LLM DNA: Tracing Model Evolution via Functional Representations
Abstract: The explosive growth of LLMs has created a vast but opaque landscape: millions of models exist, yet their evolutionary relationships through fine-tuning, distillation, or adaptation are often undocumented or unclear, complicating LLM management. Existing methods are limited by task specificity, fixed model sets, or strict assumptions about tokenizers or architectures. Inspired by biological DNA, we address these limitations by mathematically defining LLM DNA as a low-dimensional, bi-Lipschitz representation of functional behavior. We prove that LLM DNA satisfies inheritance and genetic determinism properties and establish the existence of DNA. Building on this theory, we derive a general, scalable, training-free pipeline for DNA extraction. In experiments across 305 LLMs, DNA aligns with prior studies on limited subsets and achieves superior or competitive performance on specific tasks. Beyond these tasks, DNA comparisons uncover previously undocumented relationships among LLMs. We further construct the evolutionary tree of LLMs using phylogenetic algorithms, which align with shifts from encoder-decoder to decoder-only architectures, reflect temporal progression, and reveal distinct evolutionary speeds across LLM families.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a simple idea: LLMs can have a “DNA” like living things. Instead of biological DNA, this “LLM DNA” is a short vector of numbers that captures how a model behaves. With this, we can compare models, see which ones are related, and draw a “family tree” showing how models evolve over time.
Objectives
The authors ask and try to answer a central question:
- Can we define and extract a compact “DNA” that represents an LLM’s behavior, so we can trace how models are related (for example, through fine-tuning or distillation) and how they have evolved?
They set two goals for this DNA:
- Inheritance: Small changes to a model (like fine-tuning) should not drastically change its DNA.
- Genetic determinism: Models with similar DNA should behave similarly.
Methods and Approach
The paper builds a theory and a practical pipeline to get each model’s DNA.
- The big idea in everyday terms:
- Think of every model’s behavior as a huge list of answers to many different questions. If you could read all those answers and turn them into numbers, you could measure how similar or different two models are.
- That “huge list” is too big to store, so the authors use a way to “squash” it down into a short vector (the DNA) while keeping the important differences between models.
- How the DNA is defined:
- “Bi-Lipschitz” mapping: This is a fancy way to say the squashing step doesn’t stretch or shrink distances too much. If two models are similar, their DNAs are close; if they are different, their DNAs are far apart.
- How the DNA is proven to exist:
- Johnson–Lindenstrauss (JL) Lemma: This math result says you can reduce very high-dimensional data down to a much smaller size and still keep distances approximately the same. Think of folding a big paper map into a small one without messing up the relative distances between cities too much.
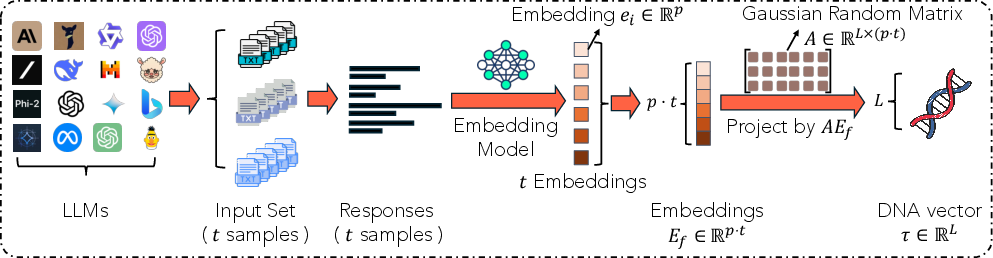
- Practical DNA extraction pipeline:
- Pick a bunch of real-world prompts (questions or tasks).
- Ask each LLM to answer those prompts.
- Turn each answer into a “meaning-aware” vector using a sentence embedding model (this captures the actual meaning, so “holiday” and “vacation” count as similar).
- Stick all those vectors for a model together into one long vector that represents the model’s behavior.
- Apply a “random projection” (mix the numbers in a smart, randomized way) to shrink this long vector down to a short DNA vector.
Why random projection?
- It’s fast, works for many kinds of models, and the JL Lemma guarantees it keeps distances reasonably accurate.
- Analogy: It’s like blending multiple paint colors in a consistent random recipe. You get a smaller palette, but colors that were similar stay similar.
- Measuring model distance in practice:
- Instead of comparing every possible question (which is impossible), they sample a set of prompts and use the average difference across those samples. A math “concentration bound” shows this estimate gets more reliable as you use more samples.
