- The paper introduces MSG, a multi-stream, object-centric framework that reduces demonstration requirements by up to 95% in robotic manipulation tasks.
- It leverages ensemble and flow composition strategies to integrate local models, leading to an 89% improvement over single-stream approaches.
- MSG demonstrates robust zero-shot transfer using keypoint-based object estimation and validates its performance on both simulated and real-world tasks.
Multi-Stream Generative Policies for Sample-Efficient Robotic Manipulation
Introduction and Motivation
The paper introduces Multi-Stream Generative Policy (MSG), a framework for sample-efficient robotic manipulation that leverages object-centric, multi-stream policy learning within generative models. The motivation stems from the observation that while generative policies such as Diffusion and Flow Matching can model complex, multimodal behaviors, they are typically sample-inefficient, often requiring on the order of 100 demonstrations to achieve robust performance. In contrast, probabilistic, object-centric approaches can generalize from as few as five demonstrations by structuring learning around multiple object-centric streams. MSG extends this principle to generative policy learning, enabling inference-time composition of multiple object-centric models to improve both generalization and sample efficiency.
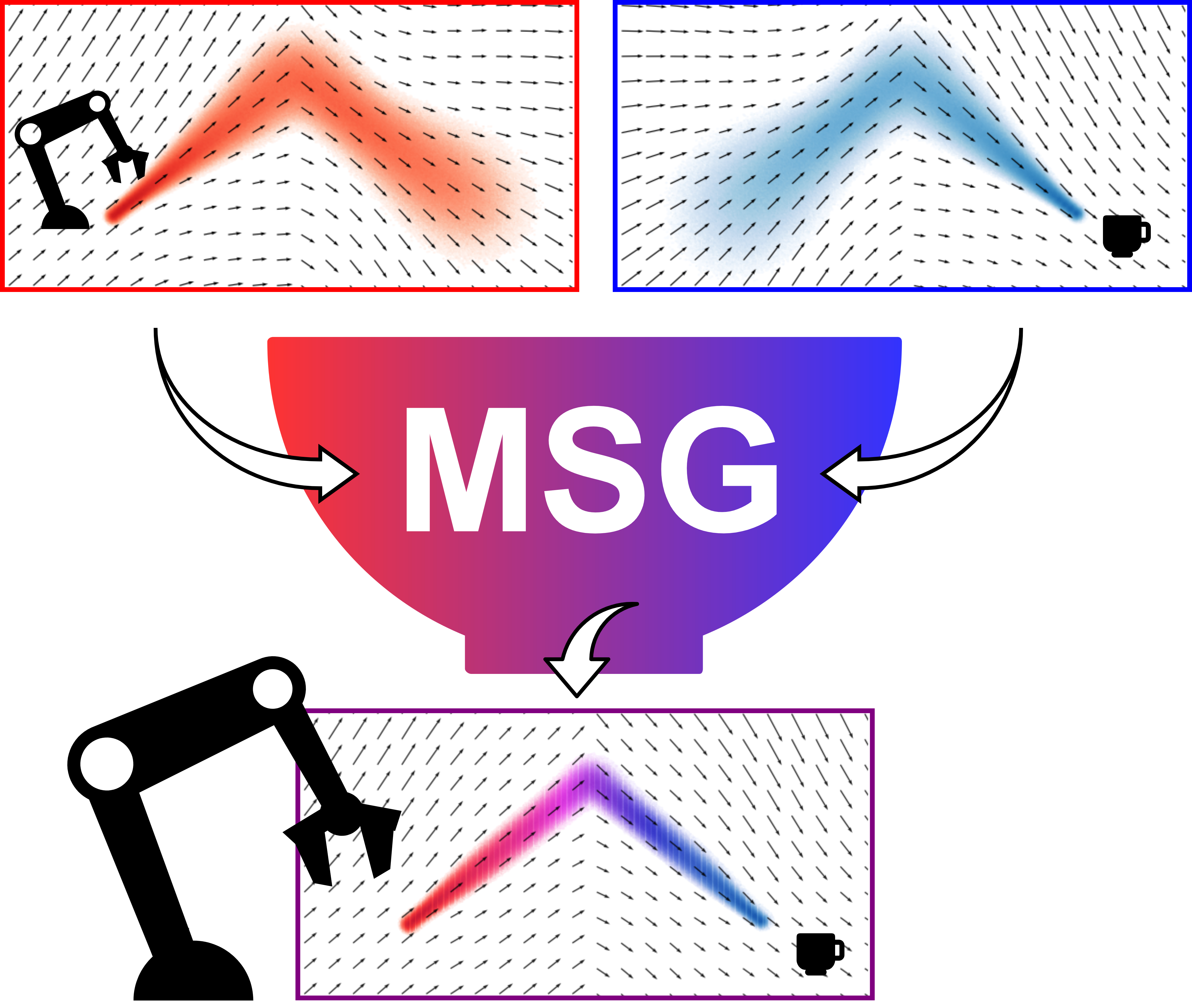
Figure 1: MSG learns high-quality policies from as few as five demonstrations by composing multiple object-centric models at inference, enabling sample-efficient generalization.
