed-forward localization Description: Run a compressed FastForward variant on smartphones/glasses for offline localization and privacy-preserving AR. Potential tools/workflows: Model distillation/quantization; NPU/GPU acceleration; on-device retrieval with compact global descriptors. Assumptions/dependencies: Sufficient device compute; energy constraints; high-quality mobile intrinsics and distortion handling.
- Sectors: Robotics Swarms, Industrial IoT Application: Collaborative, bandwidth-efficient mapping and relocalization Description: Robots exchange small feature packs instead of dense maps to align and coordinate across teams or shifts. Potential tools/workflows: Standardized “feature-pack” schema (3D coordinates, ray encodings, confidences); edge caching and versioning. Assumptions/dependencies: Interoperable map format; reliable comms; mechanisms for conflict resolution and map merging.
- Sectors: Emergency Response, Public Safety Application: Rapidly deployable localization in disaster zones Description: First responders capture a quick pass to build a sparse map; teams localize devices for navigation and situational awareness in GPS-denied, cluttered environments. Potential tools/workflows: Ruggedized capture kits; offline retrieval; mesh-networked inference nodes. Assumptions/dependencies: Extreme appearance/dynamics; debris occlusions; need for robust failure detection and human-in-the-loop validation.
- Sectors: Digital Twins, Facilities Management Application: Continuous sensor/camera re-localization to maintain alignment with the twin Description: Use lightweight feature maps to keep heterogeneous sensors anchored over months/years with frequent layout changes. Potential tools/workflows: Scheduled refresh captures; automated accuracy monitoring; alerts for re-mapping needs. Assumptions/dependencies: Change detection triggers; policies for archival and versioned maps; interoperability with BIM/IFC standards.
- Sectors: Standards, Policy, Privacy Application: Map-light AR data governance and interoperability standards Description: Define standards for sparse feature maps (metadata, storage, retention, consent) to balance capability with privacy and vendor interoperability. Potential tools/workflows: Reference compliance profiles; audit tools for feature maps; anonymization guidelines. Assumptions/dependencies: Multi-stakeholder consensus; evolving privacy regulations; technical proofs of privacy risks/mitigations.
- Sectors: Research (Foundations, Multimodal 3D) Application: Retrieval-free or active mapping selection via unified 3D perception models Description: Extend FastForward with agents that select or synthesize “best” mapping features on the fly, reducing reliance on pre-built retrieval. Potential tools/workflows: Memory-augmented transformers; cross-scene adapters; self-supervised map compression. Assumptions/dependencies: Advances in foundation 3D models; efficient memory mechanisms; robust generalization to highly dynamic scenes.
Notes on common assumptions and dependencies across applications:
- Mapping poses: If obtained from monocular SLAM/VIO with unknown scale, absolute metric accuracy will reflect that scale; for measurement-critical use, ensure metric calibration (stereo/Depth/RTK or surveyed references).
- Camera intrinsics and distortion: Accurate intrinsics are needed for the ray encoding and PnP; device- or session-level calibration is recommended.
- Retrieval quality: Image retrieval must return overlapping views; accuracy degrades with poor retrieval or insufficient mapping coverage; performance can be improved by increasing top-K or N (feature sample size) at higher compute cost.
- Compute and latency: Current model sizes favor GPU/edge servers; on-device use likely requires model compression and hardware acceleration.
- Scene dynamics and appearance changes: Frequent updates to mapping images or adaptive feature selection improve robustness; highly dynamic environments may benefit from multi-view inputs.
Glossary
- 2D-3D correspondences: Paired matches between 2D image points and 3D scene points used to estimate camera pose. "we compute the set of 2D-3D correspondences"
- Absolute Pose Estimation: The task of determining a camera’s position and orientation in a global scene frame. "Absolute Pose Estimation."