Main Findings
The authors tested their DNA method on 305 models from many organizations. Here’s what they found and why it matters:
- DNA detects relationships between models:
- Using official “model trees” (where available) and random pairs, their DNA-based classifier separated “related” vs “independent” model pairs very well (AUC ≈ 0.96).
- This is important for governance, licensing, and safety: you can tell if one model likely comes from another or shares a lineage.
- DNA helps with model routing:
- Routing means choosing the best model for a given query. Their DNA-based approach slightly outperformed a strong baseline (EmbedLLM) even though DNA was extracted without training on the routing task. That suggests DNA captures general, reusable information about each model.
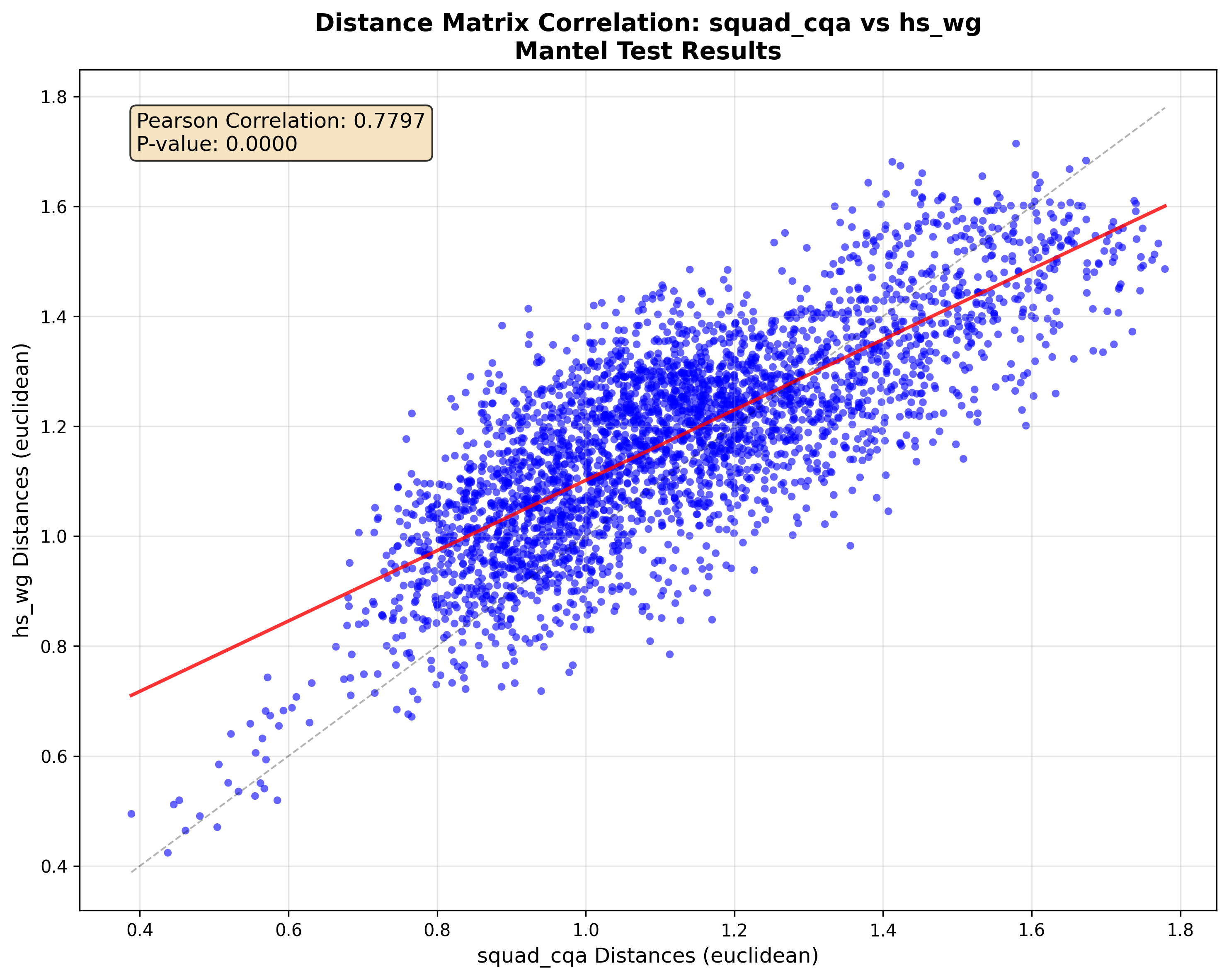
- DNA is stable across datasets:
- DNAs computed from different prompt sets still agreed on distances between models (strong correlation). This means the DNA is not too sensitive to which prompts you use—useful for consistent comparisons over time.
