Detecting Corpus-Level Knowledge Inconsistencies in Wikipedia with Large Language Models
Abstract: Wikipedia is the largest open knowledge corpus, widely used worldwide and serving as a key resource for training LLMs and retrieval-augmented generation (RAG) systems. Ensuring its accuracy is therefore critical. But how accurate is Wikipedia, and how can we improve it? We focus on inconsistencies, a specific type of factual inaccuracy, and introduce the task of corpus-level inconsistency detection. We present CLAIRE, an agentic system that combines LLM reasoning with retrieval to surface potentially inconsistent claims along with contextual evidence for human review. In a user study with experienced Wikipedia editors, 87.5% reported higher confidence when using CLAIRE, and participants identified 64.7% more inconsistencies in the same amount of time. Combining CLAIRE with human annotation, we contribute WIKICOLLIDE, the first benchmark of real Wikipedia inconsistencies. Using random sampling with CLAIRE-assisted analysis, we find that at least 3.3% of English Wikipedia facts contradict another fact, with inconsistencies propagating into 7.3% of FEVEROUS and 4.0% of AmbigQA examples. Benchmarking strong baselines on this dataset reveals substantial headroom: the best fully automated system achieves an AUROC of only 75.1%. Our results show that contradictions are a measurable component of Wikipedia and that LLM-based systems like CLAIRE can provide a practical tool to help editors improve knowledge consistency at scale.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at Wikipedia, the huge online encyclopedia millions of people use every day. The authors ask a simple question: Are there places in Wikipedia where one article says one thing and another article says the opposite? They call these “inconsistencies.” To help find them, they build an AI helper named CLAIRE that searches Wikipedia, spots possible contradictions, and shows the evidence so humans can double-check.
What questions are the researchers trying to answer?
- How common are contradictions inside Wikipedia?
- Can an AI assistant help editors find these contradictions faster and more confidently?
- Can we create a reliable dataset of real contradictions to test and improve AI systems?
- How well do current AI methods work at detecting these contradictions, and how much room is there to improve?
How did they do the research?
Think of Wikipedia as a giant library. The team wanted to find places where two “facts” from different parts of the library disagree.
Here’s their approach, in plain language:
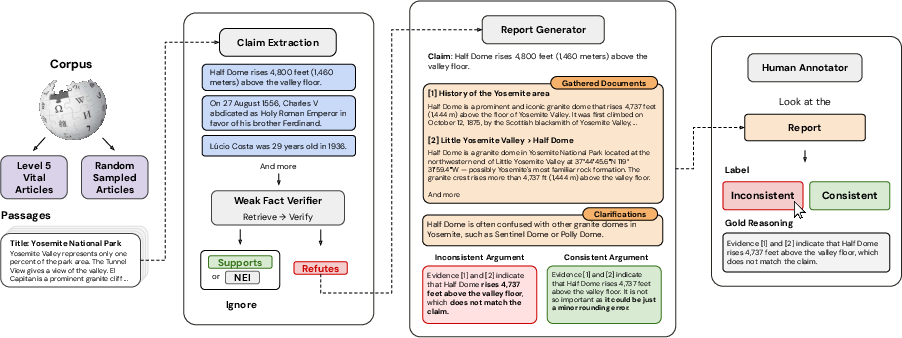
- Building an AI helper (CLAIRE): CLAIRE is like a smart research assistant. It reads a short fact from Wikipedia, searches other pages for related information, and points out where something might not match.
- Combining searching and reasoning: CLAIRE doesn’t just grab text; it uses an AI LLM (an LLM) to think through the evidence. It goes step by step, searching, checking, and refining its search based on what it finds.
- Clarify and explain: If there are people or places with the same name, or tricky terms, CLAIRE asks for clarifications and simple explanations. This makes it easier for humans to understand what’s going on.
