MultiMat: Multimodal Program Synthesis for Procedural Materials using Large Multimodal Models
Abstract: Material node graphs are programs that generate the 2D channels of procedural materials, including geometry such as roughness and displacement maps, and reflectance such as albedo and conductivity maps. They are essential in computer graphics for representing the appearance of virtual 3D objects parametrically and at arbitrary resolution. In particular, their directed acyclic graph structures and intermediate states provide an intuitive understanding and workflow for interactive appearance modeling. Creating such graphs is a challenging task and typically requires professional training. While recent neural program synthesis approaches attempt to simplify this process, they solely represent graphs as textual programs, failing to capture the inherently visual-spatial nature of node graphs that makes them accessible to humans. To address this gap, we present MultiMat, a multimodal program synthesis framework that leverages large multimodal models to process both visual and textual graph representations for improved generation of procedural material graphs. We train our models on a new dataset of production-quality procedural materials and combine them with a constrained tree search inference algorithm that ensures syntactic validity while efficiently navigating the program space. Our experimental results show that our multimodal program synthesis method is more efficient in both unconditional and conditional graph synthesis with higher visual quality and fidelity than text-only baselines, establishing new state-of-the-art performance.















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new AI system (the authors call it “ProjectName”) that helps create “procedural materials” for 3D graphics. Procedural materials are like recipes that automatically generate textures for 3D objects—such as color, roughness, metallic shine, and bumpiness—by combining building blocks in a visual flowchart called a node graph. Making these graphs by hand is powerful but can be hard and time-consuming. The authors show how an AI that can both “see” images and “read” text can build these graphs more easily and more accurately than older methods that only read text.
Key Objectives
The paper focuses on solving three simple goals:
- Make it easier and faster to automatically create procedural material graphs, the visual “recipes” that produce textures for 3D objects.
- Use visual feedback (pictures of what each step produces) while the AI is building the graph, not just text, so the AI can “see” if what it’s making looks right.
- Ensure the graphs are valid and fix common mistakes as the AI builds them, instead of waiting until the end to check.
How the System Works
Think of a procedural material as a cooking recipe made of small steps (nodes) connected by arrows (edges) in a flowchart. Each node either makes new image content (like noise or patterns) or changes it (like blending or blurring). The final result is a set of texture maps used for realistic 3D rendering.
Here’s how the authors’ approach builds these recipes:
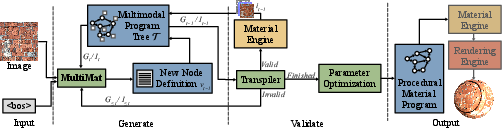
- Multimodal AI: The model is “multimodal,” meaning it can use both text and images. In practice, it looks at:
- A visual diagram of the current graph (like a screenshot of the flowchart and mini previews of each node’s output).
- A compact, easy-to-read text format of the graph (a simplified version of Adobe Substance Designer’s file format).
- Step-by-step generation: Instead of writing the whole program at once, the AI adds one node at a time in the correct order. After each node:
- A “transpiler” (think of it like a translator) converts the AI’s compact graph text back into the official format used by the material tool.
- The material engine runs that node and shows what it looks like. These mini images are fed back to the AI so it can “see” how it’s doing.
- Two ways to condition on visuals:
- Mixed conditioning: The AI reads a text description of the graph but also sees small image previews mixed in.
- Graph conditioning: The AI looks at the whole graph as one big picture with embedded previews and uses only that visual context to decide the next node.
- Incremental tree search: If the AI adds a node that causes an error (like wrong connection types), it doesn’t wait until the end to find out. It notices right away, backs up a step (or more, if needed), and tries a different path—similar to testing different branches in a maze until it finds a valid route.
- Automatic error repair: The system can fix common mistakes on the fly, like:
- Removing extra parameters that a node doesn’t support.
- Auto-inserting conversion nodes when a color image needs to connect to a grayscale input (or vice versa), just like an autocorrect for graphs.
- Training data and tooling: The authors built a large dataset of over 6,000 real, production-quality materials from Adobe’s Substance 3D Assets, and wrote a translator to convert complex graphs into compact text the AI can learn from while supporting all features (including advanced ones like pixel processors and function graphs).
Main Findings and Why They Matter
The authors tested their system in two situations:
- Unconditional generation: Creating new, original materials from scratch.
- Conditional generation (inverse modeling): Recreating a material graph that matches a given picture.
