- The paper reveals that just-in-time personalization in LLMs leads to 29.0% of attempts producing poorer alignment due to overcorrection and limited strategic questioning.
- The paper introduces PrefDisco, a novel benchmark that transforms static evaluations into interactive tasks by simulating realistic, psychologically-grounded user personas.
- The paper highlights domain-specific brittleness, showing that while social reasoning remains robust, mathematical tasks suffer from degraded performance when personalized.
Personalized Reasoning: Just-In-Time Personalization and Why LLMs Fail At It
Introduction
The paper "Personalized Reasoning: Just-In-Time Personalization and Why LLMs Fail At It" explores the limitations of current LLMs in personalized reasoning, which is critical for properly aligning AI responses with user needs, particularly in cold-start scenarios where prior interaction history is unavailable. LLMs are traditionally optimized for task-solving correctness and alignment to generalized human preferences, but this approach neglects the intricacies of realtime personalization required for tailored user interactions.
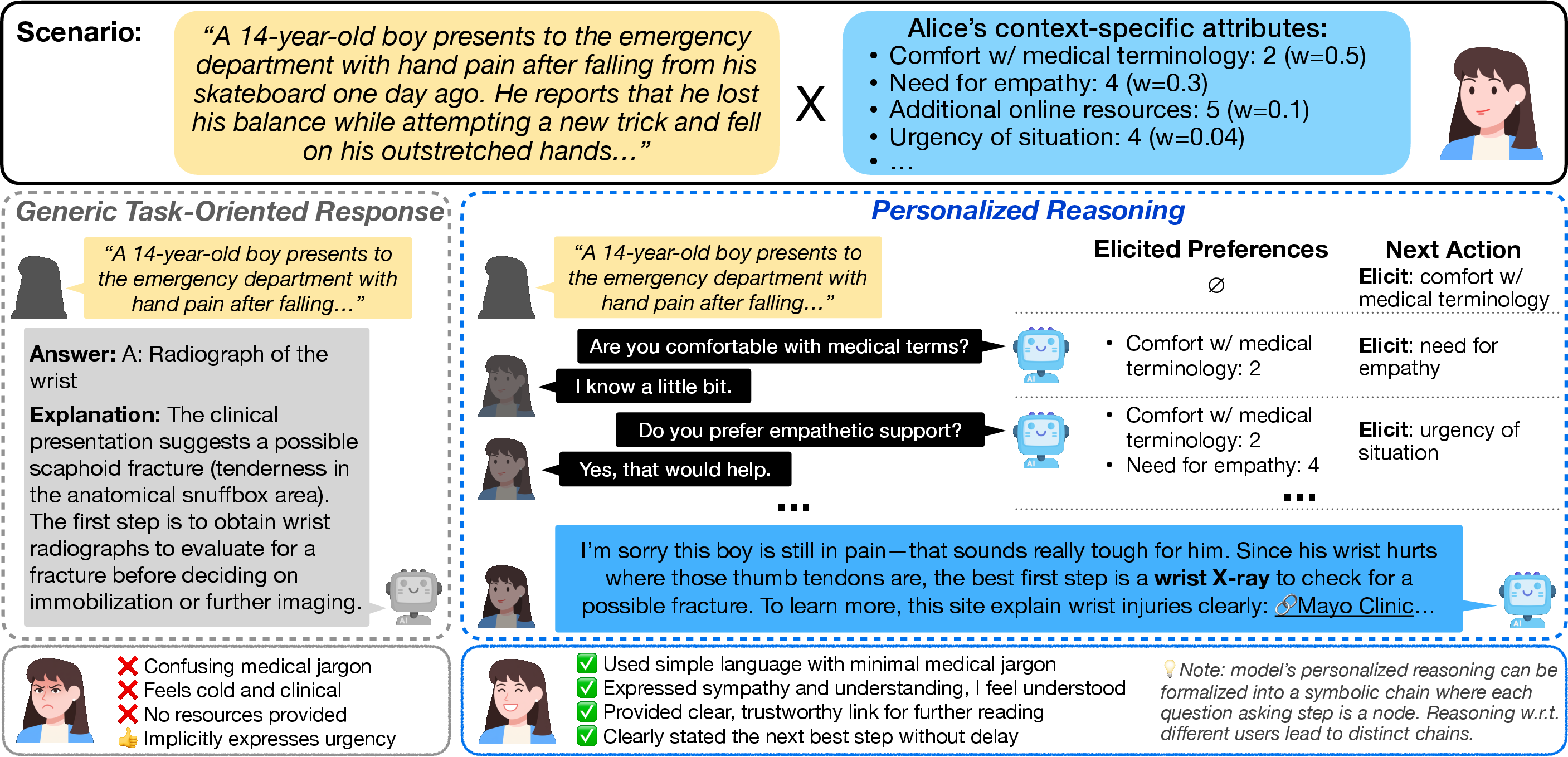
Figure 1: Personalized reasoning in a medical scenario. Current LLMs provide generic responses without considering the user (left); a model with personalized reasoning capabilities incorporates discovered preferences to provide responses that is both correct and aligned to the user (right).
PrefDisco Benchmark
To address the shortcomings of existing personalization research, the authors introduce PrefDisco, a groundbreaking evaluation methodology that transforms static benchmarks into interactive personalization tasks. PrefDisco leverages psychologically-grounded personas that simulate realistic user preferences, requiring LLMs to discover and adapt to user needs through strategic questioning in cold-start situations. This framework effectively challenges models to engage in active preference elicitation and personalized reasoning.