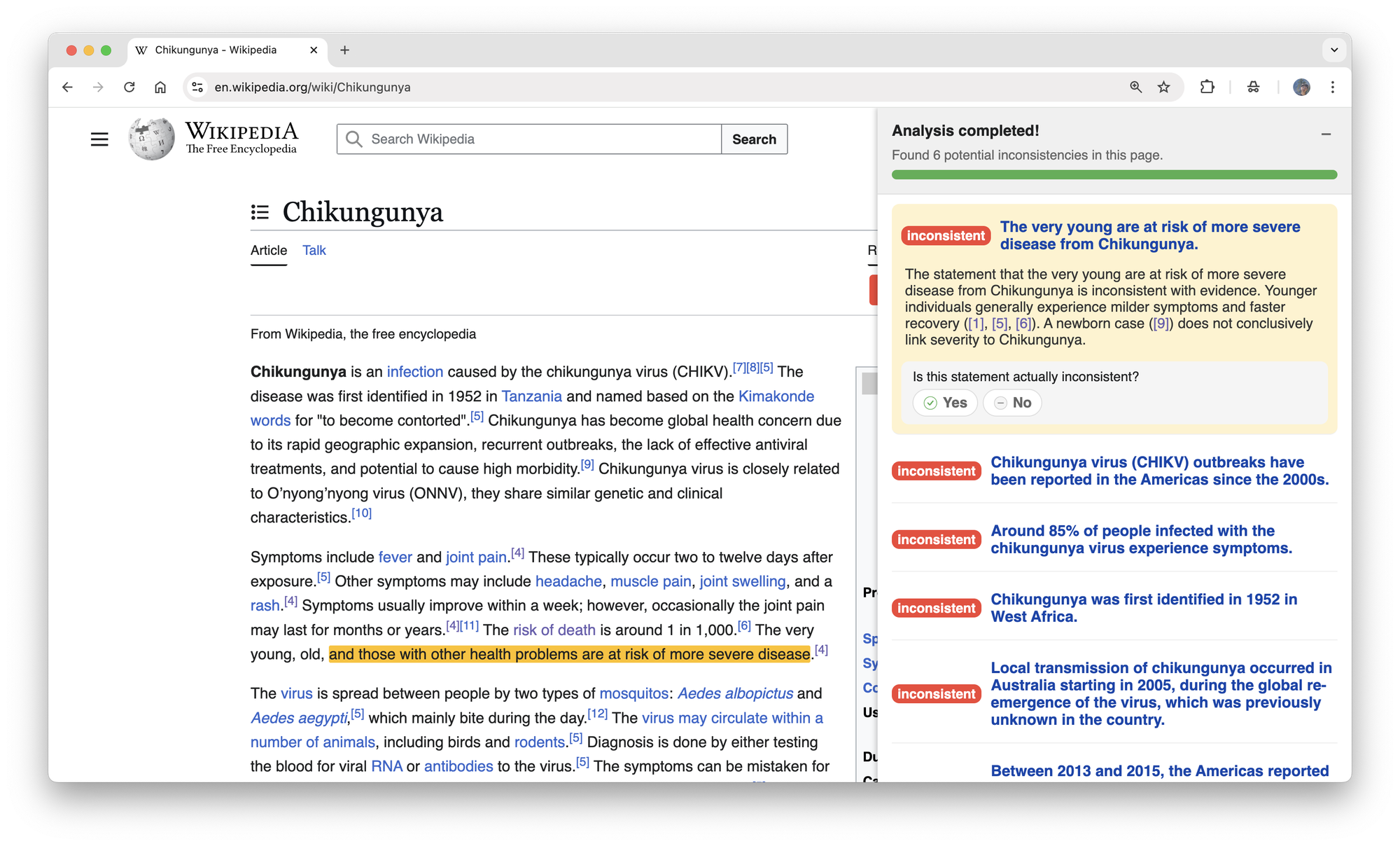
- Human-in-the-loop: CLAIRE shows its best guesses and the evidence, but humans make the final call. Experienced Wikipedia editors tested CLAIRE using a browser extension that highlights possible contradictions on the page and shows links to the evidence.
- Measuring how often contradictions happen: The team randomly sampled facts across Wikipedia, used CLAIRE to find possible issues, and then manually confirmed real contradictions. This gave them a careful estimate.
