- The paper shows that implicit-bias-based reconstruction attack objectives admit infinitely many global minima without strong prior knowledge.
- It employs constructive merging and splitting techniques to demonstrate the non-uniqueness of KKT-based reconstructions under gradient-based training.
- Empirical results reveal that reconstruction accuracy degrades as the attacker's prior knowledge weakens, confirming the impracticality of the attack.
No Prior, No Leakage: Revisiting Reconstruction Attacks in Trained Neural Networks
Introduction and Motivation
The paper "No Prior, No Leakage: Revisiting Reconstruction Attacks in Trained Neural Networks" (2509.21296) provides a rigorous theoretical and empirical analysis of the limitations of implicit-bias-based reconstruction attacks on neural networks. These attacks, notably those introduced by Haim et al., attempt to recover training data from model parameters by exploiting the implicit bias of gradient-based optimization, particularly the tendency of homogeneous networks to converge to max-margin solutions. While prior work has demonstrated striking empirical success in reconstructing training data, this paper challenges the reliability and generality of such attacks, especially in the absence of strong prior knowledge about the data domain.
Theoretical Analysis of Reconstruction Attack Limitations
The core of the analysis is the reconstruction attack objective, which seeks candidate training data and associated Lagrange multipliers that minimize a loss enforcing the KKT conditions of the max-margin problem solved by the trained network. The paper demonstrates, both constructively and formally, that this objective admits infinitely many global minima when no prior knowledge is incorporated. Specifically, the authors provide explicit merging and splitting constructions (Lemmas 1 and 2) that generate alternative KKT sets—candidate training sets that are indistinguishable from the true set with respect to the KKT loss.
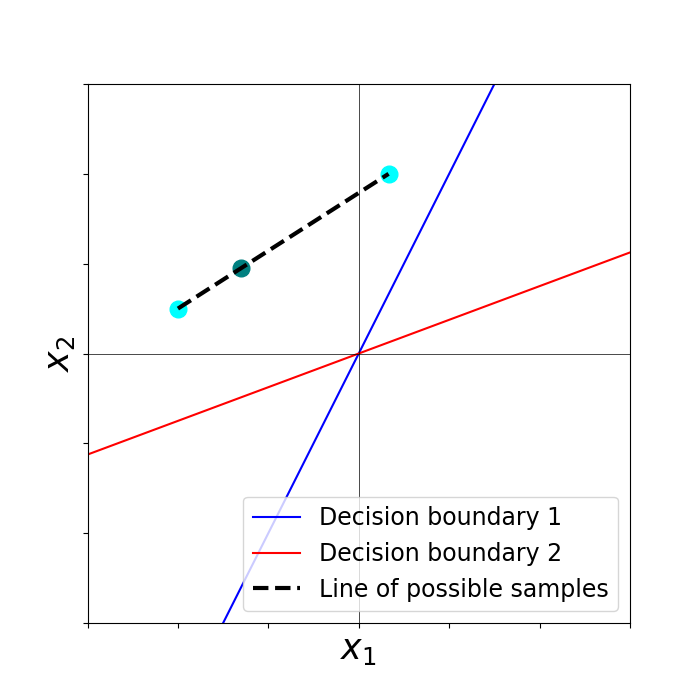
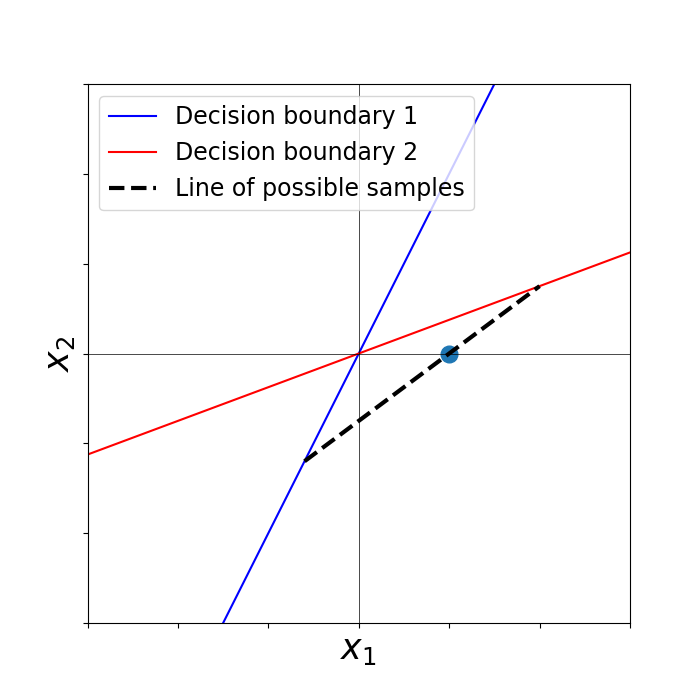
Figure 1: Example of Lemma~\ref{lma:unite_points_bias}, illustrating how two points with identical labels and activation patterns can be merged into a single representative point, preserving the KKT conditions.