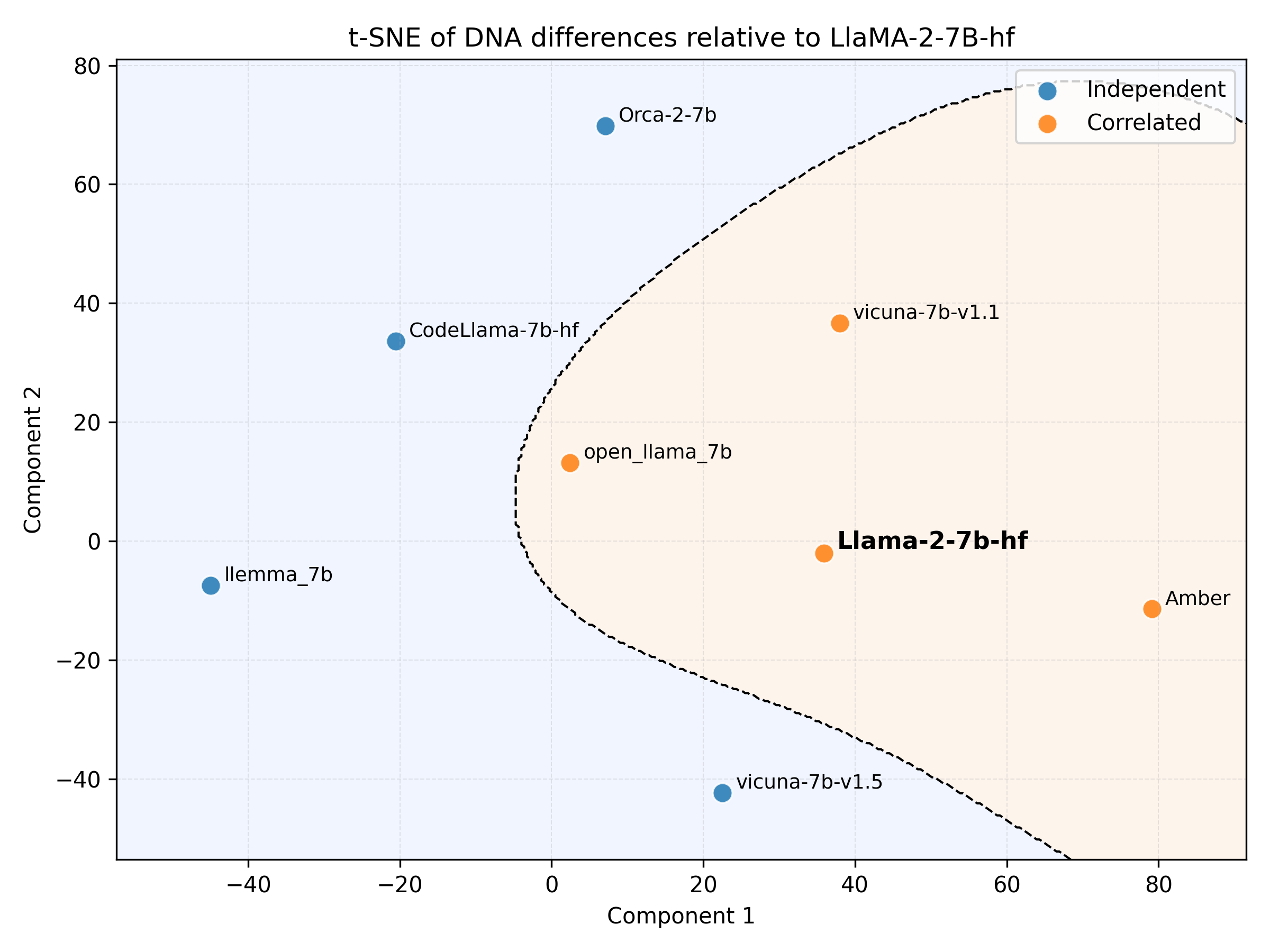
- DNA builds a believable “family tree” of LLMs:
- Using DNA distances, they constructed a phylogenetic tree (like a genealogy chart) that matches known trends:
- Shift from encoder–decoder models (like T5) to popular decoder-only models (like Llama and Qwen).
- A time progression from earlier to newer models.
- Lineages inside families (e.g., Llama 2 to Llama 3).
- The tree also suggests different “evolution speeds” across families: some (like Qwen and Gemma) seem to change faster than others.
- Discovering undocumented relationships:
- Some models that didn’t clearly list their base versions in public cards appeared near likely parent families in the DNA map (for example, certain Vicuna and Orca models near Llama clusters). This points to DNA’s ability to uncover hidden lineage.