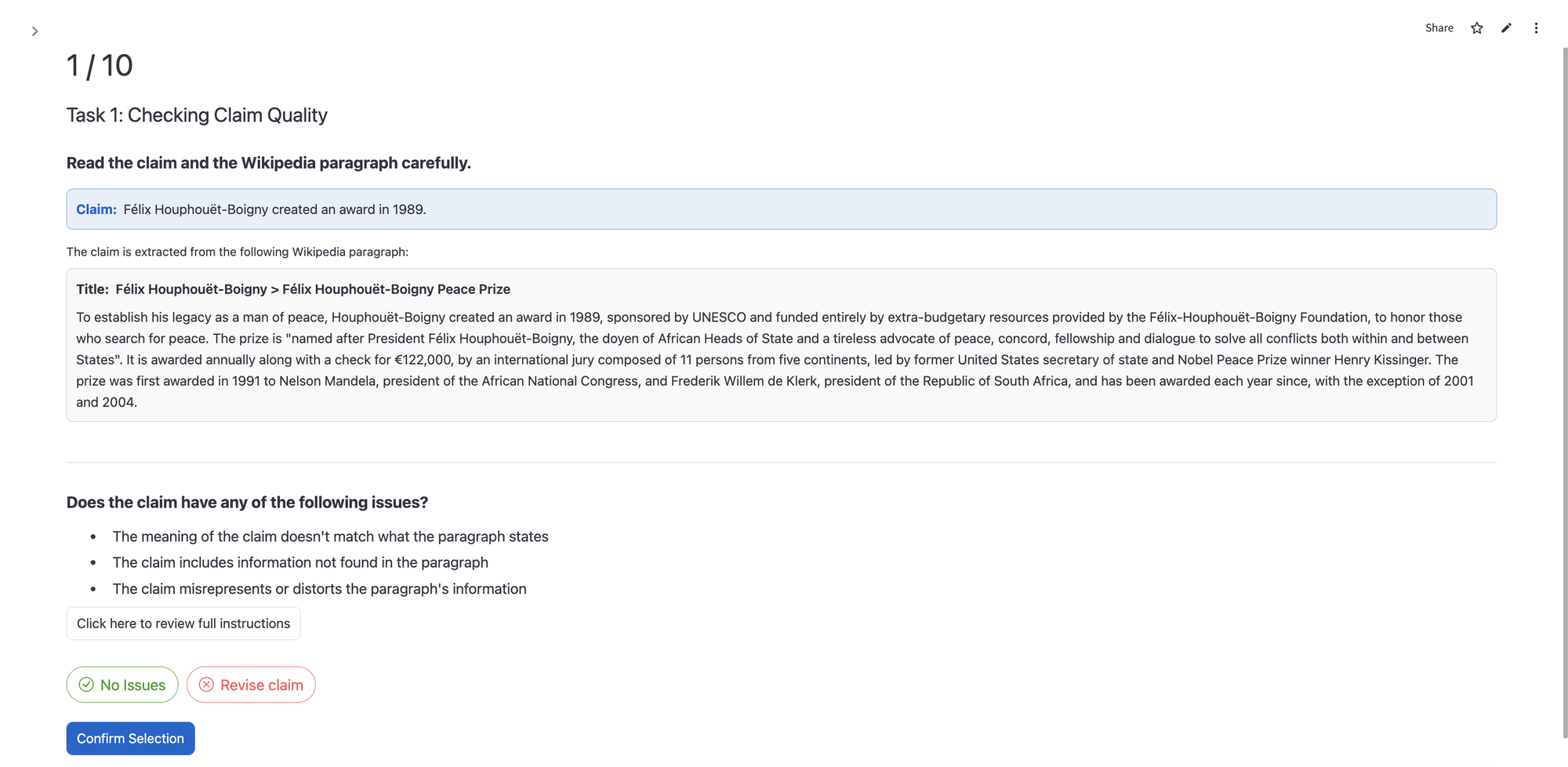
- Creating a dataset (WikiCollide): They combined CLAIRE’s findings with human review to build a new dataset of 955 short facts, where each fact is labeled as “consistent” or “inconsistent” with the rest of Wikipedia. This dataset helps test and compare different AI methods.
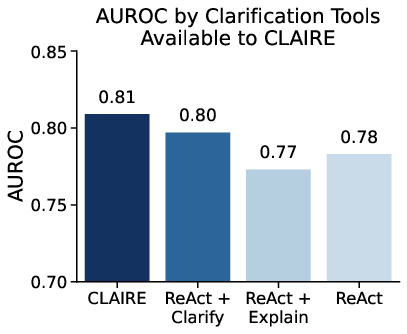
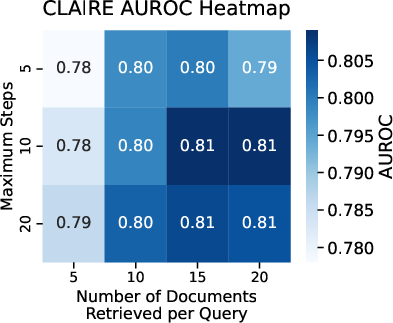
- Benchmarking AI systems: They tested CLAIRE against other strong baselines to see how well each method detects contradictions. They used common performance measures, like accuracy and AUROC (a score that shows how well a system separates true positives from false positives).
What did they find, and why is it important?
Key results:
- Contradictions are real and measurable: At least about 3.3% of English Wikipedia facts contradict another fact somewhere in the encyclopedia. Given Wikipedia’s size, that could be tens of millions of conflicting statements.
- CLAIRE boosts human editors: In a small user study with experienced editors, people found 64.7% more inconsistencies per hour when using CLAIRE compared to regular search tools. Also, 87.5% said CLAIRE made them more confident.
- Contradictions affect popular AI datasets: Two widely used research datasets built from Wikipedia also contain contradictions:
- AmbigQA: about 4.0% of its examples clash with other Wikipedia content.
- FEVEROUS: about 7.3% of claims marked as “supports” could also be “refutes,” depending on which article you use—showing that assuming Wikipedia is perfectly consistent can be risky.
