- The paper introduces TENET, a framework that uses executable tests as explicit behavioral specifications to bridge the intent gap in code generation.
- It details a test harness mechanism, tailored agent toolset, and reflection-based refinement workflow that optimize token efficiency and fault recovery.
- Empirical evaluations show notable gains, with Pass@1 improvements up to 81.77%, emphasizing strategic test selection and iterative debugging.
TENET: Leveraging Tests Beyond Validation for Code Generation
Introduction and Motivation
TENET introduces a repository-level code generation agentic framework that operationalizes Test-Driven Development (TDD) for LLM-based code synthesis. The motivation stems from the inadequacy of natural language intent and code context alone to specify complex function requirements in large repositories. By leveraging executable test cases as explicit behavioral specifications, TENET aims to bridge the intent gap and systematically guide LLMs toward correct implementations, especially in scenarios where repository-level dependencies and edge cases are prevalent.

Figure 1: Examples of repository-level code generation under standard and test-driven setups.
System Architecture
TENET comprises three core components:
- Test Harness Mechanism (THM): Dynamically selects a concise, diverse subset of test cases that maximally cover distinct usage scenarios of the target function, based on caller diversity and invocation proximity.
- Tailored Agent Toolset: Extends AST-based retrieval with APIs for semantic similarity search, usage example extraction, import analysis, and fine-grained interactive debugging.
- Reflection-Based Refinement Workflow (RRW): Iteratively analyzes test failures, localizes faults, replenishes context, and applies targeted code refinements until all selected tests pass or a refinement budget is exhausted.
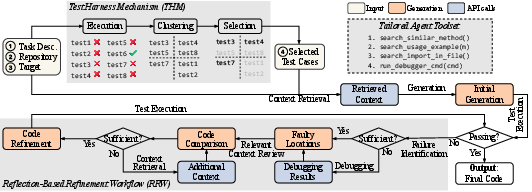
Figure 2: TENET workflow illustrating THM, tailored toolset, and RRW integration.
Test Harness Mechanism
The THM addresses the challenge of test suite selection under context window and computational constraints. It executes the full test suite against an unimplemented target, clusters failing cases by caller function, and selects up to T cases prioritizing caller diversity and minimal call stack depth. Empirical results indicate that three to five tests typically yield optimal performance, with larger suites introducing noise and diminishing returns.
TENET's toolset augments standard AST navigation with:
search_import_statement(f): Disambiguates cross-file dependencies.search_similar_method(n): BM25-based semantic retrieval for reference implementations.search_target_usage(n): AST-driven extraction of invocation contexts.run_debugger_cmd(cmd): Containerized, stepwise debugging for evidence collection.
This design enables efficient context acquisition and interactive fault diagnosis, reducing token consumption and API call overhead compared to terminal-command-based agents.
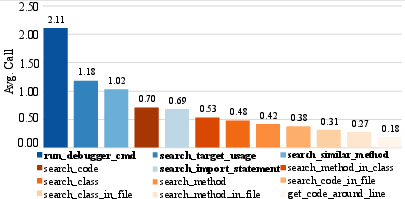
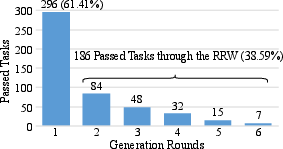
Figure 3: Average API calls per task on TENET and DeepSeek-V3, highlighting frequent use of tailored APIs.
Reflection-Based Refinement Workflow
RRW operationalizes iterative self-debugging in repository-level settings. Upon test failure, the agent localizes faults, reviews retrieved context, and determines sufficiency for refinement. If context is insufficient, additional retrieval and debugging are triggered. This loop continues until a fix is attempted, validated, or the refinement budget is exhausted. RRW is critical for recovering tasks that fail initial generation, with 38.59% of solved tasks attributed to refinement rounds.
Experimental Evaluation
Baseline Comparison
TENET achieves 69.08% Pass@1 on RepoCod and 81.77% on RepoEval, outperforming the strongest agentic baselines by 9.49 and 2.17 percentage points, respectively. It also demonstrates superior token efficiency, with input consumption orders of magnitude lower than OpenHands and SWE-Agent, which suffer from fragmented, command-based retrieval.
Ablation Study
Removing THM, tailored toolset, or RRW each results in substantial Pass@1 drops (17.24%, 14.89%, and 9.24%, respectively), confirming the necessity of all components. Notably, feeding the full test suite (no THM) increases input tokens by 40.69% and API calls by 45.53%, with accuracy severely degraded.
Test Suite Size and Selection Strategies
Empirical analysis reveals that increasing the number of test cases beyond three to five degrades performance, contradicting the intuition that more tests always help. THM's selection strategy, which combines caller diversity and invocation proximity, yields the highest Pass@1 and coverage compared to random, simplicity-based, failure-revealing, and invocation-proximity-only baselines.
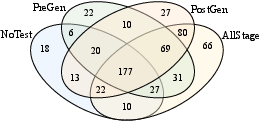
Figure 4: Pass@1 and test coverage under different selection strategies; overlap of solved tests across four settings.
Test Usage Stage
Leveraging tests in both pre-generation (retrieval) and post-generation (refinement) stages maximizes correctness, with Pass@1 rising from 29.90% (no tests) to 49.18% (all stages). However, this comes at increased token and API call cost, necessitating trade-offs in deployment.
Case Studies
- THM Effectiveness: In seaborn_34, THM's curated test subset enables correct handling of edge cases, whereas the full suite confuses the agent and leads to floating-point errors.
- Toolset Utility: In scikit_47, semantic retrieval of similar methods and usage examples enables correct parallelization logic, which naive AST navigation fails to uncover.
- RRW Impact: In scikit_49, iterative refinement guided by test feedback and targeted context retrieval converges to the ground-truth solution, rescuing tasks that fail initial attempts.
- Failure Mode: In more_itertools-66, weak or misleading context leads to persistent hallucination and unproductive refinements, highlighting limitations when test signals are insufficient.
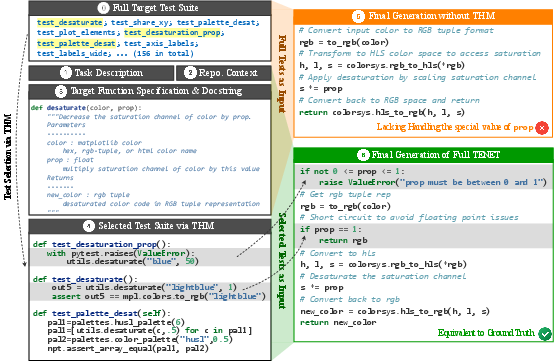
Figure 5: A case study on task seaborn_34 demonstrating THM-guided code generation.
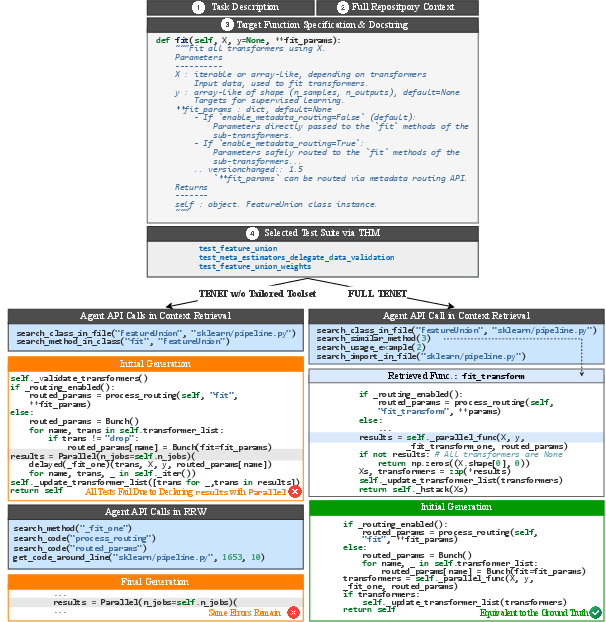
Figure 6: A case study on task scikit_47 illustrating the impact of the tailored agent toolset.