Implications and Impact
- Safety and auditing:
- If a risky behavior is fine-tuned into a model, DNA can help track how that risk moves between related models.
- Licensing and provenance:
- DNA enables checking whether a model is truly independent or likely derived from another—important for license compliance and attribution.
- Ecosystem management:
- As millions of models appear, DNA provides a scalable, training-free way to index, compare, and organize them, even when architectures and tokenizers differ or when models are only accessible via API.
- Scientific understanding:
- With DNA, we can build evolutionary trees and study how ideas and architectures spread across the LLM world, much like biologists study species evolution.
In short, the paper gives a solid theory and a practical tool to summarize an LLM’s behavior into a small “DNA” vector. This lets researchers and practitioners compare models, discover relationships, and manage the fast-growing LLM universe more effectively.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete issues unresolved and open for future work:
- Theory—finite-set guarantee only: The existence proof via Johnson–Lindenstrauss (JL) holds for a finite set of K models; there is no guarantee that a fixed DNA mapping remains bi-Lipschitz as K grows or when new models are added later. How should L and A be adapted online to maintain distortion guarantees under continual model arrival?
- Theory–practice mismatch in outputs: Theoretical DNA is defined on full logit vectors over all outputs in , but the practical pipeline uses decoded text fed to an external sentence-embedding model. There is no formal bound relating the Hilbert distance on logits to the embedding-space distance used in practice.
- Unknown bi-Lipschitz constants: The constants determining distortion are never estimated in practice. How can one empirically bound or estimate these for given choices of prompts, embedding model, and projection dimension L?
- Choice of μ (prompt distribution): The Hilbert metric depends on a probability measure μ over inputs, but μ is neither characterized nor learned. How should μ be selected or estimated to reflect real-world usage, and how sensitive are DNA distances to shifts in μ?
- Sensitivity to prompt set t: The pipeline fixes t (100 samples per dataset). There is no study of sample-size vs. fidelity trade-offs or active/query-efficient prompt selection to minimize t while preserving pairwise distances.
- Decoding randomness impact: DNA depends on generative decoding (temperature=0.7, top_p=0.9), but the variance introduced by stochastic decoding and seed choice on DNA stability is not quantified.
- Embedding-model bias and dependence: Results hinge on a single embedding model (Qwen3-Embedding-8B). There is no ablation across multiple embedding backbones, pooling strategies, or versions, nor an analysis of how this choice biases distances (e.g., favoring the Qwen family).
- Robustness to embedding updates: If the embedding model is updated or replaced, how stable are previously computed DNAs and downstream trees? No compatibility or recalibration procedure is provided.
- Projection dimension L selection: The paper fixes L=128 without analyzing the distortion–dimension trade-off, nor offering guidance on choosing L for a target AUC or topological fidelity of the phylogeny.
- Reproducibility across hardware/precision: Some models were quantized to 8-bit; others ran in BF16/FP16. The effect of numerical precision, quantization, and hardware nondeterminism on DNA stability is not evaluated.
- Closed-source and API models: Although the method is claimed to support API-only models, experiments exclude major closed-source systems (e.g., GPT-4/Claude). Do rate limits, model version drift, or output filtering materially affect DNA reliability for APIs?
- Cross-domain and multilingual generalization: Prompts are English and mostly QA/commonsense. It remains unknown whether DNA preserves relationships for code, math, long-context reasoning, non-English languages, or domain-specific LLMs.
- Convergent similarity vs. lineage: Functional proximity may arise from shared data or objectives rather than ancestry. The method does not disentangle convergent evolution from true fine-tuning descent. What auxiliary tests or metadata could separate these cases?
- Horizontal/reticulate evolution: Model merging, mixture-of-experts, and adapter stacking induce network-like (reticulate) evolution, but the analysis uses tree-based Neighbor-Joining. How to extend DNA comparisons to phylogenetic networks capturing hybridization events?
- Branch support and uncertainty: The phylogenetic tree lacks statistical support (e.g., bootstrap values) or sensitivity analyses. How robust are clades and branch lengths to prompt sets, embedding choices, L, and decoding randomness?
- Time calibration and rooting: Midpoint rooting is used without temporal calibration or release dates. How to incorporate timestamps or molecular-clock-like models to infer directionality and evolutionary rates rigorously?
- Claim of “evolutionary speed”: Longer branches are interpreted as faster evolution without a formal rate model. Can a principled rate model be defined for functional change, with confidence intervals and tests for rate heterogeneity?
