- The paper introduces Learned Task Vectors (LTVs) as a direct training approach that aligns hidden states to enhance performance across LLM layers.
- LTVs are injected at specific layers with gradient descent, offering flexible, nearly parameter-efficient finetuning and a clear linear transformation analysis.
- Experimental results demonstrate that LTVs outperform traditional extraction methods, leading to better in-context learning and interpretability.
Introduction
The paper "Task Vectors, Learned Not Extracted: Performance Gains and Mechanistic Insight" (2509.24169) argues that the traditional extraction of Task Vectors (TVs) from LLMs is opaque and inefficient. Instead, it introduces Learned Task Vectors (LTVs), which are directly trained to enhance task performance. This approach offers clarity on how TVs function mechanistically, bridging the understanding between in-task learning and computational strategies.
Methodology
The authors propose training LTVs by integrating them directly into the hidden states of LLMs and optimizing via gradient descent. This approach circumvents reliance on the quality of model representations, which is typical of extraction methods. The LTVs demonstrate flexibility, operating effectively across various layers, positions, and even combined with ICL prompts.
In practice, LTVs are injected at specific layers during training, where they influence predictions through attention-head OV circuits. These changes, dominated by key attention heads, suggest that LTVs help realign the hidden states towards task-relevant directions. Moreover, the propagation of TVs through subsequent layers is predominantly linear, involving a rotation toward task-related subspaces and scaling in magnitude.
Experiments
The experiments demonstrate LTVs’ superior performance across several models and tasks. For instance, the injection of LTVs in both early and late layers of Llama models consistently yielded improved ICL-level performance. The LTVs not only surpassed traditional TV methods in accuracy but also achieved nearly parameter-efficient finetuning levels.
A notable capability of LTVs is their flexibility, as demonstrated through injections at multiple tokens and layers, and compatibility with complex task settings, such as those found in the Myopic dataset. This versatility contrasts sharply with the static performance of extracted TVs.
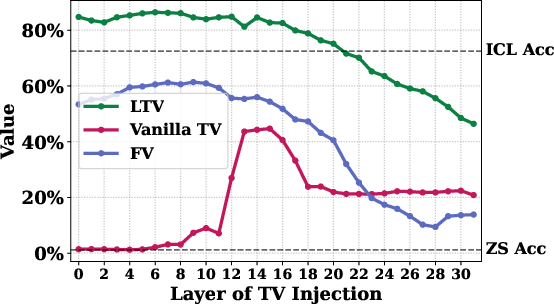
Figure 1: Layer sweeping results of injecting the Vanilla TV, FV, and our LTV to the last token hidden states on Llama2-7B.
Mechanistic Analysis
The low-level interaction between LTVs and the model indicates that TVs primarily leverage attention-head OV circuits. Ablation studies reinforce the pivotal role of key attention heads in harnessing TV-induced effects.
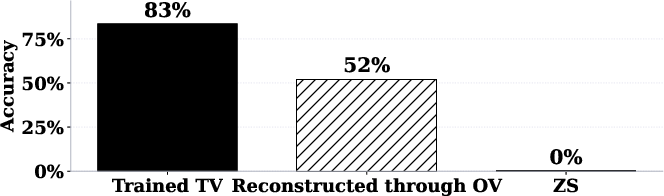
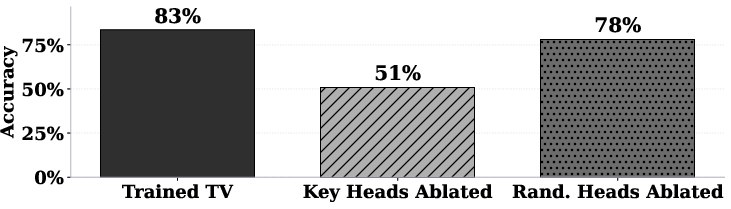
Figure 2: Reconstructing TV effect through OV circuits.
At a high level, the paper posits that the transformation of TVs through layers is largely linear. The decomposition of these effects into rotation and stretch components reveals distinct operational phases: early TVs primarily rotate toward task-relevant subspaces, while late-layer TVs are scaled to adjust their impact magnitude.
Conclusion
LTVs introduced in this paper present a robust methodological shift toward understanding and optimizing task performance in LLMs. By alleviating the opaque nature of traditional extraction methods, LTVs not only enhance task performance but also provide insight into the mechanistic underpinnings of in-context learning.
Overall, the introduction of LTVs marks a significant advancement in efficient, flexible, and interpretable task learning within LLMs, setting a foundation for future research into model understanding and application.