- New benchmark: The WikiCollide dataset gathers real contradictions, not fake or “made-up” ones. It’s harder and more realistic, and it highlights common error types like off-by-one year mistakes, number mismatches, and confusion over names or definitions.
- There’s lots of room to improve AI: Even the best fully automated system reached an AUROC of about 75.1%—good, but far from perfect. AI often gets tripped up by context, like rounding differences, translation variants, time periods, and different scholarly opinions.
Why this matters:
- Wikipedia trains AIs and powers many apps: If Wikipedia has contradictions, those errors can spread into AI systems and tools people use every day.
- Editors need help at scale: Wikipedia is huge. AI tools like CLAIRE can help humans spot problems faster, then humans can fix them.
What does this mean for the future?
- Better tools for editors: CLAIRE shows that AI can help people clean up contradictions faster and with more confidence. This could make Wikipedia more reliable over time.
- Stronger AI research: The WikiCollide dataset gives researchers a realistic testbed to build and evaluate better inconsistency detectors. That can lead to smarter, more trustworthy AI systems.
- A positive feedback loop: Cleaner Wikipedia → better AI training data → better AI tools → even cleaner Wikipedia.
- More challenges ahead: AI still struggles with context and nuance. The paper suggests future work on other types of corpora (like medical or legal texts) and across different languages in Wikipedia.
In short, the paper shows that contradictions inside Wikipedia are real and important—and that AI + humans working together can make a big difference in finding and fixing them.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single list of concrete gaps and open questions left unresolved by the paper that future researchers can act on:
- Generalization beyond English Wikipedia: How well does CLID transfer to other large, noisy corpora (e.g., scientific, legal, medical texts), other community-maintained resources (e.g., Wiktionary, StackExchange), and structured sources (e.g., Wikidata, knowledge graphs, databases)?
- Cross-lingual inconsistencies: How to detect and reconcile contradictions across different language editions of Wikipedia, accounting for translation variants, coverage differences, and asynchronous updates?
- Longitudinal dynamics: What is the temporal evolution of inconsistencies (emergence, resolution, persistence) across revisions and talk pages, and how do rates vary over time and editorial cycles?
- “Consistent” label uncertainty: How to quantify and report statistical confidence that a fact is consistent when exhaustive corpus-wide verification is infeasible (e.g., formalizing negative labels with confidence intervals or bounded risk of missed contradictions)?
- Sampling and estimation bias in prevalence rates: The estimate (3.3%) relies on CLAIRE as a detector and LLM-based atomic fact extraction; how to build an unbiased estimator for corpus-level inconsistency (e.g., capture–recapture methods, multi-detector ensembles, randomized audit protocols) and quantify detector recall?
- Atomic fact extraction reliability: What are the error modes and rates of GPT-based claim decomposition, and how do they affect downstream CLID outcomes? Can we develop standardized, audited, and reproducible extraction pipelines with measured inter-annotator agreement?
- Set-level evidence aggregation: The CLID formalism uses NLI(E, f) without a principled set-level aggregator; how should multiple, heterogeneous evidence items be combined (e.g., voting, Bayesian aggregation, argumentation frameworks) to decide contradictions robustly?
- Entity disambiguation at scale: How to robustly prevent name collisions and alias confusions (e.g., systematic use of Wikidata IDs, disambiguation-aware retrieval, canonicalization), and what is the measurable impact on false positives/negatives?
- Context-sensitive contradiction modeling: How to formalize and learn policies for acceptable variation (numeric rounding, temporal qualifiers, translation variants, belief vs. truth, evolving scholarly consensus) to reduce context-dependent false positives?
- Evidence coverage limits: Retrieval relies on embeddings over passages, tables, and infoboxes; how to extend to other namespaces and artifacts (templates, categories, references/citations, edit histories, talk pages, media) and measure recall across these sources?
- Calibration of inconsistency scores: How to calibrate model scores (e.g., Platt scaling, isotonic regression, conformal prediction) so editors can set cost-sensitive thresholds and triage effectively given asymmetric costs of false positives/negatives?
- Small-scale, potentially biased user study: With n=8 editors and preselected articles known to contain inconsistencies, what is the tool’s effectiveness in larger, diverse populations, on randomly sampled pages, and in longitudinal real-world editing workflows?
- Real-world editorial outcomes: Does CLAIRE lead to sustained improvements (e.g., number of corrections merged, time to resolution, reversion rates), and how does it integrate with Wikipedia governance (AfC, NPOV, consensus-building) without inducing edit conflicts?
- Dataset selection bias (Vital Articles + filtering): WikiCollide’s construction enriches for likely inconsistencies; how representative is it of the full encyclopedia? Can we release unfiltered, stratified random samples and report inter-annotator agreement statistics?