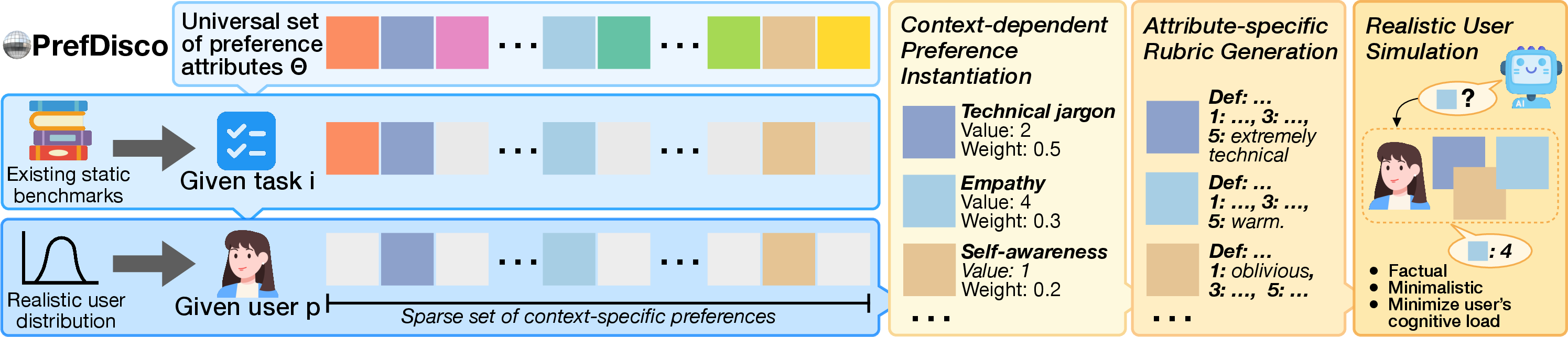
Figure 2: PrefDisco benchmark construction pipeline. The framework transforms static benchmarks by sampling sparse, context-dependent preference subsets for each user-task pair, generating attribute-specific evaluation rubrics, and implementing realistic user simulation that requires models to discover preferences through "just-in-time" strategic questioning in cold-start scenarios.
The evaluation of 21 frontier models across multiple reasoning tasks revealed critical insights into the models' personalization capabilities. Notably, a significant portion (29.0%) of attempted personalization endeavors led to worse preference alignment than providing generic responses. Current LLMs tend to overcorrect when personalization is attempted, leading to suboptimal alignment. This inadequacy is rooted in limited strategic questioning capabilities and insufficient exploration of user preferences.
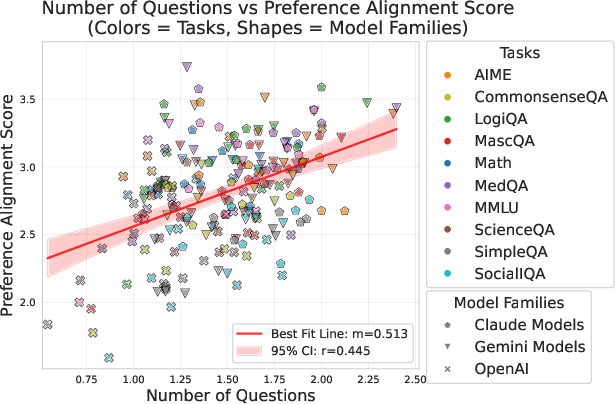
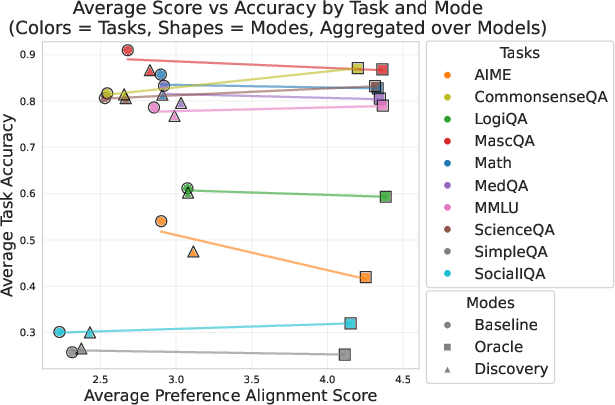
Figure 3: Positive correlation (r=0.445) between question volume and preference alignment. Better personalization requires more extensive questioning. Regression coefficients: Claude=0.117, OpenAI=0.379, Gemini=0.474.
Personalized Reasoning vs. Generic Responses
While some models achieved reasonable performance in generic response settings, their personalization efficacy revealed domain-based brittleness. Specifically, mathematical reasoning tasks showed degradation when attempts to personalize were undertaken, while social reasoning maintained robustness. This disparity highlights the importance of domain-specific strategies in building robust personalized reasoning capabilities.
The alignment between questioning volume and preference satisfaction underscores the necessity of effective questioning strategies. Models that asked more targeted questions achieved higher personalization scores, indicating that the current limitations lie not only in question quantity but in the quality and strategic value of interactions.
Implications and Future Research
The results of this study have significant implications for the development of LLMs capable of personalized reasoning. Integrating real-time preference discovery and contextual adaptation into the cognitive processes of LLMs is pivotal for enhancing user interaction quality in applications like education, healthcare, and technical support.
Further research should focus on developing advanced querying strategies to enhance preference elicitation, evaluating domain-specific personalization tactics, and exploring cross-task preference transfer techniques. These directions will pave the way for creating adaptive AI systems capable of naturally embedding personalized reasoning within their operational frameworks.
Conclusion
"Personalized Reasoning: Just-In-Time Personalization and Why LLMs Fail At It" provides a crucial evaluation of LLMs' personalization limitations and introduces PrefDisco as a robust benchmark for interactive reasoning assessment. By highlighting the current challenges and setting a foundation for future advancements, this work steers AI research toward developing systems that can dynamically adapt to individual user preferences and improve the quality of human-AI interactions in real-world settings.

