- The paper introduces MultiOOP, a benchmark evaluating LLMs on object-oriented programming across six languages with 267 tasks per language.
- It presents an automated test case generation framework and extends metrics to capture both syntactic correctness and structural OOP fidelity using pass@$o$.
- Results reveal significant performance drops and language biases, underscoring the need for models with improved cross-language generalization.
MultiOOP: A Multilingual Object-Oriented Programming Benchmark for LLMs
Motivation and Benchmark Design
The paper addresses critical deficiencies in existing code generation benchmarks for LLMs, specifically their lack of multilingual coverage, focus on function-level tasks, and insufficient test case diversity. Over 85% of prior benchmarks are single-language, 94% target only function-level or statement-level tasks, and most have fewer than ten test cases per problem. This narrow scope fails to capture the complexity and generalization required for robust object-oriented programming (OOP) code generation across languages.
To remedy these gaps, the authors introduce MultiOOP, a benchmark spanning six major OOP languages: Python, PHP, C++, C#, Java, and JavaScript, with 267 tasks per language. The benchmark is constructed by translating a single-language OOP benchmark into multiple languages using a custom translator, ensuring semantic and syntactic fidelity. The translation process is divided into three stages: requirement description translation, unit test translation, and matching function adaptation.
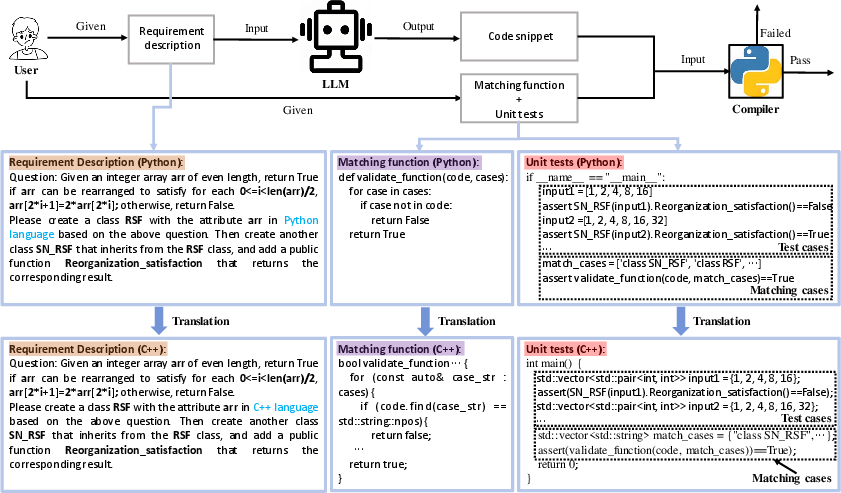
Figure 1: The MultiOOP benchmark construction pipeline, illustrating translation of requirements, unit tests, and matching functions for cross-language evaluation.
The benchmark selection process prioritizes semantic equivalence and language-agnostic design, filtering out tasks that rely on language-specific constructs (e.g., Python list comprehensions, multiple inheritance) to ensure compatibility and fairness across all target languages. The final dataset covers core OOP concepts such as classes, inheritance, encapsulation, and polymorphism.
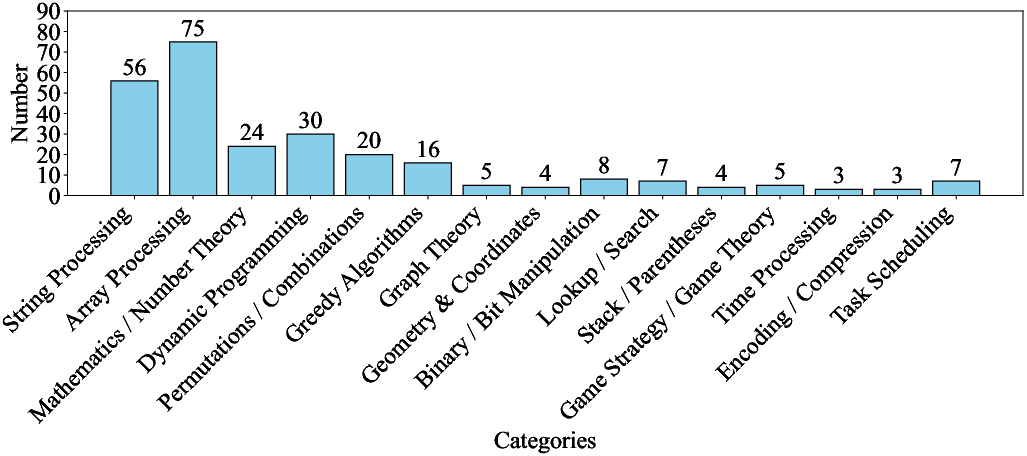
Figure 2: Distribution of categories in the filtered OOP benchmark, highlighting coverage of key OOP concepts.
Automated Test Case Generation and Evaluation Metrics
Recognizing the limitations of prior benchmarks with few test cases, the authors develop an automated framework for generating diverse and comprehensive test cases. This framework leverages LLMs to synthesize new test cases, validates them for correctness, and translates them into all target languages, resulting in an average of 20 test cases per problem.
