- The paper presents a novel framework that recovers 3D scenes from a single in-the-wild image and converts them into interactive, physics-enabled robotic environments.
- The paper demonstrates that RoLA produces high-quality visuomotor demonstrations and achieves policy success rates comparable to traditional multiview methods.
- The paper validates a seamless sim-to-real deployment strategy and highlights RoLA's potential in training vision-language-action models across diverse robotic tasks.
Robot Learning from Any Images
Introduction
The paper "Robot Learning from Any Images" introduces RoLA, a framework designed to transform in-the-wild images into immersive, interactive robotic environments. Unlike previous approaches that require complex setups or multiview data, RoLA can operate effectively with a single image, drastically reducing the prerequisites for generating robotics data. The core of RoLA's functionality is its novel approach combining single-view physical scene recovery with visual blending strategies for synthesizing realistic data tailored for robotic learning tasks.

Figure 1: RoLA transforms a single in-the-wild image into an interactive, physics-enabled robotic environment.
Methodology
The methodology of RoLA can be delineated through its three primary components:
- Real-to-Sim Conversion: This involves recovering the physical scene from a single image by estimating object and scene geometry, inferring physical properties, and determining camera positioning. This single-view recovery method sidesteps the need for multiview or 3D asset databases, relying instead on foundation model priors.
- Simulation: After reconstructing the physical scene, RoLA generates extensive simulated robotic trajectories to cover diverse tasks. This is facilitated by defining robot placements in the simulated environment and producing visual demonstrations using sophisticated blending techniques to ensure the visual fidelity of simulated sequences.
- Sim-to-Real Deployment: The final component synthesizes photorealistic visuomotor demonstrations and allows the deployment of learned policies onto real-world robots. Through visual blending, RoLA minimizes the visual domain gap between simulation and the real world, enhancing the reliability of sim-to-real transitions.
An overview of the RoLA framework is depicted in Figure 2.
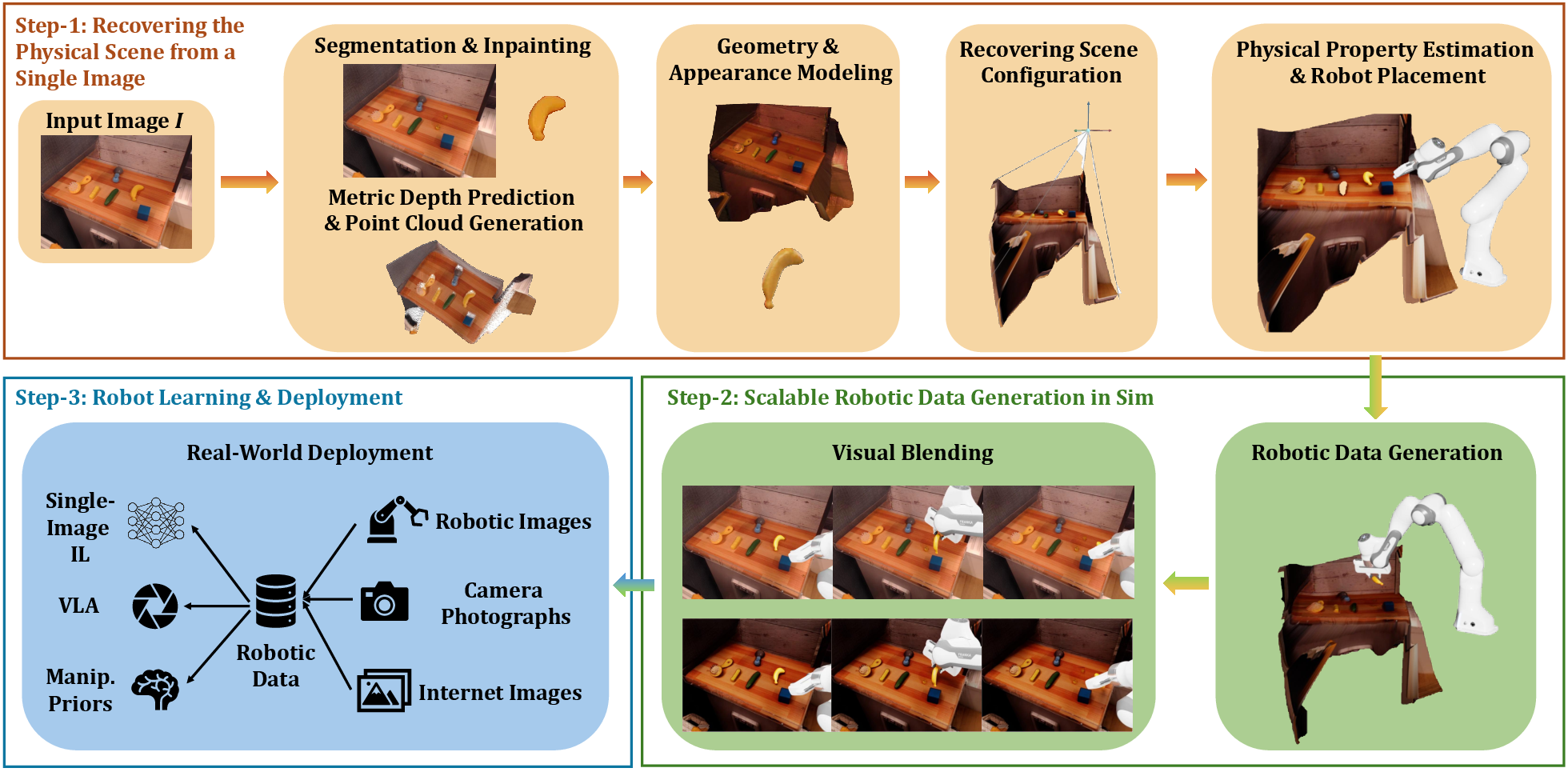
Figure 2: An overview of the RoLA framework illustrating the steps from scene recovery to policy deployment.