- Taxonomy and repair linkage: The inconsistency type taxonomy is coarse; can we refine it and map types to concrete resolution actions (e.g., source reconciliation, date normalization), enabling automated repair suggestions or edit drafts?
- Training dedicated CLID models: The paper uses in-context LLMs; can we train supervised or retrieval-augmented models specifically for CLID (on WikiCollide and beyond), and evaluate generalization out-of-domain and under distribution shift?
- Multi-hop, multi-evidence reasoning: Many contradictions require multi-hop reasoning and aggregation; how to design verifiers that can robustly chain evidence, maintain provenance, and detect implicit contradictions at scale?
- Time-aware verification: How to incorporate as-of dates, revision IDs, and time-scoped assertions so models avoid comparing facts from different periods without appropriate temporal qualifiers?
- Use of citations and external sources: When Wikipedia itself is contradictory, how should systems leverage cited sources (and their versions) to adjudicate truth, and what policies reconcile corpus-internal contradictions with external ground truth?
- Retrieval robustness and efficiency: What are the trade-offs between embedding models, reranking strategies, and index designs for high-recall retrieval under tight latency/cost budgets at Wikipedia scale?
- Cost-sensitive evaluation: AUROC is informative but indifferent to operational costs; can we propose editor-centric metrics (precision at top-k, time-to-validated-contradiction, workload reduction) and evaluate under realistic triage scenarios?
- Impact on downstream NLP: How do corpus-level inconsistencies influence LLM training, RAG QA accuracy, and fact verification benchmarks (FEVER/FEVEROUS/AmbigQA)? Can we quantify performance gains after corpus clean-up driven by CLID?
- False-positive mitigation and transparency: What UI and explanation designs most effectively prevent overflagging, communicate uncertainty, and build editor trust, especially in domains with legitimate scholarly disagreement?
- Scaling and maintenance: How to keep CLID systems up-to-date with continuous Wikipedia edits, handle reindexing, and support real-time monitoring without prohibitive costs or carbon footprint?
- Benchmark expansion and standardization: How to grow WikiCollide (size, domains, languages), standardize protocols (IAA, confidence reporting, provenance), and create shared leaderboards with clearly defined operational objectives and error taxonomies?
Glossary
- Agentic system: An AI system that iteratively plans, retrieves information, and acts to accomplish a task. "We present CLAIRE, an agentic system that combines LLM reasoning with retrieval to surface potentially inconsistent claims"
- AmbigQA: A Wikipedia-based question answering dataset focusing on ambiguous queries. "In AmbigQA~\cite{min-etal-2020-ambigqa}, 4.0\% of questions have answers that contradict other content in the same Wikipedia dump, challenging the dataset's assumption of unambiguous, unique answers."
- AUROC: Area Under the Receiver Operating Characteristic curve; a scalar metric summarizing a classifier’s ability to distinguish classes across thresholds. "the best fully automated system achieves an AUROC of only 75.1\%."
- Atomic fact: A short, self-contained statement expressing a single, independently verifiable piece of information. "An atomic fact~\citep{min-etal-2023-factscore} is a short, self-contained statement that conveys a single piece of information and can be verified independently~\citep{semnani-etal-2023-wikichat, gunjal-durrett-2024-molecular}."
- AveriTeC: A dataset/benchmark for automated verification of claims. "AveriTeC~\citep{schlichtkrull-etal-2024-automated}"
- CLAIRE: Corpus-Level Assistant for Inconsistency Recognition; an LLM-based agent that retrieves and reasons about evidence to surface contradictions. "We propose CLAIRE (Corpus-Level Assistant for Inconsistency REcognition), a system for surfacing inconsistencies in large corpora."
- CLID: Corpus-Level Inconsistency Detection; the task of finding contradictions within a corpus for a given fact. "We define CLID as a binary classification task over atomic facts."
- Cochran formula: A statistical formula to estimate required sample size for proportions at a desired confidence and error margin. "using the Cochran formula~\citep{cochran1953sampling}:"
- EX-FEVER: A dataset variant/extensions related to FEVER for fact verification. "EX-FEVER~\citep{ma-etal-2024-ex}"
- FEVER: A large-scale fact verification dataset built from Wikipedia. "FEVER~\citep{thorne-etal-2018-fact}"
- FEVEROUS: A Wikipedia-based fact verification dataset emphasizing table-based evidence. "FEVEROUS~\citep{feverous}"
- HOVER: A dataset for multi-hop fact verification and reasoning over Wikipedia. "HOVER~\citep{jiang-etal-2020-hover}"
- In-context learning: Using examples or instructions within a prompt to guide an LLM’s behavior without fine-tuning. "CLAIRE employs in-context learning with an LLM to assess whether retrieved evidence contradicts the given fact."