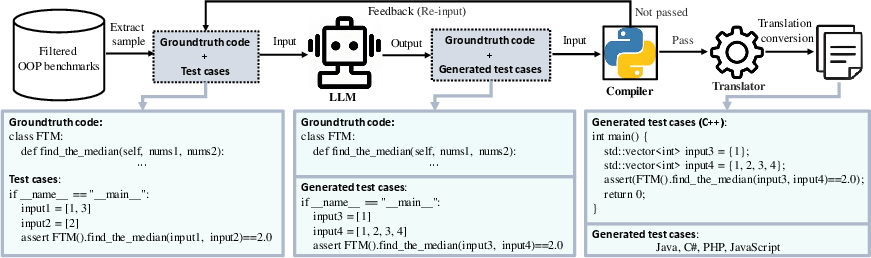
Figure 3: Automated framework for generating and validating test cases across multiple languages.
For evaluation, the paper extends the pass@k metric (which measures the fraction of problems solved by at least one of k generated solutions passing all test cases) to the pass@o metric. The pass@o metric imposes stricter requirements: generated code must not only pass all test cases but also match key OOP constructs specified in the natural language prompt (e.g., class names, method signatures). This ensures that LLMs are evaluated on both functional correctness and structural fidelity to OOP paradigms.

Figure 4: Matching key points between natural language and program description in the pass@o metric.

Figure 5: Extension of pass@o matching to multiple languages, exemplified with C++.
Experimental Results and Analysis
The benchmark is used to evaluate 14 mainstream LLMs, including both general-purpose and code-specialized models, under zero-shot, zero-shot CoT, and few-shot prompting. The results reveal several strong and contradictory findings:
- Substantial performance degradation: LLMs exhibit up to 65.6 percentage point drops in pass@$1$ scores on MultiOOP compared to function-level benchmarks (e.g., HumanEval).
- Cross-language variability: GPT-4o mini achieves pass@$1$ of 48.06% in Python but only 0.12–15.26% in other languages, indicating limited multilingual generalization.
- Conceptual gaps: pass@o scores are consistently 1.1–19.2 points lower than pass@k, demonstrating that LLMs often generate executable code without fully capturing core OOP concepts.
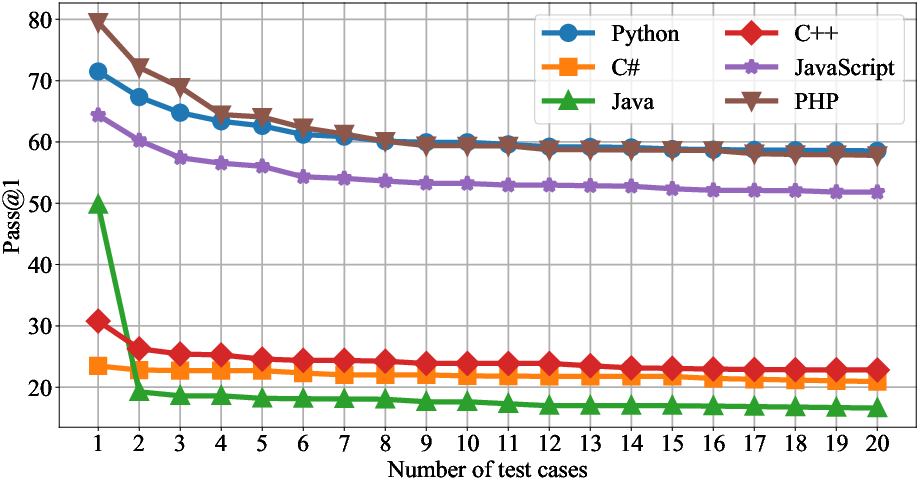
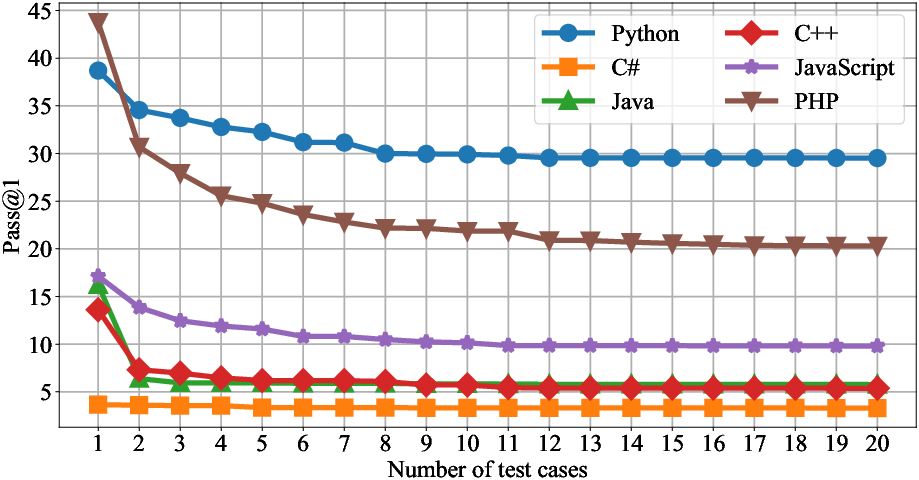
Figure 6: Performance of GPT-4o mini across languages, illustrating strong results in Python and sharp drops elsewhere.