Technical Approach
Multi-Stream Object-Centric Policy Learning
MSG decomposes the policy learning problem into multiple object-centric streams, each modeling the robot's end-effector trajectory in a local coordinate frame associated with a task-relevant object or the robot itself. Each stream is trained independently using generative policy learning (e.g., Flow Matching), and at inference, the local models are transformed into the world frame and composed to yield a joint policy.
The key insight is that different object-centric frames provide complementary information at different stages of a manipulation task. For example, in the OpenMicrowave task, the end-effector frame is informative during the approach, while the microwave frame becomes critical during the interaction phase. The combined model maintains high precision throughout the trajectory by leveraging the most informative stream at each stage.
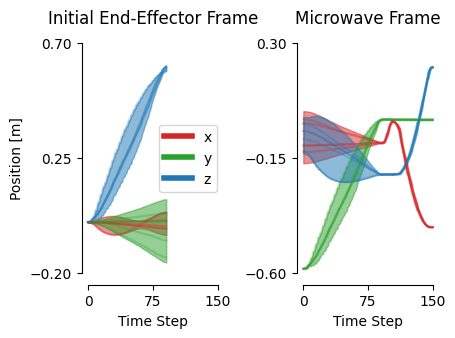
Figure 2: The informativeness of local models varies over the trajectory; the combined model maintains high precision by leveraging the most relevant stream at each time step.
Inference-Time Model Composition
MSG is model-agnostic and operates entirely at inference, making it compatible with a range of generative policy frameworks. The composition of object-centric models is performed via two main strategies:
- Ensemble-Based Composition: Each stream generates a sample in its local frame, which is transformed to the world frame and combined via a weighted sum (using geodesic interpolation for pose). This approach is effective for unimodal, near-Gaussian distributions.
- Flow Composition: The vector fields predicted by each stream are combined at each integration step, allowing the flows to guide the sample towards a common mode. This is particularly advantageous for multimodal distributions and can be further enhanced with MCMC-based sampling.
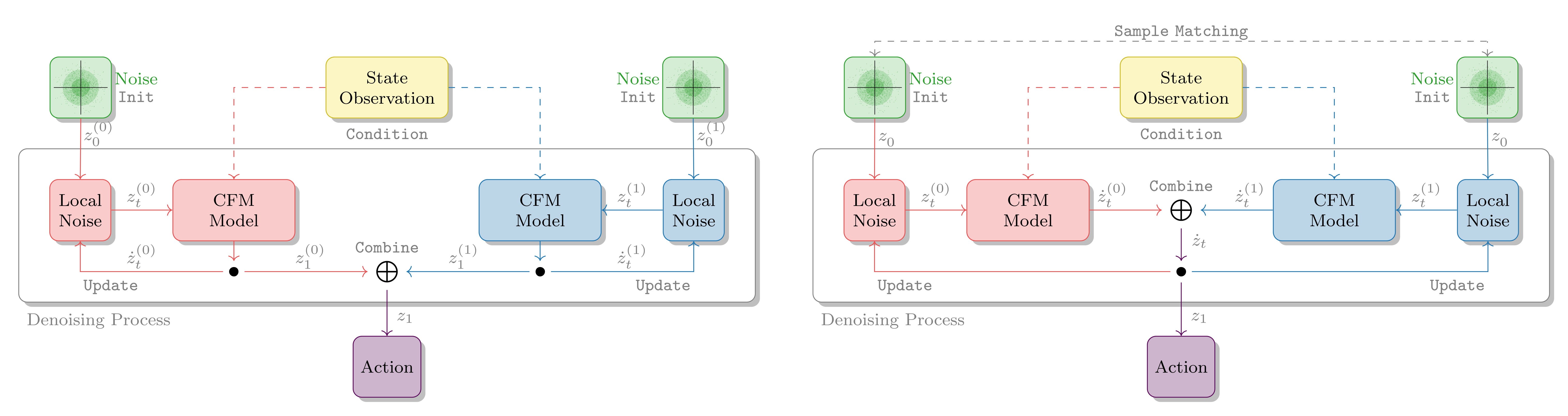
Figure 3: The ensemble approach integrates the individual streams before composing them, while flow composition jointly integrates the flow fields at each step.