Across both tasks, their multimodal approach (especially the “graph conditioning” where the AI sees the full visual graph) produced:
- Higher visual quality and better faithfulness to target images than text-only baselines.
- Fewer mistakes and more efficient building of valid graphs, thanks to the step-by-step checking and backtracking.
- Very low signs of copying the training data (good generalization).
They also tried a fine-tuning step called parameter optimization, which is like adjusting the knobs on each node using math so the rendered output looks even closer to the target image. This improved the match further in the conditional task.
Why this matters: It shows that giving an AI visual feedback while it “writes” a visual program leads to much better results than relying on text alone. This reflects how human artists work: they tweak node graphs by looking at the intermediate images. Bringing that visual loop into the AI makes it smarter and more reliable.
Implications and Impact
This research could make life easier for 3D artists and game or film studios by:
- Speeding up material creation: The AI can suggest complete materials or fill in missing parts of a graph, like smart auto-complete.
- Turning photos into procedural materials: Artists could point the system at a texture photo and get a reusable procedural version with adjustable parameters.
- Scaling across tools and domains: The same idea—using visual feedback to build visual programs—could apply to other areas, like vector graphics or data visualization tools that also use node graphs.
The authors note one limitation: training this multimodal, step-by-step system takes longer than training a text-only model because the AI needs updated images at each node. However, once trained, it runs at similar speeds to other methods. They plan to generate extra training data automatically and explore models that work across multiple tools to further improve performance and generalization.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list enumerates what remains missing, uncertain, or unexplored in the paper. Each point is phrased to be directly actionable for future research.
- Generalization beyond Substance Designer: The approach is not evaluated across other node-graph systems (e.g., Blender, Houdini, MaterialX), leaving transferability and cross-system training untested.
- Dataset representativeness and bias: The dataset is restricted to licensed Substance 3D Assets, excludes community assets, bitmaps, and SVGs, and is pruned to five PBR outputs; the impact of these filters on diversity, realism, and generalization is unquantified.
- Scalability to very large graphs: Models are evaluated on graphs capped at 128 nodes, but production materials can far exceed this (e.g., >400); the method’s stability, memory footprint, and accuracy at larger scales are unknown.
- Hierarchical and modular graphs: Preprocessing flattens hierarchical subgraphs and external dependencies; the ability to learn and generate reusable modular structures (subgraphs, libraries) remains unaddressed.
- Reproducibility and release: It is unclear whether the dataset, transpiler, graph visualizer, and training code will be released; without them, external validation and benchmarking are obstructed.
- Evaluation on real photographs: Conditional generation is evaluated on rendered images; performance on real-world photographs (varying lighting, geometry, capture noise) is unknown.
- Lighting and geometry invariance: Reconstruction metrics do not test robustness across changes in illumination, camera, and target geometry; generalization across rendering conditions needs systematic assessment.
- Human evaluation and artist workflow: No user studies quantify subjective fidelity, editability, or integration benefits in professional pipelines compared to text-only baselines.
- Metric validity for materials: KID, CLIP, DreamSim, and style loss may not fully capture material plausibility (e.g., microstructure, anisotropy); domain-specific perceptual metrics for PBR materials are needed.
- Inference efficiency reporting: Aside from Node Error Ratio (NER), there are no wall-clock, GPU memory, or throughput comparisons; practical latency and resource costs during interactive use remain unclear.
- Training efficiency: Per-node multimodal training is significantly slower than text-only baselines; techniques like caching visual contexts, batched node updates, curriculum learning, or parameter sharing are not explored.
- Ablations of key components: The paper lacks controlled ablations for (a) tree-search schedule, (b) automatic error repair, (c) image resolution/patch count, (d) graph layout choices, and (e) transpiler compaction effects.
- Termination and complexity control: Stopping criteria and mechanisms to control graph size/complexity (e.g., target node counts, resource budgets) are not formalized or evaluated.
- Layout sensitivity and OCR robustness: Graph-conditioned models experience OCR-like errors from text embedded in images; the impact of graph layout, font, and visual clutter on accuracy and possible text-aware encoders remains open.
- Mixed conditioning omissions: Mixed conditioning omits node parameters assuming previews suffice; the rate of parameter ambiguity or non-visible semantics (e.g., function graph logic, color space flags) is not quantified.
- Automatic error repair coverage: Repair rules focus on extraneous params and type conversions; the breadth of fixable errors, risks of silently altering semantics, and formal guarantees of physical plausibility are unstudied.
- Structural optimization: Differentiable refinement optimizes parameters only; jointly optimizing graph structure (node types, connections) remains unexplored.