- Provenance vs. similarity evaluation: Relationship detection uses Hugging Face “Model Tree” entries as ground truth and simple random negatives, which may be incomplete or noisy. A more rigorous benchmark with verified provenance labels is needed.
- Adversarial robustness: The framework does not assess how easily DNAs can be spoofed (e.g., fine-tuning on targeted prompts to mimic another model’s DNA) or how robust it is to adversarial prompt sets.
- Data efficiency and cost: Computing DNA required querying 305 models with 600 prompts and downloading ~20 TB of checkpoints. What is the minimal t and L for reliable reconstruction, and can active or information-theoretic prompt design reduce cost?
- Interpretability of DNA: DNA dimensions are random-projection coordinates of concatenated embeddings and are not interpretable. Can one design interpretable DNA features linked to capabilities, safety traits, or training data signatures?
- Task utility beyond routing: Apart from model routing and similarity detection, the paper does not test DNA in governance tasks (license compliance), safety auditing (backdoor lineage), or federated/model-market settings. How well does DNA support these intended applications?
- Theoretical guarantees for the practical pipeline: The concentration bound assumes bounded logit-space distances, but the implemented pipeline operates in embedding space on generated text. Formal guarantees that carry through decoding + embedding + projection are missing.
- Handling tokenizer/architecture heterogeneity: While the end-to-end approach is tokenizer-agnostic, there is no analysis of how differences in tokenization or generation paradigms (e.g., encoder-decoder vs. decoder-only) affect the semantic-distance fidelity.
- Confidence intervals for distances: Pairwise DNA distances are presented without uncertainty quantification. Can one bootstrap prompts or embeddings to produce confidence intervals for distances and tree edges?
- Ethical and governance implications: Although the method can fingerprint models, risks of deanonymization, vendor identification, or misuse are not analyzed, nor are mitigation strategies (e.g., differential privacy, consent protocols) proposed.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s training-free DNA extraction pipeline and its empirical findings across 305 heterogeneous LLMs.
- Model registry and lineage tracking for heterogeneous LLM fleets
- Sectors: software, MLOps, compliance
- What it looks like: a “Model DNA” extractor service that periodically queries models (including API-only ones), computes DNAs, clusters them, and renders a phylogenetic tree to visualize relationships, inheritance from base models, and family evolution.
- Practical use: deduplicate similar models; track lineage and variants; maintain inventory across architectures/tokenizers; gate releases by measuring DNA drift from prior versions.
- Assumptions/dependencies: access to model inference; a stable sentence embedding model; representative prompt sample; adequate DNA dimension L; storage for DNA vectors.
- Provenance and identity verification of remote LLM APIs
- Sectors: security, cloud platforms, enterprise IT
- What it looks like: a probe harness that issues a small set of strategic prompts to an API, computes its DNA, and compares against registered DNAs to verify declared identity or detect model swaps.
- Practical use: vendor claim verification; SLA enforcement; API fraud detection; incident triage when a provider silently updates models.
- Assumptions/dependencies: sufficient query budget; consistent inference settings; thresholds calibrated for false positives; potential adversarial obfuscation by providers.
- License compliance auditing in model marketplaces
- Sectors: policy, legal, platform governance
- What it looks like: DNA-based similarity scoring against known base models to flag likely derivatives that may violate license terms (e.g., non-permissive fine-tunes).
- Practical use: automated audit reports; marketplace moderation; internal due diligence for procurement.
- Assumptions/dependencies: curated registry of base models; decision thresholds; legal processes for interpreting DNA similarity; documented releases to reduce ambiguity.
- Model routing and orchestration across multi-LLM stacks
- Sectors: software, cloud optimization
- What it looks like: cold-start routing that uses DNAs (frozen) to select the most promising model for a query, without retraining task-specific embeddings; hybrid cost–performance policies.
- Practical use: reduce routing training complexity; improve accuracy slightly over learned baselines; enable low-latency model switching.
- Assumptions/dependencies: correlation between DNA distance and task performance; access to query embeddings; stable routing policies.
- Ensemble construction and de-duplication
- Sectors: software, research
- What it looks like: selecting diverse models by maximizing DNA distance to improve ensemble diversity; pruning redundant models with near-identical DNAs.
- Practical use: increase ensemble robustness; reduce inference costs by removing near-duplicates.
- Assumptions/dependencies: diversity in DNA correlates with error diversity; ensemble aggregation method benefits from functional diversity.
- Security monitoring and tamper/backdoor transfer detection
- Sectors: security, compliance
- What it looks like: DNA drift monitoring across releases or fine-tunes; alerts when functional behavior shifts beyond thresholds; cross-model similarity scans to assess backdoor transfer risks.