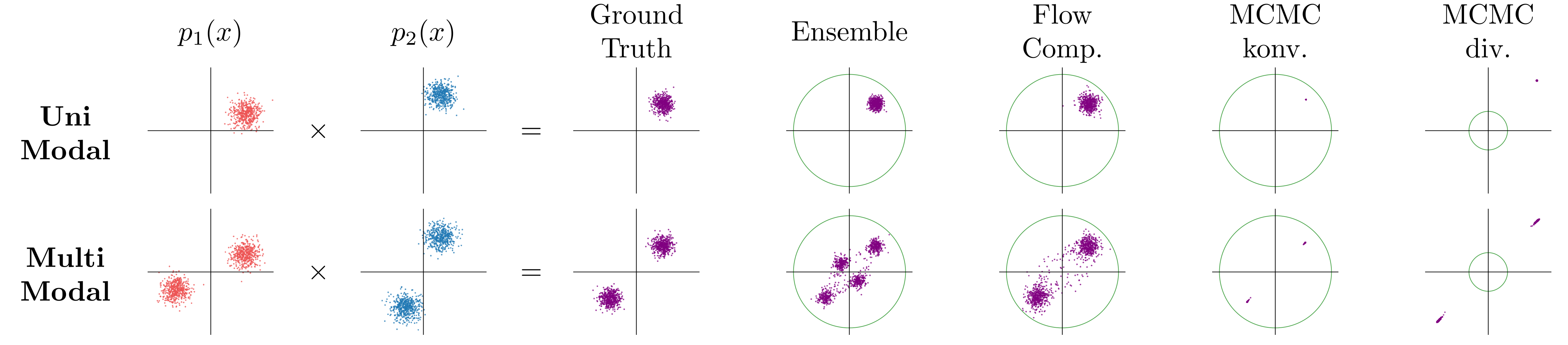
Figure 4: For unimodal targets, the ensemble approximates the product distribution well; for multimodal targets, flow composition (with MCMC) encourages convergence to a common mode.
Stream Weighting Strategies
MSG supports several strategies for weighting the contribution of each stream during composition:
- Progress-Based Scheduling: Weights are scheduled as a function of predicted skill progress (e.g., exponential, linear, threshold).