- Differentiability limits: The coverage of differentiable operators in DiffMat and its impact on optimization quality, stability, and convergence is not analyzed; optimization failures are not characterized.
- Physical plausibility constraints: No explicit constraints enforce material realism (e.g., valid roughness ranges, energy-conserving BRDF parameters); learning or enforcing such constraints is open.
- Robustness to out-of-distribution materials: Performance on stylized, highly anisotropic, emissive, or non-PBR materials (and maps beyond the five evaluated channels) is not studied.
- Generalization across foundation models: Only Qwen variants are tested; sensitivity to model size, architecture, and pretraining across different LMMs/LLMs (e.g., LLaVA, Idefics, GPT-4V) is unknown.
- Statistical significance and variance: Results are reported over 100 samples without confidence intervals or variance; the stability of metrics across seeds and runs is not established.
- Ensemble or hybrid conditioning: Potential gains from combining mixed and graph conditioning (e.g., late fusion, co-training, distillation) are not investigated.
- Attention/interp analysis: How visual context guides token generation (e.g., attention maps over graph regions or node previews) is not analyzed; opportunities for model debugging and controllability remain.
- Safety and IP risks: While licensing is addressed, the propensity to reproduce or approximate proprietary materials (style leakage, near-duplicates) and mitigation strategies are not examined.
- Integration in interactive tools: Latency, partial graph editing, co-creative auto-completion, and failure recovery within a live Substance Designer session are not benchmarked.
- Handling non-atomic/custom nodes: External references to non-atomic library nodes are preserved; the model’s ability to instantiate or learn custom node semantics has not been evaluated.
- Control via high-level intent: Mapping text prompts or semantic descriptors (e.g., “oxidized copper, fine grain”) to graph structure and parameters is not explored in this multimodal setting.
- Search strategy alternatives: The backtracking schedule (discard 2i−1 recent nodes) is heuristic; principled alternatives (beam search, MCTS, guided decoding with validators) may improve efficiency and are not compared.
Practical Applications
Below is a concise synthesis of practical, real-world applications enabled by the paper’s findings, methods, and innovations (multimodal conditioning over visual node graphs, incremental tree search with auto-repair, and SBS↔sbs transpilation). Each item lists concrete use cases, relevant sectors, potential tools/workflows, and key feasibility dependencies.
Immediate Applications
- AI copilot for procedural material authoring (Software, Media/VFX, Games)
- Use cases: Node auto-completion, next-node suggestions, parameter proposals, and topology-aware graph fixes inside Adobe Substance Designer/Blender-like tools.
- Tools/workflows: “Material Copilot” plugin leveraging mixed/graph conditioning plus incremental validation and auto-repair; contextual previews as the model generates each node.
- Dependencies/assumptions: Substance Designer Automation API (or equivalent), GPU for inference, adherence to supported node types; acceptance of the compact sbs format.
- Inverse material capture from images (Media/VFX, Games, AR/VR, Design/Architecture, E-commerce)
- Use cases: Turn product or on-set photos into resolution-independent PBR materials; match scanned surfaces for set extension, digital doubles, and retail swatches.
- Tools/workflows: “Capture-to-Graph” tool (image→graph) with optional differentiable parameter optimization to refine visual match.
- Dependencies/assumptions: Differentiable renderer availability (e.g., DiffMat), robust handling of out-of-distribution materials, proper lighting/normalization of source images.
- Batch “proceduralization” of texture libraries (Media/VFX, Games, Enterprises)
- Use cases: Convert legacy bitmap texture libraries to procedural graphs for storage savings, infinite tiling, and easy re-parameterization.
- Tools/workflows: Headless service/CLI that ingests folders of bitmaps and outputs sbs/SBS graphs; optional human-in-the-loop QA.
- Dependencies/assumptions: Rights to process assets; compute budget for batch inference/optimization; coverage of common material families in the training set.
- Graph linting and automated repair for node pipelines (Software Tooling, Production Engineering)
- Use cases: CI/CD-style validation of large graph libraries; automatic fixes for type mismatches and extraneous parameters.
- Tools/workflows: “Graph Linter/Repairer” using incremental transpile→execute checks and the paper’s repair rules (e.g., auto grayscale/color conversion nodes).
- Dependencies/assumptions: Engine access for stepwise execution; completeness of rule set for studio-specific nodes.
- Rapid material ideation and look development (Media/VFX, Games)
- Use cases: Unconditional generation to explore style spaces and variants; quick exploration of roughness/albedo/displacement looks.