- Practical use: release gating; early warnings; targeted red-teaming when DNA changes meaningfully.
- Assumptions/dependencies: prompt sets must cover behaviors of interest; small DNAs may miss rare or highly targeted malicious behaviors; requires periodic recalibration.
- Performance estimation and benchmark triage
- Sectors: academia, benchmarking, product evaluation
- What it looks like: using DNA structures (shown stable across datasets via Mantel tests) to estimate relative model performance, prioritize benchmarks, and plan evaluations.
- Practical use: reduce evaluation load; pick representative tests; identify likely top performers for a domain.
- Assumptions/dependencies: stability holds across your domains; empirical correlation with target tasks; careful selection of prompts.
- Multi-agent system design and planning
- Sectors: software, robotics, autonomous systems
- What it looks like: assembling agent teams with complementary DNAs to avoid redundancy; hierarchical planning guided by DNA distances for capability coverage.
- Practical use: improve coverage and resilience in agent systems; reduce overlapping behaviors.
- Assumptions/dependencies: DNA distances approximate functional complementarity for the target tasks; agent coordination scaffolding is in place.
- Cost optimization via “similar DNA, smaller model”
- Sectors: finance, cloud ops
- What it looks like: identify smaller, cheaper models whose DNAs are close to larger models for routine workloads.
- Practical use: cut inference costs while preserving functionality for everyday tasks.
- Assumptions/dependencies: closeness in DNA translates to acceptable quality on your workload; confirm with spot checks.
- Educational and documentation tooling
- Sectors: education, open-source communities
- What it looks like: interactive LLM phylogenetic trees for understanding ecosystem evolution; documentation that links models by DNA rather than only brand/architecture.
- Practical use: curriculum development; community knowledge; easier model discovery.
- Assumptions/dependencies: periodic DNA recomputation as ecosystems evolve; lightweight visualization tooling.
Long-Term Applications
These opportunities require further research, scaling, standardization, or operational maturity beyond current experiments.
- Regulatory standardization of “Model DNA” as metadata
- Sectors: policy, governance, certification
- What it looks like: a standardized DNA field in model cards and registries; conformance tests; regulatory submissions include DNA for provenance audits.
- Potential products/workflows: DNA validators; registries with API endpoints; compliance dashboards.
- Assumptions/dependencies: consensus on DNA computation protocols (prompt pools, embedding models, projection dimensions); governance bodies; legal acceptance.
- Robust backdoor provenance and incident response
- Sectors: security, safety
- What it looks like: security-focused DNA pipelines that use curated adversarial prompt sets to sensitively capture malicious functional signatures and track their transfer across fine-tunes.
- Potential products/workflows: SOC-like monitoring for model fleets; forensics playbooks integrating DNA diffs.
- Assumptions/dependencies: research on prompt sets that reliably surface backdoors; statistical thresholds for detection; adversarial resistance to DNA obfuscation.
- IP/copyright dispute resolution using DNA evidence
- Sectors: legal, platform policy
- What it looks like: DNA similarity used as part of multi-factor evidence in infringement cases (derivative determination).
- Potential products/workflows: expert reports; court-accepted methodologies; marketplace takedown workflows integrating DNA.
- Assumptions/dependencies: legal precedent; standardized forensic methods; acceptance of functional similarity as probative.
- Model supply-chain risk management platforms
- Sectors: enterprise IT, risk, compliance
- What it looks like: end-to-end systems that track model lineage, dependencies, and evolution speeds; highlight exposure to fast-evolving families; enforce internal policies.
- Potential products/workflows: “SBOM for LLMs” augmented with DNA; continuous compliance checks.
- Assumptions/dependencies: integration with procurement and deployment pipelines; scalable storage and updates.
- Continual routing and orchestration with streaming DNA updates
- Sectors: cloud, software
- What it looks like: live DNA recomputation as models update; dynamic retraining-free routing; auto-fallback when DNA drift signals performance risks.
- Potential products/workflows: observability tooling; SLA-aware routers; adaptive ensembles.
- Assumptions/dependencies: efficient incremental DNA computation; minimal disruption; robust monitoring thresholds.
- Cross-modality and multimodal DNA
- Sectors: vision, speech, robotics
- What it looks like: extending functional DNA beyond text using modality-specific embeddings and joint prompt pools; unified lineage across multimodal stacks.
- Potential products/workflows: multimodal registries; cross-modal provenance checks.
- Assumptions/dependencies: high-quality multimodal embeddings; modality-aligned prompt design; bi-Lipschitz guarantees in joint spaces.
