- The paper introduces a scalable method by using consistency scores derived from the variance of LLM judges as a proxy for traditional Elo scores.
- It achieves a strong 0.91 Pearson correlation between the consistency scores and human-assessed Elo scores across 24 LLMs.
- The approach minimizes human evaluation dependency and offers a cost-effective, efficient alternative for comparing large language models.
Model Consistency as a Proxy for LLM Elo Scores
In the field of LLMs, assessing a model's performance is crucial for determining its suitability for various tasks. With rapid advancements in model development, traditional evaluation methods face significant scalability challenges. The paper "Model Consistency as a Cheap yet Predictive Proxy for LLM Elo Scores" (2509.23510) introduces an innovative method to approximate Elo scores using a Consistency score derived from the preference elicitation process.
Introduction and Motivation
The proliferation of LLMs requires scalable evaluation methods to independently determine model capabilities. Elo scores, widely regarded as a gold standard for model comparison, necessitate human input, thus limiting scalability. This paper proposes using LLMs as judges to evaluate contests between models. A Consistency score is calculated from the variance of the preferences expressed by LLM judges in selecting a winner between model responses. This metric exhibits a strong correlation with human-derived Elo scores, offering a scalable alternative devoid of human biases and inefficiencies.
The traditional Elo score approach involves human evaluators comparing model outputs, introducing subjectivity and scalability issues. Replacing human judges with LLMs mitigates these challenges albeit with its own biases, such as verbosity and position biases. However, these biases can be addressed to align closer with human judgment.
Methodology
The proposed method utilizes Consistency scores derived from variance in LLM judges' preferences when evaluating model contests. The Consistency score is defined mathematically in terms of the variance of preferences in pairwise model matchups (Equations presented in the paper). The assumptions are that high Elo models inherently possess greater consistency in judgment, correlating with their own expected task performance.
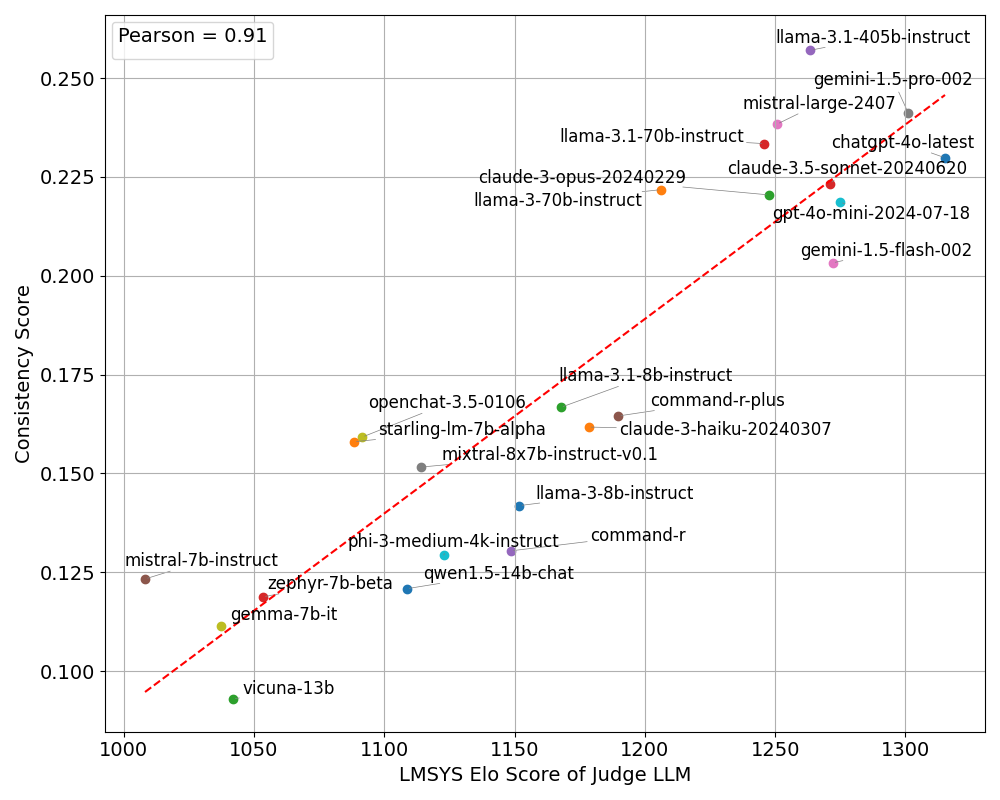
Figure 1: Correlation plot between the Elo score and Consistency score of each judge.
The formulation posits that consistency in judgment - a low variance in preference - corresponds to higher model competence. Because consistency does not require human intervention, nor relies on the correctness of judged answers, it offers a broader applicability across various tasks. This approach aligns with precedents in unsupervised learning of judge preferences to infer model capabilities.
Experiments and Results
Experiments involve evaluating 24 LLMs with known Elo scores as judges over contests extracted from the LMSYS dataset. A Pearson correlation coefficient of 0.91 was achieved when plotting Consistency scores against Elo scores (Figure 1). The clustering within model performance tiers reveals intra-cluster differences, implying broad capabilities but limitations in differentiating among high-tier models.