- Tools/workflows: “Material Ideation Panel” that proposes diverse starting graphs; artists refine or chain to parameter optimization.
- Dependencies/assumptions: Artistic oversight to curate outputs; safe sampling settings and model prompts tailored to studio styles.
- Education and onboarding for procedural materials (Academia, EdTech, Studios)
- Use cases: Teach procedural thinking with stepwise, visually-grounded graph generation and intermediate previews.
- Tools/workflows: Interactive lessons that show graph images plus rendered intermediates; assignments where students steer the copilot.
- Dependencies/assumptions: Access to teaching licenses or open tools; simplified curricula aligned with supported node sets.
- Interoperable, diff-friendly graph assets with the sbs representation (Software, DevOps)
- Use cases: Version control, code review, and collaboration on material graphs; reproducible builds across machines.
- Tools/workflows: SBS↔sbs transpiler integrated into build systems; pre-commit hooks that validate/format graphs; human-readable reviews.
- Dependencies/assumptions: Fidelity of transpilation for the full Designer feature set; team adoption of the compact YAML format.
- Image-based material search and retrieval (E-commerce, Asset Management)
- Use cases: Query a studio library by dropping a reference image; retrieve closest procedural graphs for reuse.
- Tools/workflows: CLIP-like embeddings over rendered maps; retrieval returns graphs with editable parameters rather than fixed bitmaps.
- Dependencies/assumptions: Embedding pipeline and index; consistent rendering normalization for fair similarity.
- Simulation-ready texture variation for domain randomization (Robotics, Autonomy, Synthetic Data)
- Use cases: Generate families of materials with controlled variability to improve sim-to-real transfer in perception models.
- Tools/workflows: Parameterized templates generated unconditionally, exported to Unity/Unreal/Isaac Sim pipelines.
- Dependencies/assumptions: Connectors to target simulators; validation that procedurally-generated distributions improve downstream metrics.
- Pipeline efficiency in productions (Production Management)
- Use cases: Reduce iteration cycles for material tasks; lower error rates via early validation and partial backtracking.
- Tools/workflows: Integrate incremental tree search inference in dailies/tools; automated logs highlighting invalid-node hotspots.
- Dependencies/assumptions: Minimal runtime overhead acceptable to teams; instrumentation that surfaces meaningful diagnostics.
Long-Term Applications
- Cross-tool, unified multimodal program synthesizer for visual node systems (Software, Standards)
- Use cases: Extend beyond Substance Designer to Blender/Unreal/Unity shader graphs, Nuke compositing, Houdini networks, vector graphics editors.
- Tools/workflows: A multi-domain copilot trained across node systems with transfer learning; one model that “speaks” many graph dialects.
- Dependencies/assumptions: Training data and transpilers for each host system; consistent visual context design; licensing for proprietary formats.
- Real-time mobile/AR “photo-to-material” capture (Consumer Apps, AR/VR)
- Use cases: Live capture and immediate creation of procedural, tileable materials from a phone or headset for AR staging or on-site previz.
- Tools/workflows: On-device or edge-cloud inference with fast parameter optimization; UX for lighting normalization and region selection.
- Dependencies/assumptions: Compact, low-latency models; robust handling of uncontrolled lighting; privacy safeguards for user images.
- Open standard for human-readable material graph exchange (Policy, Standards, Software)
- Use cases: An industry-backed, audit-friendly format (inspired by sbs) for interchange, reproducibility, and compliance auditing.
- Tools/workflows: Standard spec, conformance tests, and reference transpilers; provenance metadata and signed manifests.
- Dependencies/assumptions: Multi-vendor alignment; governance body; mappings for proprietary features and future-proofing.
- End-to-end text→3D asset pipelines with integrated procedural materials (Media/VFX, Games, E-commerce)
- Use cases: Generate 3D meshes, UVs, and physically-based materials from a brief; consistent art direction via text/image constraints.
- Tools/workflows: Multi-agent pipeline combining geometry generation, material graph synthesis, and differentiable refinement.
- Dependencies/assumptions: Reliable mesh/UV generation; alignment between material and geometry pipelines; compute budget.
- Self-learning data expansion for conditional models (Academia, R&D)
- Use cases: Close data scarcity gaps by generating synthetic supervised pairs (graph→render→train inverse).
- Tools/workflows: Scheduled self-training loops; quality filters to avoid mode collapse or memorization.
- Dependencies/assumptions: Render farms; robust overfitting detection; curriculum design for synthetic data.