- Forensic watermarking complement
- Sectors: security, provenance
- What it looks like: combining passive DNA fingerprinting with active watermarking for stronger provenance guarantees.
- Potential products/workflows: dual-layer verification services; tamper-evidence logs.
- Assumptions/dependencies: interoperability between watermarking schemes and DNA; resilience to removal or mimicry.
- “Genomic search” for model marketplaces
- Sectors: software platforms, discovery
- What it looks like: search and recommendation engines that let users find models by DNA similarity, lineage, or functional diversity.
- Potential products/workflows: DNA-based filters; diversity-aware recommenders; upgrade maps.
- Assumptions/dependencies: standardized DNA indices; user-friendly similarity semantics.
- Dataset influence and data governance via DNA drift
- Sectors: academia, data management
- What it looks like: measuring how specific fine-tuning datasets shift model DNA to infer dataset-induced functional changes.
- Potential products/workflows: dataset audit tools; alignment impact studies; training-data attribution research.
- Assumptions/dependencies: controlled experiments; mapping from dataset properties to DNA changes; domain coverage in prompt pools.
- Directed model design and “DNA editing” research
- Sectors: research, model optimization
- What it looks like: using target DNA regions as design goals to steer fine-tuning/distillation toward desired functional characteristics while preserving inheritance.
- Potential products/workflows: DNA-aware training curricula; optimization objectives defined in DNA space.
- Assumptions/dependencies: methods to translate DNA targets into training signals; guarantees on determinism and stability; avoidance of adversarial shortcuts.
General assumptions and dependencies to monitor
- Prompt distribution: DNA quality depends on the representativeness of S_t; coverage gaps can under-represent rare behaviors.
- Embedding model choice: semantic fidelity and stability of sentence embeddings affect distance estimates.
- Projection dimension L: trade-off between distortion and cost; high-fidelity applications require larger L.
- Access and consistency: closed-source APIs may rate-limit, change inference settings, or attempt obfuscation.
- Adversarial and mimicry risks: intentional behavior shaping could target DNA computations; robust protocols and audits are needed.
- Domain transfer: while DNAs showed stability across varied NLP datasets, domain-specific tasks may require domain-tailored prompt pools and validation.
Glossary
- ARC-Challenge: A benchmark dataset of challenging science questions used to evaluate LLMs. "ARC-Challenge~\citep{clark2018think}"
- AUC: Area Under the ROC Curve; a scalar performance metric summarizing the trade-off between true positive and false positive rates. "achieves a high AUC of $0.957$"
- backdoors: Malicious behaviors embedded in models that can be triggered by specific inputs. "tracking how security risks such as backdoors are transferred between LLMs"
- bi-Lipschitz: A property of a mapping that preserves distances up to constant multiplicative factors in both directions. "bi-Lipschitz representation of functional behavior."
- bi-Lipschitz condition: The requirement that the DNA mapping scales functional distances within fixed upper and lower Lipschitz bounds. "must satisfy a bi-Lipschitz condition"
- bi-Lipschitz constants: The pair of positive constants bounding distortion in a bi-Lipschitz mapping. "The required DNA dimension trades off with the bi-Lipschitz constants "
- CommonsenseQA: A benchmark dataset testing commonsense reasoning in LLMs. "CommonsenseQA~\citep{talmor2018commonsenseqa}"
- concentration bound: A probabilistic guarantee that an empirical estimate is close to its expectation with high probability. "A concentration bound provides a formal reliability guarantee for our empirical distance."
- DBSCAN: A density-based clustering algorithm that groups nearby points and identifies outliers. "Background regions are obtained by localized DBSCAN started where each organization forms a group of more than three models."
- decoder-only: A neural architecture that uses only a decoder stack for text generation (e.g., GPT-style). "decoder-only architectures"
- distillation: A model compression technique where a smaller student model learns to mimic a larger teacher model. "through fine-tuning, distillation, or adaptation"
- encoder-decoder: A sequence-to-sequence architecture with separate encoder and decoder components (e.g., T5). "encoder-decoder"
- ensemble learning: Combining multiple models to improve performance or robustness. "ensemble learning \citep{huang2024ensemble,fang2024llm}"
- fine-tuning: Post-training process that adapts a pretrained model to a specific task or dataset. "through fine-tuning, distillation, or adaptation"
- fingerprinting (LLM fingerprinting): Identifying a model by characteristic behaviors or properties without modifying its training. "LLM fingerprinting does not modify training; it analyzes identifiable properties of the model."