- IRB: Institutional Review Board; an ethics committee overseeing research involving human participants. "The study was approved by our institution's IRB, and participants provided informed consent."
- Level 5 Vital Articles: A prioritized set of important Wikipedia pages curated by WikiProject Vital Articles. "Wikipedia's Level 5 Vital Articles,"
- Likert scale: A psychometric scale for survey responses (e.g., 5-point from Strongly Disagree to Strongly Agree). "Participants rated their agreement with several statements on a 5-point Likert scale (Strongly Disagree to Strongly Agree);"
- LLaMA-3.1: A family of LLMs (here, 70B-parameter) used as an LLM backbone. "the 70B-parameter LLaMA-3.1~\cite{grattafiori2024llama}"
- mGTE: An embedding model used to vectorize and retrieve Wikipedia passages. "using the mGTE embedding model~\cite{zhang-etal-2024-mgte}"
- Natural Language Inference (NLI): A task to determine if a premise entails, contradicts, or is neutral with respect to a hypothesis. "denotes the standard three-way Natural Language Inference task~\citep{bowman-etal-2015-large, condoravdi-etal-2003-entailment}."
- o3-mini: A medium-reasoning LLM used as a backbone in experiments. "and o3-mini~\cite{openai2025o3} as LLM backbones."
- Prolific: An online platform for recruiting and compensating research participants/crowdworkers. "Prolific~\citep{prolific}"
- RankGPT: An LLM-based reranker used to reorder retrieved documents by relevance. "Unless noted otherwise, all experiments use RankGPT~\citep{sun-etal-2023-chatgpt} for reranking after retrieval."
- ReAct architecture: A prompting framework where an LLM interleaves reasoning (thought) with actions (e.g., retrieval) iteratively. "we propose CLAIRE, an agent based on the ReAct architecture~\citep{yao2022react}."
- Retrieval-augmented generation (RAG): A technique that augments LLMs with external retrieval to improve factuality. "retrieval-augmented generation (RAG) systems~\citep{semnani-etal-2023-wikichat, lewis2020retrieval, guu2020realm, zhang-etal-2024-spaghetti}"
- Receiver Operating Characteristic (ROC) curve: A plot of true positive rate vs. false positive rate across decision thresholds. "We report the Area Under the Receiver Operating Characteristic curve (AUROC) as our main metric, alongside accuracy and F1."
- TabFact: A dataset for table-based fact verification. "TabFact~\citep{chen2020tabfactlargescaledatasettablebased}"
- Temporal drift: Changes in facts over time that can cause outdated or time-inconsistent information. "or focuses solely on temporal drift~\citep{marjanovic-etal-2024-dynamicqa}."
- VitaminC: A dataset constructed for contrastive evidence-based fact verification. "VitaminC~\citep{schuster-etal-2021-get}"
- WikiCollide: A benchmark dataset of real Wikipedia inconsistencies curated with CLAIRE. "We introduce WikiCollide, a dataset for Corpus-Level Inconsistency Detection on Wikipedia."
- WikiContradict: A dataset of Wikipedia contradictions based on editor-added tags. "WikiContradict~\citep{hou2024wikicontradict} also targets real contradictions but relies on inconsistency tags added by Wikipedia editors."
- WikiContradiction: A dataset focusing on contradictions within a single Wikipedia article. "WikiContradiction~\cite{hsu2021wikicontradiction} focuses on contradictions within a single article,"
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with current capabilities (human-in-the-loop recommended), each linked to sectors and accompanied by suggested tools/workflows and key dependencies.
- Bold: Wikipedia editorial assistance (media, education, software)
- CLAIRE-style browser extension and dashboard that highlights potentially inconsistent facts, shows counter-evidence across articles, and links to sources; triage queues for WikiProjects and patrollers; talk-page bot that posts high-confidence flags with evidence.
- Tools/workflows: browser extension, triage dashboard, bot for talk pages, watchlist integration.
- Dependencies/assumptions: community acceptance; versioned dump or live index; human reviewer closes the loop due to false positives and contextual nuances (rounding, translations, temporal qualifiers).
- Bold: Enterprise wiki/documentation QA (software, enterprise IT)
- Plugin for Confluence/SharePoint/Notion/MediaWiki to flag cross-page contradictions in product docs, runbooks, FAQs; change-review gate that runs a CLID check before merges.
- Tools/workflows: CI step (“consistency check”), editorial side-panel in the editor, Slack/Jira integration to file tickets with evidence.
- Dependencies/assumptions: access to full internal corpus; privacy-preserving LLM deployment or on-prem models; domain-configurable rules (rounding thresholds, preferred definitions).
- Bold: RAG “consistency gate” for indexing and retrieval (software/AI)
- Pre-index audit that clusters semantically similar claims across documents and assigns inconsistency scores; filter or downrank contradictory passages; store scores with embeddings for contradiction-aware retrieval/ranking.