- Digital twins with physically-faithful, parameterized materials (AEC, Manufacturing)
- Use cases: Scan and proceduralize real-world surfaces for calibrated digital twins; sensitivity studies via parameter sweeps.
- Tools/workflows: Capture-to-Graph plus measured BRDF/normal data; twin platforms ingest parameterized materials.
- Dependencies/assumptions: Accurate capture pipelines; integration with simulation engines; validation against field measurements.
- Rights-aware, provenance-preserving material marketplaces (Policy, Platforms)
- Use cases: Sell procedural materials with transparent training provenance and license terms; watermarking and usage tracking.
- Tools/workflows: Provenance metadata embedded in sbs; licensing checks; content authenticity signals.
- Dependencies/assumptions: Community norms and enforcement; low-friction licensing UX; interoperable provenance standards.
- Multimodal, collaborative UX for graph editing (HCI, Creative Tools)
- Use cases: Voice/gesture-driven graph authoring; collaborative sessions where AI suggests topology and artists tweak intent.
- Tools/workflows: Shared canvas with live graph-conditioned previews; intent-driven constraints (“less metallic”, “more micro-scratches”).
- Dependencies/assumptions: Robust grounding of natural language in graph operations; real-time model responsiveness.
- Generalized linter/repair frameworks for visual programming (Software Engineering)
- Use cases: Apply incremental search and auto-repair concepts to other visual DSLs (e.g., ETL pipelines, node-based AI graphs).
- Tools/workflows: Domain-adapted validators that catch type/connectivity errors early and propose minimal repairs.
- Dependencies/assumptions: Formalization of type systems and execution semantics per domain; execution harnesses for validation.
- Robust sim-to-real texture generalization at scale (Robotics, Autonomy)
- Use cases: Continual, targeted material generation to close perception gaps discovered in the field.
- Tools/workflows: Active learning loop: deploy→collect failures→generate new procedural variants→retrain.
- Dependencies/assumptions: Feedback telemetry; automated labeling of failure modes; MLOps maturity.
Notes on feasibility across applications:
- Model/engine access: Many workflows assume API access to Substance Designer (or equivalents) and the ability to render intermediate states.
- Compute/latency: Multimodal contexts and optimization steps imply GPU usage; mobile/AR use cases require compression or edge offloading.
- Data/coverage: Generalization is best within the training distribution; rare or highly specialized materials may need fine-tuning.
- Legal/ethics: Asset licensing, provenance tracking, and user privacy for input images must be respected; marketplace scenarios require clear rights management.
- Adoption/UX: Artist trust and interactive latency are crucial; suggestions must be interpretable and easily editable within existing DCC workflows.
Glossary
- Adobe Substance Designer: A professional tool for creating procedural material graphs via a node-based visual interface. "Among these tools, Adobe Substance Designer stands out for its particularly expressive node graph system, which \projectname specifically targets."
- Albedo: The base color component of a material’s reflectance, independent of lighting. "reflectance such as albedo and conductivity maps."
- CLIP: A vision-LLM used here via its image embeddings for perceptual similarity evaluation. "we measure cosine similarity between \thead{\clip} image embeddings~\citep{radford2021clip,hessel2021clipscore}"
- Conductivity maps: Texture maps representing a surface’s electrical/optical conductivity properties for rendering. "reflectance such as albedo and conductivity maps."
- DiffMat: A differentiable renderer for Substance materials used to optimize graph parameters. "We employ \diffmat~\citep{shi2020match,li2023end}, a widely adopted differentiable renderer for Designer materials"
- Differentiable renderer: A renderer that supports gradient computation with respect to inputs, enabling optimization. "a widely adopted differentiable renderer for Designer materials"
- Directed acyclic graph (DAG): A graph with directed edges and no cycles; used to structure material node graphs. "their directed acyclic graph structures and intermediate states provide an intuitive understanding and workflow for interactive appearance modeling."
- DSIM (DreamSim): A learned perceptual similarity metric aligned with human judgments. "calculate \dsim*~(\thead{\dsim}; \citealp{fu2023dreamsim}), a learned perceptual similarity metric designed to align with human judgments."
- Function graphs: Subgraphs that compute parameter values via custom functions in Designer. "Function graphs allow parameters to be controlled through custom operations on input values"
- Gram matrix: A matrix of feature correlations used in style comparison metrics. "as the L1 distance between Gram matrices of VGG features"
- Graph conditioning: Conditioning the model solely on a visual rendering of the graph and intermediate outputs. "Graph Conditioning] This approach more closely mirrors human visual experience by conditioning \projectname solely on a visualization of the entire graph with embedded intermediate visual outputs "
- Gradient-based optimization: Optimization that uses gradients to refine parameters of generated material graphs. "we apply gradient-based optimization using differentiable rendering."