- genetic determinism: The principle that a model’s DNA representation determines its functional characteristics. "Genetic Determinism"
- Gaussian random projection: A dimensionality reduction technique using a matrix with Gaussian-distributed entries. "we adopt random Gaussian projection for extracting LLM DNA"
- HellaSwag: A benchmark dataset for commonsense inference on sentence completion. "HellaSwag~\citep{zellers2019hellaswag}"
- Hilbert distance: The distance induced by an inner product on a Hilbert space, used here for functional differences between LLMs. "there exists a Hilbert distance threshold "
- Hilbert space: A complete inner-product space; the paper models the LLM functional space as such. "forms a Hilbert space"
- Hoeffding’s inequality: A concentration inequality bounding deviations of the sample mean of bounded i.i.d. variables. "Hoeffding's inequality provides a bound on the probability that a sample mean of bounded, independent random variables deviates from its expected value."
- i.i.d.: Independent and identically distributed; a standard assumption for sampled inputs. "a set of independent and identically distributed (i.i.d.) random variables"
- instruction-tuned: Models further trained with instruction–response pairs to follow user prompts better. "Both instruction-tuned or base models are included"
- Johnson--Lindenstrauss (JL) lemma: A result guaranteeing low-distortion embeddings of finite point sets into low dimensions via random projections. "Johnson--Lindenstrauss (JL) lemma~\citep{johnson1984extensions}"
- logits: Pre-softmax scores output by a model, representing unnormalized log-probabilities. "vector of real-valued logits"
- LLM DNA: A compact, low-dimensional, bi-Lipschitz representation capturing an LLM’s functional behavior. "we introduce the concept of LLM DNA: a compact, low-dimensional representation of a model's functional behavior."
- Mantel test: A statistical test assessing correlation between two distance matrices. "a Mantel test between DNA extracted from two disjoint datasets."
- MMLU: A multitask benchmark evaluating broad LLM knowledge across many subjects. "and MMLU~\citep{hendryckstest2021}"
- midpoint-rooting: A heuristic for rooting an unrooted phylogenetic tree at the midpoint of the longest path. "the default midpoint-rooting strategy."
- Model Tree: Hugging Face’s official graph of model relationships used as ground truth in the paper. "Using the official Hugging Face relationship (the ``Model Tree'') as ground truth"
- model routing: Selecting which model should handle a given query to maximize performance. "learn representations for model routing"
- Neighbor-Joining (NJ) method: A distance-based algorithm for constructing phylogenetic trees. "Neighbor-Joining (NJ) method \citep{saitou1987neighbor}"
- p-value: The probability, under a null hypothesis, of observing results at least as extreme as the data. "()"
- Pearson correlation coefficient: A measure of linear correlation between two variables. "()"
- phylogenetic algorithms: Methods for inferring evolutionary relationships from distance or sequence data. "using phylogenetic algorithms"
- phylogenetic tree: A tree structure depicting evolutionary relationships among entities. "Phylogenetic Tree of LLM families built from DNA distances with NJ algorithm"
- provenance: The origin or lineage of a model, including sources and training influences. "\citet{nikolic2025model} and \citet{zhuindependence} further explore how to measure provenance or independence between two LLMs"
- RBF kernel: Radial Basis Function kernel used in kernelized methods like SVMs for non-linear decision boundaries. "an SVM with RBF kernel"
- random linear projection: Dimensionality reduction via a randomly sampled linear map preserving pairwise distances with high probability. "random linear projection is the optimal linear dimensionality reduction method."
- SQuAD: A question-answering benchmark dataset of reading comprehension over Wikipedia passages. "SQuAD~\citep{rajpurkar2016squad}"
- sentence-embedding model: A model that maps text to a fixed-size vector capturing its semantics. "we use a sentence-embedding model"
- Stochastic Functional Distance: An expectation-based metric estimating functional differences between LLMs from sampled inputs. "The Stochastic Functional Distance is defined as the expected Euclidean distance between the concatenated semantic representations of the LLMs' outputs over a random sample "
- support vector machine (SVM): A margin-based classifier; used here to separate related and independent model pairs. "support vector machine (SVM) with an RBF kernel"
- tokenizer: The component that splits text into tokens used by a model. "architectures and tokenizers"
- t-SNE: A non-linear dimensionality reduction method for visualizing high-dimensional data. "Visualization of DNAs by t-SNE."
- watermarks: Embedded patterns added during training to later identify or verify a model’s outputs. "watermarks, which actively insert a ``fingerprint'' during training"
- Winogrande: A commonsense reasoning dataset derived from Winograd schemas. "Winogrande~\citep{sakaguchi2020winogrande}"
Collections
Sign up for free to add this paper to one or more collections.