- Tools/workflows: retrieval pipeline component, claim clustering, scoring, reranker integration.
- Dependencies/assumptions: corpus snapshots; embedding store; acceptable latency/cost; empirically tuned thresholds to balance recall vs. precision.
- Bold: Dataset auditing for NLP benchmarks and internal ML data (academia, AI)
- Use WikiCollide and CLAIRE to scan QA/verification datasets (e.g., FEVEROUS, AmbigQA, internal datasets) to identify contradictions, relabel ambiguous items, and publish inconsistency audits.
- Tools/workflows: dataset curation scripts, annotator portal with two-sided reasoning, release of audit reports.
- Dependencies/assumptions: curator time; agreed annotation guidelines (e.g., rounding policy, temporal scope).
- Bold: Knowledge graph ingestion quality checks (software, data management)
- Before ingesting from text to KG (RDF/Wikidata/Neo4j), run CLID to flag conflicting sources; attach inconsistency scores and evidence to nodes/edges; gate updates that violate constraints.
- Tools/workflows: ingestion pipeline hook, SHACL/SHEX rule checks complemented by CLID evidence.
- Dependencies/assumptions: link between textual claims and structured edges; ontology-specific exception rules.
- Bold: Newsroom and publishing consistency audits (media)
- Cross-article checks during copy-edit: “consistency report” that flags mismatched numbers, dates, definitions, or entity references prior to publication.
- Tools/workflows: CMS plugin, nightly corpus scans, reporter-side assistant for clarifications/explanations.
- Dependencies/assumptions: high recall for numerics/dates; editor review; time-scoped comparisons for evolving stories.
- Bold: E-commerce product catalog hygiene (retail, software)
- Detect discrepancies in SKUs across pages and feeds (dimensions, weights, prices, compatibility, color names); highlight variant/parent conflicts.
- Tools/workflows: product information management (PIM) integration, batch scans, back-office triage queue.
- Dependencies/assumptions: normalized product IDs; mapping vendor feeds to catalog taxonomy; tolerance rules (unit conversions, rounding).
- Bold: Compliance and policy document checks (finance, public sector, enterprise)
- Scan internal policies/procedures and regulatory memos for cross-document contradictions (e.g., limits, exceptions, definitions).
- Tools/workflows: intranet crawler + CLID index, compliance dashboard, evidence-linked findings for legal review.
- Dependencies/assumptions: secure deployment; domain templates for definitions and temporal effectivity; legal oversight on interpretations.
- Bold: Customer support knowledge base QA (software, CX)
- Identify conflicting troubleshooting steps or eligibility criteria across help center pages, macros, and agent notes.
- Tools/workflows: Zendesk/ServiceNow/Khoros integration; weekly audit reports; in-editor warnings during article edits.
- Dependencies/assumptions: access to agent-only content; entity disambiguation (product versions, regions).
- Bold: MLOps pretraining/fine-tuning corpus cleaning (AI)
- Remove or downweight contradicted passages prior to training to reduce learned inconsistencies; log domain-specific inconsistency rates to guide data selection.
- Tools/workflows: data curation scripts, inconsistency-aware sampling, training data provenance tracking.
- Dependencies/assumptions: at-scale retrieval/index; compute budget; acceptance that CLID provides a lower bound (not exhaustive).
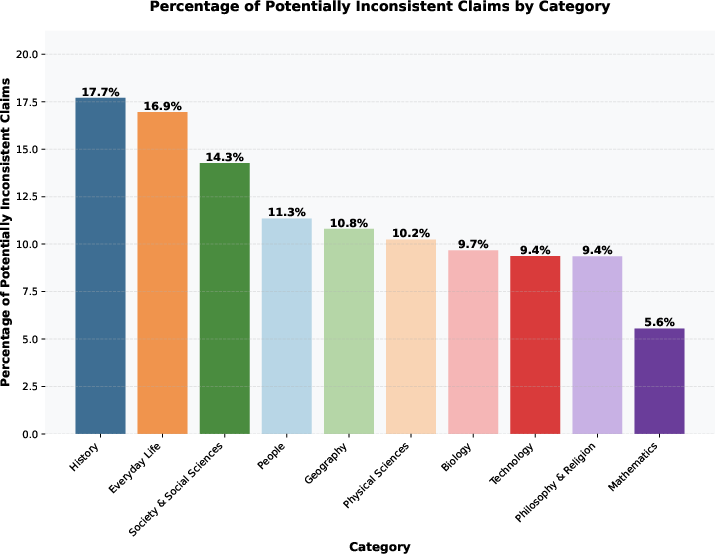
- Bold: Domain analytics and resource allocation (media, public sector)
- Use inconsistency rate dashboards segmented by category/topic to prioritize editorial budgets (e.g., history vs. math) and track improvements over time.