- Gradient map: A node that maps grayscale values to a color gradient, often used for type conversion. "we insert a gradient map node to perform type conversion."
- Grayscale conversion: Converting color outputs to grayscale to resolve type mismatches between nodes. "we automatically insert an appropriate grayscale conversion node."
- Inverse rendering: Inferring procedural material graphs that reproduce target images. "enabling applications such as inverse rendering~\citep{patow2003inverse}, i.e., generating procedural materials that match the appearance of captured or rendered images."
- Kernel Inception Distance (KID): A metric comparing the distribution of generated images to a reference set to assess quality. "we compute the Kernel Inception Distance (\thead{\kid}; \citealp{binkowski2018kid})"
- Large multimodal models (LMMs): Models that jointly process text and images; here used for program synthesis of materials. "leverages large multimodal models to process both visual and textual graph representations"
- Mixed conditioning: Conditioning on a textual graph representation interleaved with image embeddings of node previews. "Mixed Conditioning] Starting with a textual representation of ... This creates a multimodal program where the model processes textual tokens interleaved with image patch embeddings"
- Node Error Ratio (NER): The proportion of discarded nodes relative to all generated nodes, measuring efficiency. "we introduce the Node Error Ratio (\thead{\ner}), defined as the average ratio between discarded nodes and the total number of generated nodes."
- Non-destructive editing: An editing workflow where changes don’t permanently alter prior states of the material graph. "non-destructive editing workflows"
- OCR: Optical Character Recognition; here, OCR-like misreadings of text in graph images cause generation errors. "For \projectname[Graph], these errors are primarily due to OCR-like errors in reading node names and function types embedded as text in graph images."
- Parameter optimization: A post-generation refinement step to better match target images by adjusting node parameters. "Following optional parameter optimization (cf.\ \secref{sec:conditional}), the final procedural material can be applied to any target geometry for rendering."
- Physically-based rendering (PBR): A rendering approach that uses physically grounded material properties. "ultimately producing the texture maps required by physically-based rendering (PBR) models~\citep{PBRT3e}"
- Pixel processors: Designer nodes enabling per-pixel computational graphs from atomic operations. "pixel processors enable users to define specialized computational graphs that operate on individual pixels"
- Procedural materials: Materials generated algorithmically via node graphs rather than fixed images. "Procedural materials have become increasingly important in modern 3D content creation"
- ROUGE-L: A text overlap metric (longest common subsequence) used here to detect memorization in generated programs. "we also calculate \thead{\rougel} scores~\citep{lin2004rouge}"
- Style loss: A perceptual loss measuring differences in feature correlations for style similarity. "compute \style* loss (\thead{\style}; \citealp{gatys2016styleloss}) as the L1 distance between Gram matrices of VGG features"
- Substance 3D Assets Repository: A curated dataset of production-quality procedural materials used for training/evaluation. "we collect procedural materials from Adobe's Substance 3D Assets Repository~\citep{SubstanceAssets2025}."
- SBS (Substance Designer file format): Designer’s native (XML-based) project format, verbose and not model-friendly. "Substance Designer's native file format (\sbs[]) has not been designed for human readability"
- Topological generation: Generating nodes in an order where each node comes before any nodes it connects to. "Unlike previous approaches, \projectname generates nodes topologically, ensuring each node precedes all nodes it connects to."
- Tree search: Exploring possible program continuations with backtracking to find valid graphs efficiently. "This approach effectively transforms our generation process into an incremental tree search on a tree of valid and invalid nodes"
- Transpiler: A tool that converts between Designer’s SBS and a compact textual representation for modeling. "We implement a transpiler that converts between Adobe Substance Designer formats and a compact representation suitable for language modeling"
- Vision-LLM: A model that processes both visual and textual inputs to generate outputs; here, material graphs. "At its core, \projectname is a vision-LLM, trained for synthesizing procedural material graphs."
- VGG features: Deep CNN features from VGG used to compute perceptual/style losses. "as the L1 distance between Gram matrices of VGG features"
- YAML-based representation: A compact, human-readable format used as the modeling interface instead of raw SBS. "a compact, human-readable YAML-based representation with topological node order"
Collections
Sign up for free to add this paper to one or more collections.