- Absolute Pose Regression (APR): Learning-based approach that directly predicts a camera’s absolute pose from an image. "absolute pose regression (APR)"
- Active Search (AS): A structure-based localization method that efficiently matches image features to a 3D model. "Active Search (AS)"
- Camera intrinsics: Parameters defining the internal characteristics of a camera (e.g., focal length, principal point). "K_k are the camera intrinsics"
- Confidence-based loss: A training objective that weights errors by predicted confidence and regularizes confidence values. "We adopt DUSt3R's confidence-based loss"
- Cross-attention: Transformer mechanism that lets one set of tokens attend to another set, enabling interaction between modalities or inputs. "The decoder incorporates cross-attention blocks between the self-attention and the MLP layers."
- Descriptor matching: Establishing correspondences by comparing learned feature descriptors. "descriptor head that improves correspondence accuracy through descriptor matching."
- DPT head: A decoder head (from Dense Prediction Transformer) used to produce dense predictions like 3D coordinates. "we use a DPT head"
- DUSt3R: A foundation model that predicts aligned point maps from image pairs and serves as a backbone for features. "We initialize the encoder with a pre-trained DUSt3R model"
- Euclidean distance: The standard L2 distance measure in 3D space used for regression losses. "We define the regression loss as the Euclidean distance"
- Feed-forward pass: A single forward computation through a network without iterative optimization or per-scene training. "a single feed-forward pass."
- Fourier encoding: A positional encoding technique using sinusoidal functions to represent continuous variables like rays. "we use a Fourier encoding"
- GeM-AP: A global image descriptor (Generalized Mean pooling with AP loss) for efficient image retrieval. "we use GeM-AP"
- Image retrieval: Finding nearest neighbor images in a database using global descriptors to reduce search space. "We couple FastForward with image retrieval"
- MASt3R: A DUSt3R-based model with additional heads for matching and 3D points, used for localization and SfM. "MASt3R"
- Mapping features: Feature tokens extracted from mapping images that are anchored in 3D and used as a compact scene representation. "FastForward utilizes these mapping features"
- MLP: A multi-layer perceptron used here as a lightweight prediction head. "we use a single MLP layer"
- Multi-view triangulation: Estimating 3D points from multiple images by intersecting viewing rays. "through multi-view triangulation"
- PnP-RANSAC: A robust pose estimation pipeline combining Perspective-n-Point with RANSAC to handle outliers. "PnP-RANSAC"
- Ray embedding: A feature augmentation that encodes the camera origin and viewing direction of each mapping feature. "Each mapping feature is augmented with a ray embedding"
- Ray encoding: Encoding of a feature’s originating camera pose and pixel ray for geometric context. "we use a ray encoding that represents its 3D position and orientation"
- Relative Pose Regression (RPR): Predicting the relative transformation between a query and reference image(s) instead of absolute pose. "relative pose regression (RPR)"
- Robust estimator: An algorithm designed to be resilient to outliers when fitting models like camera pose. "A robust estimator can be applied"
- Scene coordinate regression (SCR): Predicting, for each query pixel, its corresponding 3D scene coordinate to derive pose. "scene coordinate regression (SCR)"
- Scene normalization: Transforming scene coordinates to a common canonical frame to stabilize learning across scenes. "a simple yet effective scene normalization technique."
- Scale normalization: Normalizing translation magnitudes to a fixed range to handle metric and non-metric data consistently. "scale normalization makes the network more robust"
- Self-attention: Transformer mechanism where tokens attend to each other within the same sequence to aggregate context. "composed of self-attention and MLP layers"
- Structure-based localization: Approaches that rely on a pre-built 3D model of the scene for pose estimation. "Structure-based Localization requires building a 3D model of the scene."
- Structure-from-Motion (SfM): Pipeline to reconstruct camera poses and 3D structure from overlapping images. "These models are typically created by SfM software"
- Tokenization: Converting an image into a sequence of patches/tokens for transformer processing. "which tokenizes the images"
- Transformer: A neural network architecture using attention mechanisms for modeling relationships among tokens. "Transformer models look at the whole image"
- Triangulation: Computing 3D point positions from two or more views by intersecting rays. "feature triangulation with SfM can take several hours"
- Vision Transformer (ViT): A transformer-based architecture for image representation using patch tokens. "we utilize the ViT ... architecture"
Collections
Sign up for free to add this paper to one or more collections.