- Variance-Based Weighting: Each stream predicts its own uncertainty (log variance), and weights are assigned inversely proportional to variance.
- Parallel Sampling: Multiple particles are propagated in parallel, and empirical variances are used to compute weights.
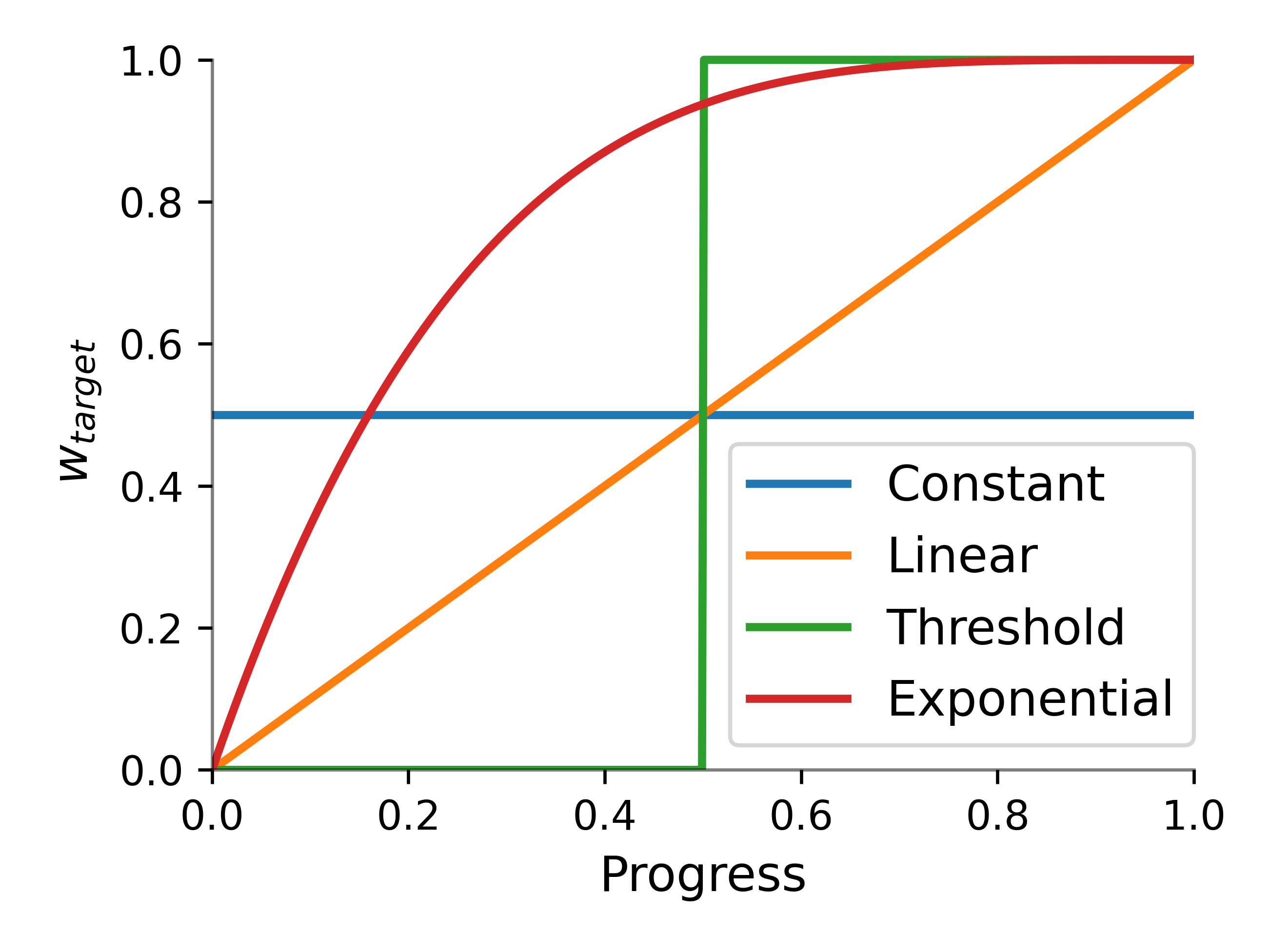
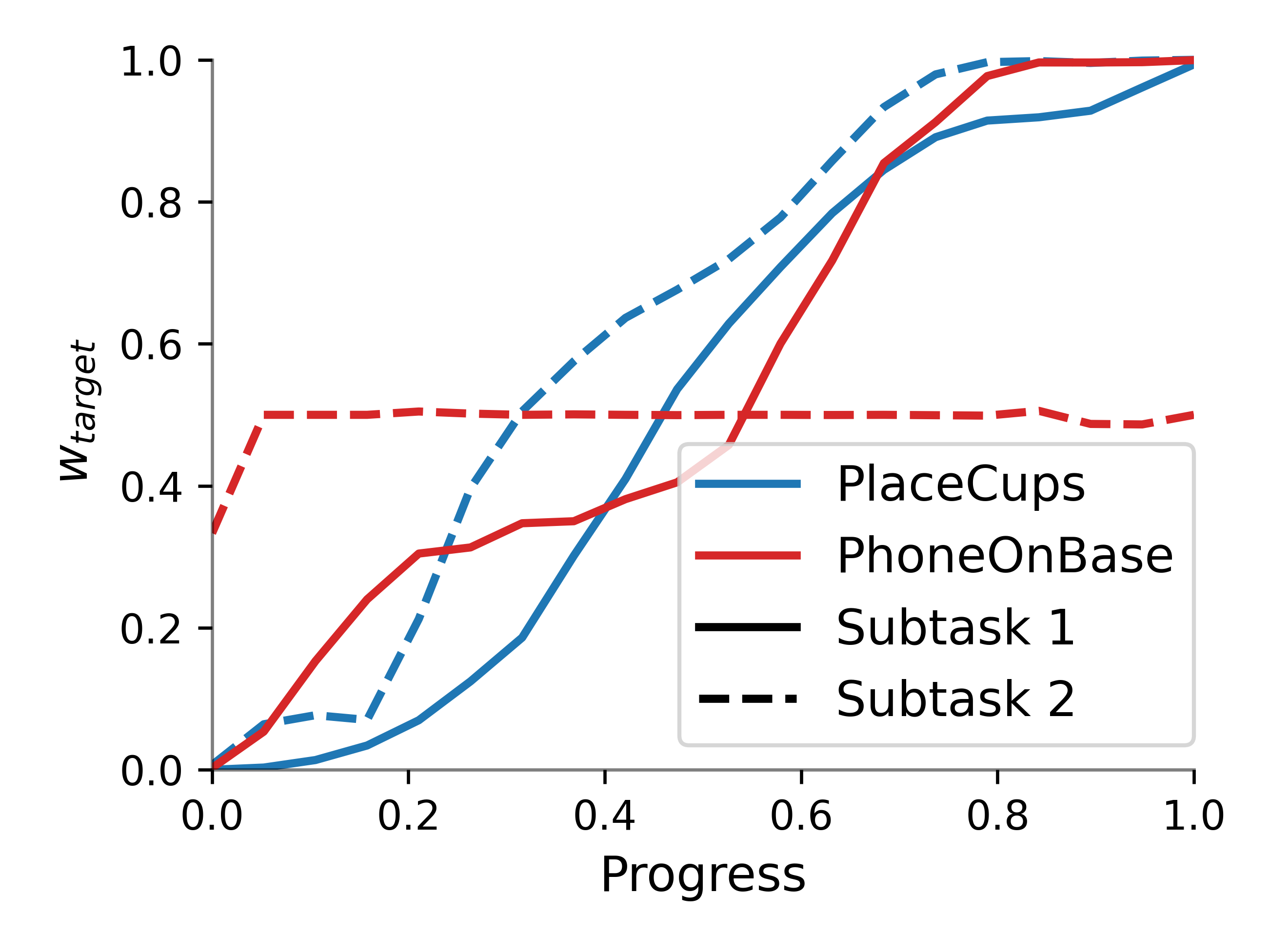
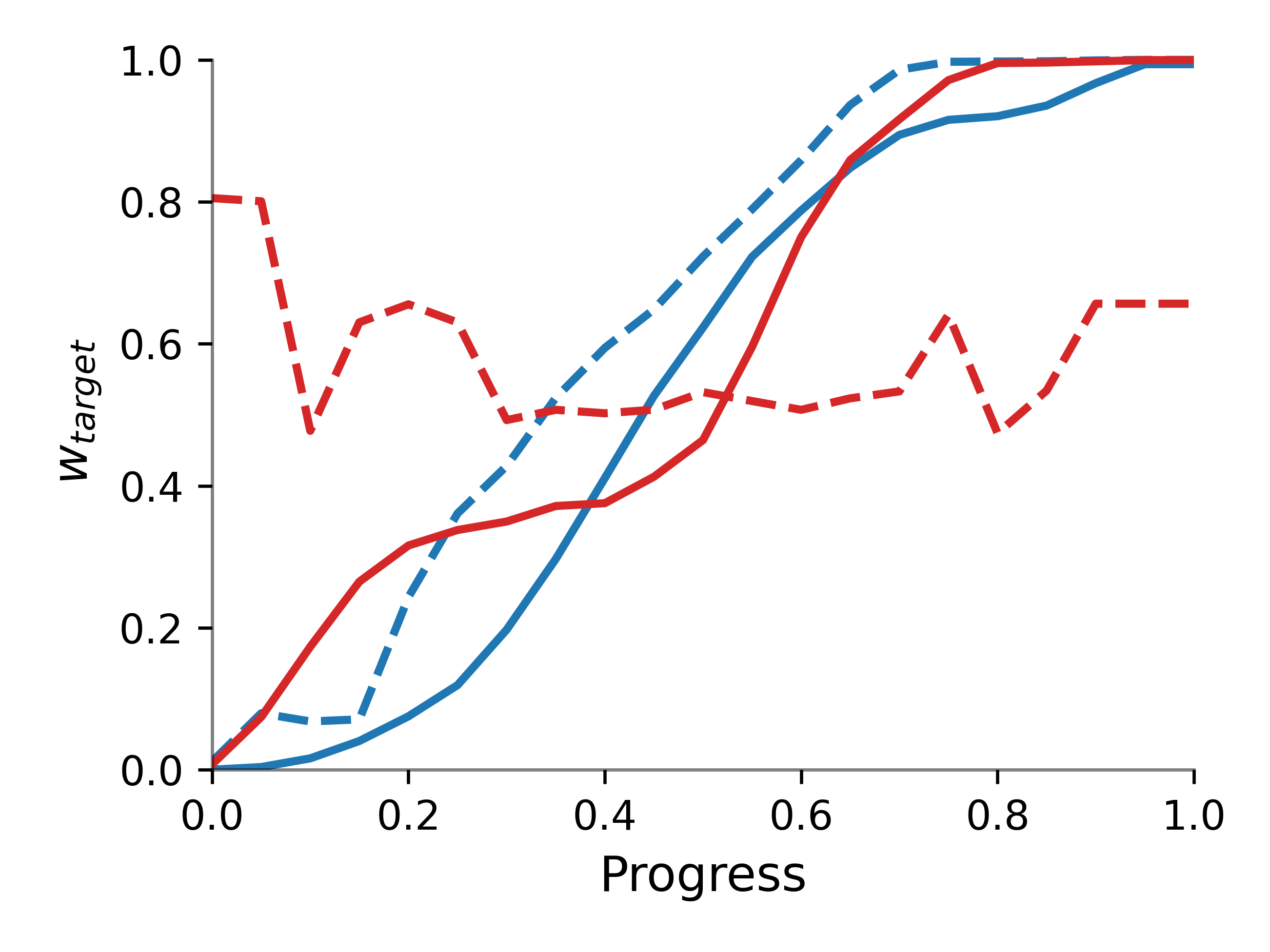
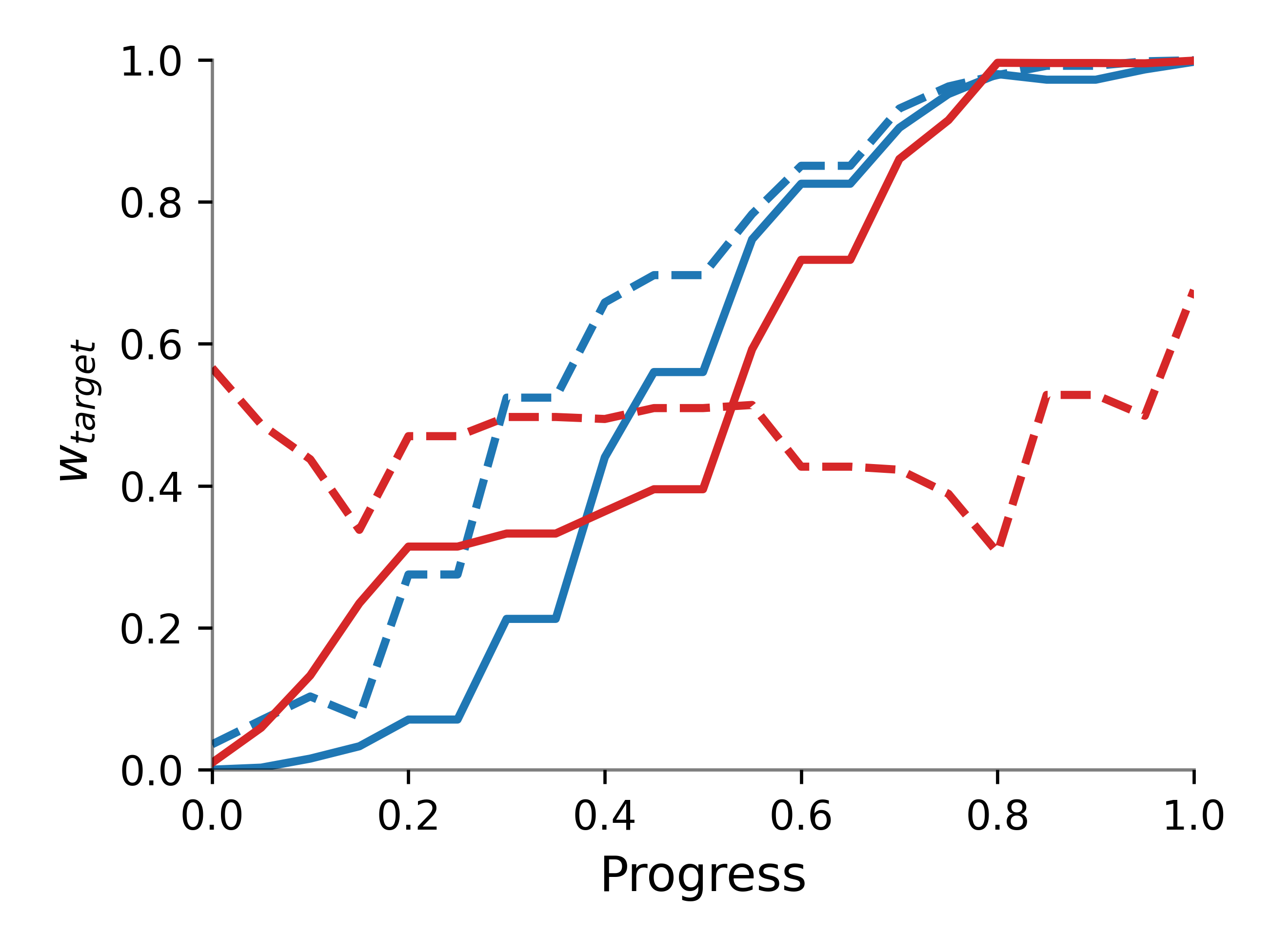
Figure 5: Progress-based weighting schedules for stream composition.
These strategies allow MSG to flexibly adapt to task structure, either via simple schedules or by learning data-driven weighting directly from demonstrations.
Experimental Evaluation
Simulation Experiments
MSG is evaluated on a suite of RLBench tasks, including both single-object and multi-object scenarios requiring high precision and long-horizon reasoning.











Figure 6: RLBench and real-world tasks used for evaluation, covering a range of manipulation challenges.
MSG consistently outperforms all baselines, including standard Flow Matching, single-stream object-centric models, and Affordance-Centric Policy Learning (ACPL). With as few as five demonstrations, MSG achieves success rates that surpass standard generative policies trained on 100 demonstrations. On average, MSG reduces demonstration requirements by 95% and improves policy performance by 89% relative to single-stream approaches.
Data Scaling and Ablation
MSG maintains its performance advantage even as the number of demonstrations increases, indicating that its benefits are not limited to low-data regimes.