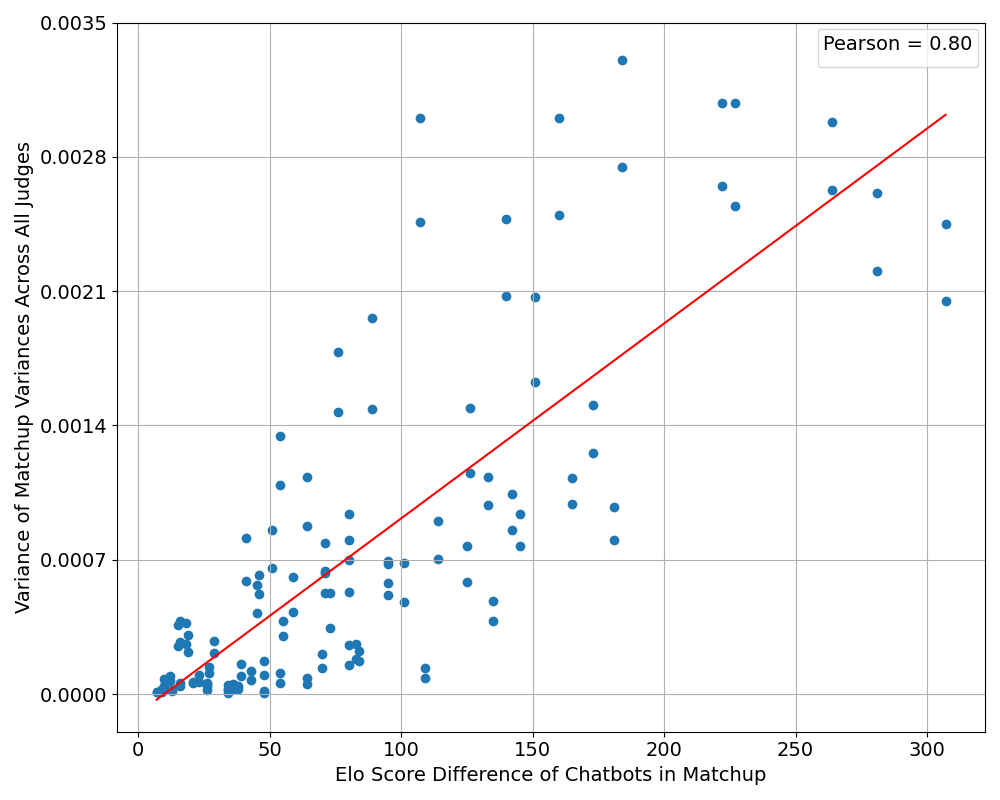
Figure 2: Correlation plot between the difference in Elo scores in a given matchup of two models and the variance of matchup variance computed across all judge LLMs for that matchup.
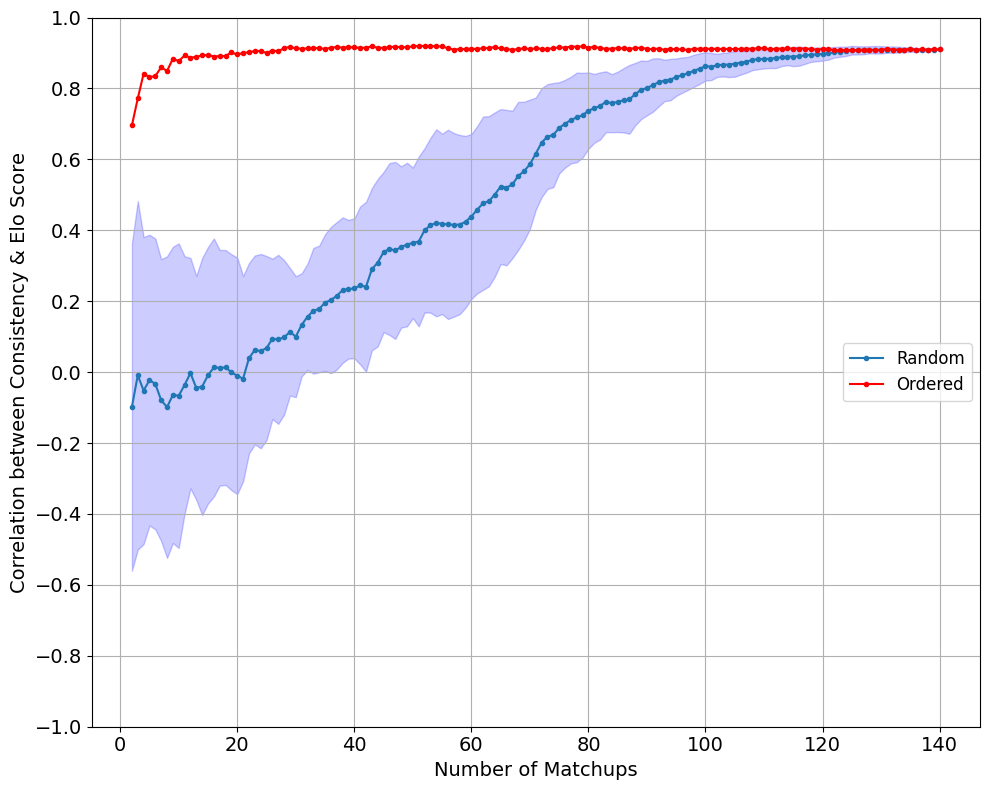
Figure 3: Convergence of the Pearson correlation coefficient between Consistency and Elo scores as the number of matchups used to compute the Consistency scores increases. Both the blue and red lines converge to similar levels.
The experiments highlight the importance of contest data, especially matchups with significant differences in Elo scores, to effectively discern the consistency and capability of LLM judges. By prioritizing matchups with high Elo differences, the method efficiently converges to high correlation with Elo scores.
Conclusion
The introduction of Consistency scores presents a scalable, cost-effective proxy for Elo scores, significantly reducing dependency on human evaluations. The method exhibits a strong correlation with existing Elo rankings, thereby validating its potential as a reliable metric for assessing model intelligence. This metric promises broad applicability across diverse tasks, including those with subjective elements. Future directions include optimizing matchup selection and refining the method to distinguish finer nuances among high-performing models.
In summary, Consistency scores represent an impactful contribution to LLM evaluation by offering a practical, scalable solution accommodating the rapid pace of model development in AI research.