Experimental Evaluation
RoLA's efficacy was evaluated across several dimensions:
- Single-Image Scene Recovery: Comparisons with multiview reconstruction baselines showed that RoLA's single-image approach achieves parity, with less complexity and hardware requirements. In policy success rates, RoLA matched closely with the traditional multiview methods.
(Table 1)
Table 1: Comparison of policy success rates between multiview and single-view (RoLA) pipelines.
- Robotic Data Generation: Demonstrations generated by RoLA were benchmarked against retrieval-based and pixel-editing methods. RoLA showed a marked improvement in generating more physically faithful demonstrations and higher-quality policy learning outcomes.
- Real-World Deployment: Experiments indicated that RoLA supports efficient real-to-real deployment, effectively transferring policies trained on simulation data to physical robots. Additionally, RoLA proved adaptable across different robot types, including manipulators and humanoid robots, as visualized in Figure 3.
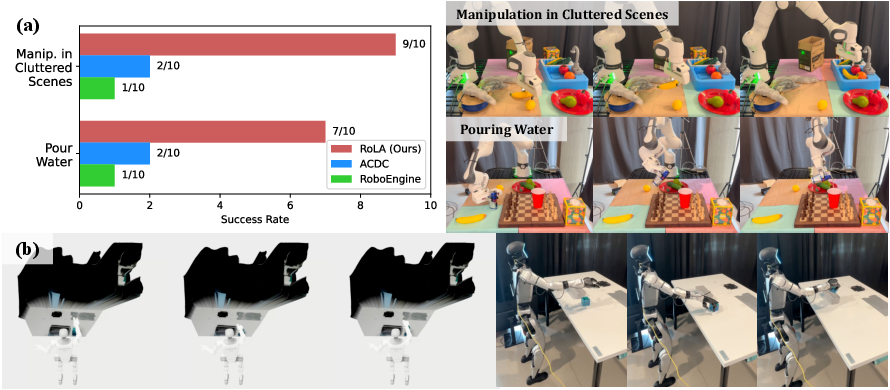
Figure 3: (a) Real-world deployment of policies trained with RoLA-generated data. (b) RoLA enables efficient real-to-sim-to-real transfer for humanoid robots.
- Vision-Language-Action Models: RoLA's scalability was harnessed for training Vision-Language-Action models, using vast amounts of generated data to support models that can generalize across diverse tasks and instructions.

Figure 4: Learning a vision-based apple grasping prior from Internet apple images.
Discussion and Implications
RoLA presents a shift toward leveraging vast in-the-wild visual data, democratizing access to scalable robotic data generation without necessitating controlled hardware setups. The framework excels in producing diverse, photorealistic demonstrations that are critical for training robust robotic policies. The pretraining on Internet image-derived data showcases RoLA's potential in enhancing real-world robotic learning.
The implications of this research are broad, suggesting that future robotic systems can be trained across a wider array of visual contexts, using Internet-sourced visuals as priors to amplify learning capabilities. As RoLA integrates more robust physics simulation tools and environment modeling techniques, the fidelity and application scope could significantly expand, making it a cornerstone in scalable robotic data generation.
Conclusion
RoLA introduces an innovative approach to robotic learning by enabling the transformation of single images into interactive environments, suitable for large-scale data generation and policy development. The framework opens up new possibilities for utilizing non-robotic data sources like Internet images, pushing the boundaries of real-world robotics applications. Through its pioneering use of visual blending and scene recovery technologies, RoLA represents a significant advancement toward realizing more generalizable and scalable robotic learning methodologies.