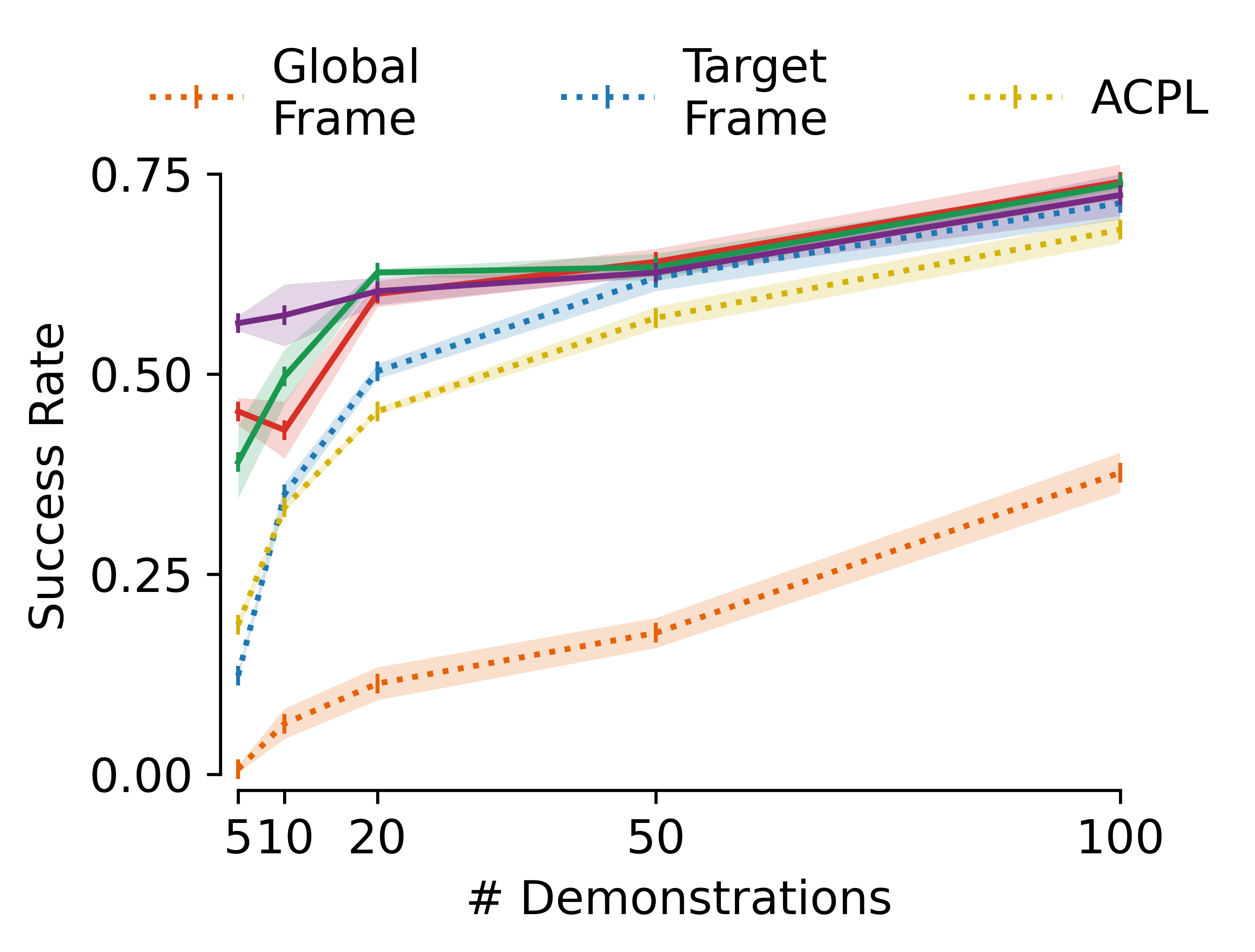
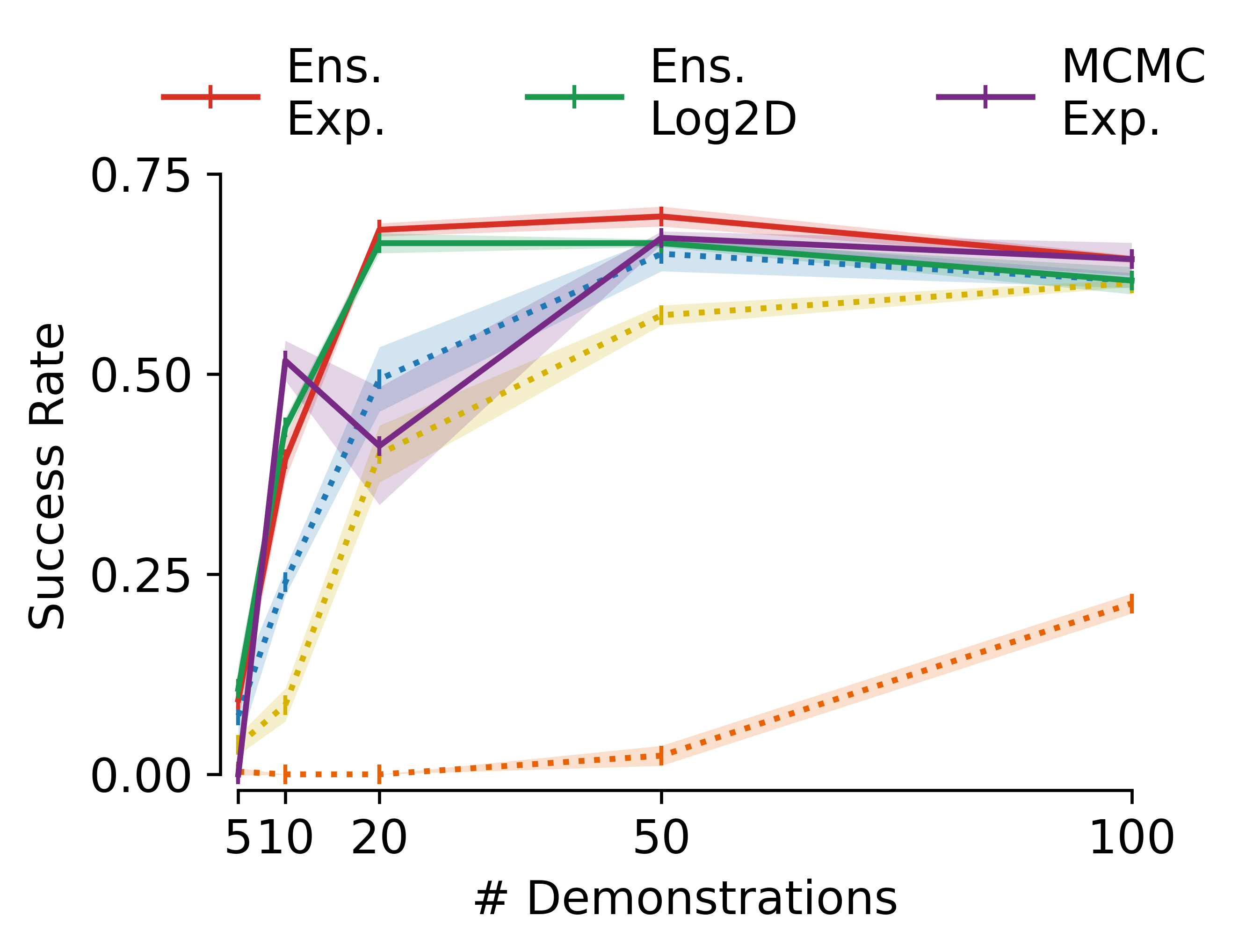
Figure 7: MSG maintains superior performance even as the number of demonstrations increases.
A comprehensive ablation study reveals that:
- The exponential progress-based schedule is generally optimal, but variance-based and parallel sampling strategies offer robust, data-driven alternatives.
- Flow composition with MCMC further improves performance, especially for tasks with high precision requirements or multimodal distributions.
- Proper sample alignment and custom priors are critical for effective flow composition.
Real-World Experiments
MSG is validated on a Franka Emika Panda robot across four real-world tasks. Object frames are estimated using DINO-based keypoint detection, enabling zero-shot transfer to novel object instances and environments. MSG achieves strong performance with only 10 demonstrations, significantly outperforming both standard and single-stream object-centric baselines.
Theoretical and Practical Implications
MSG demonstrates that multi-stream, object-centric decomposition is a powerful inductive bias for generative policy learning, enabling sample-efficient generalization and robust policy composition. The inference-only, model-agnostic design allows MSG to be integrated with emerging generative policy frameworks without retraining, and its compatibility with keypoint-based object pose estimation enables zero-shot transfer across objects and environments.
The results challenge the prevailing assumption that generative policies are inherently sample-inefficient, showing that with appropriate object-centric structure and multi-stream composition, generative models can match or exceed the sample efficiency of probabilistic approaches.
Future Directions
Potential avenues for future research include:
- Extending MSG to handle more complex, highly multimodal tasks via mixture models or hierarchical stream composition.
- Integrating MSG with vision-based policies that operate directly from raw sensory input, leveraging advances in keypoint and pose estimation.
- Exploring online adaptation and continual learning within the MSG framework to further reduce demonstration requirements in dynamic environments.
Conclusion
MSG establishes a new paradigm for sample-efficient generative policy learning in robotic manipulation by leveraging multi-stream, object-centric decomposition and inference-time model composition. The approach achieves strong generalization from minimal data, is compatible with a wide range of generative models, and supports zero-shot transfer to novel objects and environments. The findings have significant implications for the design of scalable, data-efficient robotic learning systems.