Figure 7: A case study on task scikit_49 showing RRW-driven iterative refinement.

Figure 8: A failure case study on task more_itertools-66, illustrating limitations under weak context.
Analysis of Test Selection Strategies
- Random Selection (RS): Baseline, yields lowest coverage and Pass@1.
- Simplicity-Based Selection (SS): Prioritizes low cyclomatic complexity; marginal improvement over RS.
- Failure-Revealing Selection (FRS): Focuses on explicit assertions; pool often too large, diluting effectiveness.
- Invocation-Proximity Selection (IPS): Short call chains; better coverage, but THM's caller diversity further improves results.
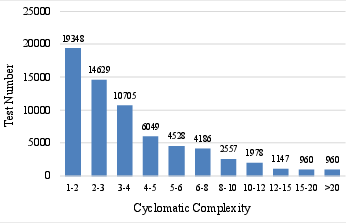
Figure 9: Test distributions based on cyclomatic complexity.
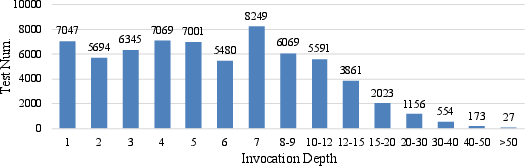
Figure 10: Test distributions based on invocation depth from test to target.
Practical Implications and Future Directions
TENET demonstrates that TDD, when operationalized via agentic frameworks, substantially improves repository-level code generation accuracy and efficiency. The findings challenge the assumption that larger test suites are always beneficial, instead advocating for strategic selection based on usage diversity and proximity. The tailored toolset and RRW are essential for navigating complex repositories and recovering from initial failures.
For deployment, practitioners should balance test suite size, selection strategy, and stage of test usage to optimize accuracy and resource consumption. The approach is extensible to other agentic frameworks and can be integrated with automated test generation methods to further reduce reliance on existing suites.
Future work includes:
- Integrating advanced test generation (e.g., CodeT, ChatUniTest) to automate the THM pipeline.
- Developing more flexible refinement strategies to enhance RRW effectiveness.
- Extending the framework to multi-language, cross-repository, and issue-fixing scenarios.
Conclusion
TENET establishes a principled agentic framework for repository-level code generation under TDD, achieving state-of-the-art performance and efficiency. Its systematic study of test suite selection, usage stage, and refinement workflows provides actionable insights for both research and practice in LLM-driven software engineering. The results underscore the critical role of executable specifications and agentic reasoning in scaling code generation to real-world repositories.