- Tools/workflows: scheduled scans, BI dashboard, category taxonomy mapping.
- Dependencies/assumptions: stable taxonomy; periodic full-corpus reindexing.
- Bold: Educational reading assistant for students (education, daily life)
- Lightweight browser extension that signals “potentially contradictory” facts on Wikipedia/encyclopedic sites, with plain-language explanations.
- Tools/workflows: front-end highlighter, side-panel explanations, links to evidence.
- Dependencies/assumptions: opt-in usage; clear disclaimers; simple toggles for domain thresholds (e.g., tolerating 1-year date gaps).
Long-Term Applications
These require further research, scaling, domain adaptation, or changes to ecosystem practices.
- Bold: Automated fix proposals with citation selection (media, software)
- Move from detection to suggested edits: propose corrected numbers/dates/definitions, select authoritative sources, and draft diffs/talk-page notes.
- Dependencies/assumptions: higher-precision NLI; source authority modeling; community/bot policy changes; human approval workflow.
- Bold: Cross-lingual inconsistency detection across Wikipedias and multilingual corpora (media, education, AI)
- Identify contradictions between language editions or between multilingual documentation sets; prioritize translation updates.
- Dependencies/assumptions: robust cross-lingual retrieval/NLI; entity alignment across languages; multilingual editorial pipelines.
- Bold: Time-aware CLID with versioning and effectivity (media, finance, public sector)
- Model claims with temporal scope and compare within valid time windows; reason over versions (regulations, price lists, biographies).
- Dependencies/assumptions: reliable timestamping/version histories; temporal reasoning capabilities; policies for retrospective vs. current truth.
- Bold: Formal constraint-augmented CLID (software, data management, healthcare)
- Marry ontological/SHACL rules with text-derived claims; flag violations with structured justifications and textual evidence.
- Dependencies/assumptions: mature ontologies; accurate text-to-structure mapping; domain exception handling.
- Bold: Contradiction-aware search and summarization (software, search)
- Search engines and answer systems that surface multiple perspectives and explicitly mark conflicting facts, with uncertainty/consistency scores.
- Dependencies/assumptions: product UX for uncertainty; trust/safety review; calibration of scores.
- Bold: Real-time monitoring of streaming content (media, risk)
- Detect inconsistencies as news, social posts, or feeds update; alert editors or risk teams when authoritative guidance is contradicted.
- Dependencies/assumptions: low-latency indexing; drift handling; source reliability modeling.
- Bold: High-stakes domain adapters (healthcare, finance, legal)
- Clinically- or compliance-graded CLID that cross-checks clinical guidelines vs. drug labels, or policies vs. regulations; integrates with EHR/RegTech.
- Dependencies/assumptions: expert-validated rulebooks; strong precision requirements; security and regulatory compliance.
- Bold: Training-time contradiction mitigation for LLMs (AI)
- Use inconsistency scores to curate training curricula, create hard-negative pairs, and reduce exposure to contradictory data; evaluate downstream factuality gains.
- Dependencies/assumptions: large-scale scoring pipelines; careful ablation of effects on diversity and robustness.
- Bold: Contract and policy conflict detection with hierarchical scopes (legal, enterprise)
- Detect contradictions across clauses, amendments, and jurisdictional overlays; propose harmonization paths.
- Dependencies/assumptions: domain-specific ontology and definitions; hierarchy and precedence modeling; attorney-in-the-loop.
- Bold: Governance and standards for dataset quality (academia, policy, AI)
- Require public NLP datasets to report inconsistency audits; establish CLID benchmarks as part of data statements and leaderboard hygiene.
- Dependencies/assumptions: community consensus; repeatable protocols; funding for audits.
- Bold: Community-scale bot ecosystems for consistency maintenance (media)
- Network of bots that continuously scan, flag, propose fixes, and route to domain-specific WikiProjects; cross-article templates to enforce harmony.
- Dependencies/assumptions: API quotas; governance; escalation and dispute-resolution mechanisms.
Notes on Feasibility and Risk
- Human-in-the-loop remains essential: current AUROC (~75%) is suitable for triage but not autonomous edits.
- Domain policies matter: acceptable rounding, translations, variant spellings, and temporal qualifiers must be encoded per domain to reduce false positives.
- Data access and privacy: enterprise deployments need secure, possibly on-prem LLMs and indices.
- Versioning and drift: contradictions can be transient; systems should track snapshot IDs and timestamps.
- Metrics and calibration: application thresholds should be tuned to minimize wasted reviewer time while keeping recall high for critical domains.
Collections
Sign up for free to add this paper to one or more collections.