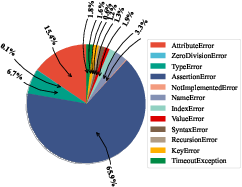
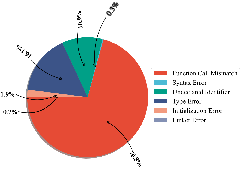
Figure 7: Python-specific performance distribution, highlighting the language bias of current LLMs.
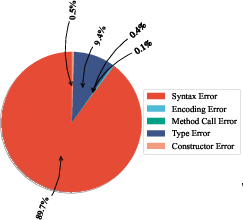
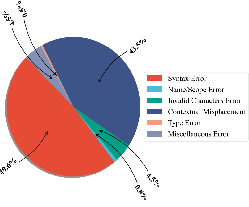
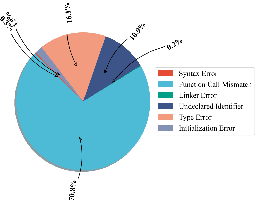
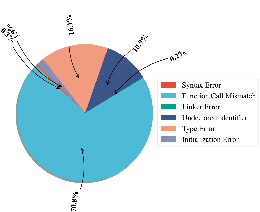
Figure 8: Java-specific performance, showing low pass@$1$ and pass@o scores for most LLMs.
The error analysis reveals that common failure modes differ by language: AssertionError, AttributeError, and TypeError in Python; Function Call Mismatch, Type Error, and Undeclared Identifier in C++; Syntax and Type Errors in Java, C#, PHP, and JavaScript. These errors reflect both syntactic limitations and insufficient semantic understanding of OOP constructs.
Prompting strategies have a significant impact: few-shot prompting yields substantial improvements (up to 94% relative gain in pass@$1$ for Qwen2.5-14b-Instruct in Python), while zero-shot CoT prompting provides moderate gains in select languages.
Increasing the number of test cases leads to more reliable evaluation, with performance scores stabilizing only after 15–18 test cases per problem.
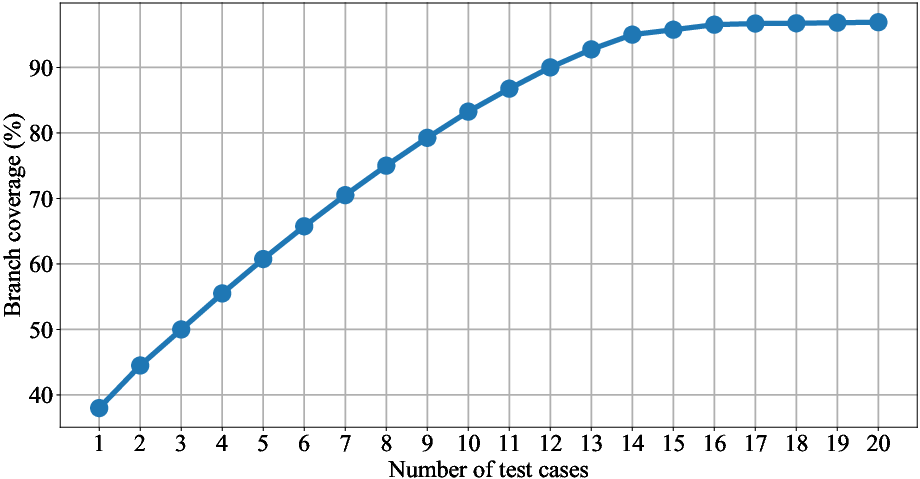
Figure 9: Branch coverage increases with the number of test cases, plateauing at 18, justifying the benchmark's test case design.
Implications and Future Directions
The MultiOOP benchmark exposes critical limitations in current LLMs' ability to generalize OOP code generation across languages and to faithfully implement OOP concepts. The lack of correlation between language popularity and LLM performance suggests that training data diversity and quality are more influential than real-world usage frequency. The persistent gap between pass@k and pass@o scores highlights the need for models that not only generate syntactically valid code but also adhere to user-specified structural requirements.
Practically, MultiOOP provides a robust, contamination-resistant framework for evaluating LLMs in realistic, multilingual OOP scenarios. The automated test case generation and rigorous metric design set a new standard for benchmark reliability and comprehensiveness.
Theoretically, the results suggest that further advances in LLM architecture, training data curation, and cross-language representation learning are required to close the gap in OOP code generation. Future work should focus on expanding the benchmark to additional languages, increasing task complexity, and developing models with explicit structural reasoning capabilities.
Conclusion
The MultiOOP benchmark represents a significant step toward fair, multilingual, and conceptually rigorous evaluation of LLMs in object-oriented code generation. The findings demonstrate that current LLMs are far from mastering OOP across languages, with strong language biases and conceptual gaps. The benchmark's design and results will inform future research on LLM training, evaluation, and deployment in software engineering contexts, and highlight the need for models that can robustly generalize OOP principles in diverse programming environments.