The merging operation allows two points with identical labels and activation patterns to be replaced by a convex combination, while the splitting operation allows a single point to be replaced by two points along a direction that preserves activation patterns and classification. Theoretical results (Theorem 1) show that, under mild assumptions (e.g., the training data does not span the entire input space), these alternative KKT sets can be constructed to be arbitrarily far from the true training set. This implies that, in the absence of prior knowledge, the solution to the reconstruction objective is fundamentally non-unique and unreliable.
The analysis is extended to the more realistic setting where the network only approximately satisfies the KKT conditions (the (ε,δ)-KKT setting). The authors show that similar merging and splitting constructions remain possible, with explicit lower bounds on the distance between the true and alternative KKT sets as a function of the smallest singular value of the data matrix and the degree of approximation to the KKT point. Notably, as the network is trained more extensively (i.e., as ε→0), the space of indistinguishable KKT sets expands, further reducing the efficacy of reconstruction attacks.
Empirical Validation
The theoretical findings are supported by empirical experiments on both synthetic and real-world data. The experiments model the attacker's prior knowledge as the radius of the initialization distribution for the candidate reconstructions. When the attacker is initialized with points close to the true data domain (strong prior), reconstruction is more successful. However, as the initialization radius increases (weaker prior), the quality of the reconstruction degrades significantly, even though the KKT objective is minimized to similar values.
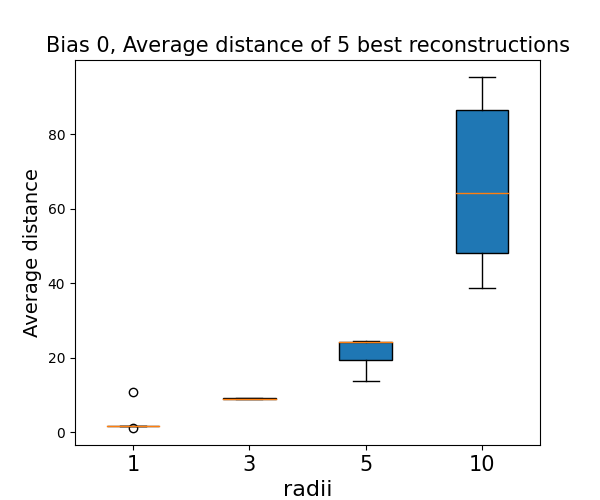


Figure 2: A comparison of the reconstruction results based on initializations with different radii, for a network trained with data sampled from the unit sphere. The average Euclidean distance of the 5 best reconstructions increases as the attacker's prior weakens, demonstrating the unreliability of the attack without prior knowledge.
On CIFAR, the authors further demonstrate that shifting the training data by a secret bias (unknown to the attacker) effectively thwarts reconstruction, even when the attacker has access to the full model parameters and architecture. Reconstructions in this setting resemble averages or interpolations of multiple training instances, rather than accurate recovery of the original data.
Implications and Contradictory Claims
A key claim, supported by both theory and experiment, is that implicit bias alone does not necessarily leak information about the training data. In fact, the paper shows that as the network is trained more thoroughly and the implicit bias conditions are more strongly satisfied, the susceptibility to reconstruction attacks decreases. This is in direct contradiction to the intuition that stronger implicit bias (and thus better generalization) would increase privacy risk.
The results also highlight the critical role of prior knowledge in the success of reconstruction attacks. Without such knowledge—such as the data domain, distributional assumptions, or even the range of valid pixel values—reconstruction is fundamentally unreliable. This suggests that simple defenses, such as shifting the training data by a secret bias, can be highly effective in practice.
Practical and Theoretical Implications
From a practical perspective, the findings suggest that privacy risks from implicit-bias-based reconstruction attacks are overstated in the absence of strong priors. Defenses that obfuscate the data domain or inject uncertainty into the data distribution can significantly mitigate these risks. Theoretically, the work refines the understanding of information leakage in overparameterized models and clarifies the limitations of attacks that rely solely on the implicit bias of gradient-based optimization.
The results also motivate further research into the privacy properties of more complex architectures (e.g., LLMs, diffusion models) and training regimes (e.g., non-homogeneous networks, practical optimizers). The analysis of information leakage in these settings remains an open challenge, particularly as models are increasingly deployed in privacy-sensitive applications.
Conclusion
This paper provides a comprehensive theoretical and empirical refutation of the reliability of implicit-bias-based reconstruction attacks in the absence of prior knowledge. By demonstrating the ubiquity of alternative global minima and the non-uniqueness of the reconstruction objective, it establishes that such attacks are fundamentally unreliable without strong priors. The work has significant implications for both the assessment of privacy risks in neural networks and the design of practical defenses, and it opens new directions for the study of information leakage in modern machine learning systems.