MMR1: Enhancing Multimodal Reasoning with Variance-Aware Sampling and Open Resources
Abstract: Large multimodal reasoning models have achieved rapid progress, but their advancement is constrained by two major limitations: the absence of open, large-scale, high-quality long chain-of-thought (CoT) data, and the instability of reinforcement learning (RL) algorithms in post-training. Group Relative Policy Optimization (GRPO), the standard framework for RL fine-tuning, is prone to gradient vanishing when reward variance is low, which weakens optimization signals and impairs convergence. This work makes three contributions: (1) We propose Variance-Aware Sampling (VAS), a data selection strategy guided by Variance Promotion Score (VPS) that combines outcome variance and trajectory diversity to promote reward variance and stabilize policy optimization. (2) We release large-scale, carefully curated resources containing ~1.6M long CoT cold-start data and ~15k RL QA pairs, designed to ensure quality, difficulty, and diversity, along with a fully reproducible end-to-end training codebase. (3) We open-source a family of multimodal reasoning models in multiple scales, establishing standardized baselines for the community. Experiments across mathematical reasoning benchmarks demonstrate the effectiveness of both the curated data and the proposed VAS. Comprehensive ablation studies and analyses provide further insight into the contributions of each component. In addition, we theoretically establish that reward variance lower-bounds the expected policy gradient magnitude, with VAS serving as a practical mechanism to realize this guarantee. Our code, data, and checkpoints are available at https://github.com/LengSicong/MMR1.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI models to think better using both text and pictures (that’s “multimodal”). The authors noticed two big problems: it’s hard to find open, high-quality training data that shows long, step-by-step reasoning, and a popular training method called reinforcement learning (RL) can become unstable. They introduce a new way to choose training questions, called Variance-Aware Sampling (VAS), and they also share large, carefully built datasets and open-source models so others can improve multimodal reasoning too.
Key Objectives
The paper asks three simple questions:
- How can we make RL training more stable when training reasoning models?
- Can we pick training questions in a smarter way so the model learns more from each practice round?
- Will better-curated, open datasets and code help the whole community build stronger multimodal reasoning models?
Methods and Approach
What is the problem with current training?
- Multimodal reasoning models learn by trying to answer a question many times and getting a score (a “reward”) for each try.
- A popular RL method, GRPO, compares a group of answers for each question and updates the model based on their scores.
- But if all answers have similar scores (little variation), the learning signal becomes very weak. This is called “gradient vanishing,” and training slows down or becomes unstable.
Think of it like practicing math: if every question you try is either always easy (you always get it right) or always impossible (you always get it wrong), you don’t learn much. You learn best when questions are challenging enough that you sometimes get them right and sometimes wrong—and when you try different solution paths.
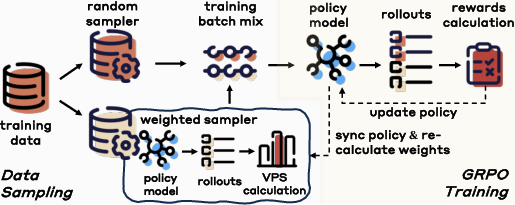
Their idea: Variance-Aware Sampling (VAS)
VAS is a smart way to pick which questions to train on. It uses a score called VPS (Variance Promotion Score) to find questions that are most helpful for learning. VPS combines two parts:
- Outcome Variance Score (OVS): This favors questions where the model’s pass rate is around 50% (half right, half wrong). That balance creates more useful variation in rewards, which helps learning.
- OVS is calculated as pass_rate × (1 − pass_rate), so it’s highest at 0.5.
- Trajectory Diversity Score (TDS): This measures how different the step-by-step solutions are across multiple attempts. More diverse thinking paths give stronger learning signals, even when the final answers are often wrong or noisy.
They then build each training batch by:
- Picking some questions with higher VPS (more informative and varied).
- Mixing in some random questions (to keep overall coverage and avoid focusing too narrowly).
This balance keeps training stable and effective.
Theory behind the method
The authors prove a simple but powerful idea: when the rewards (scores) for a question vary more, the learning step is guaranteed to be stronger. In other words, reward variance lowers bounds the useful “push” the model gets from each update. VAS is a practical way to increase that variance by choosing the right questions.
Data and models they release
- About 1.6 million long, step-by-step chain-of-thought (CoT) examples for supervised training (to give the model a strong starting point).
- About 15,000 short-answer RL questions, carefully chosen to be diverse and challenging.
- Open-source code and different-sized models, so others can reproduce and build on their work.
Main Findings
Here are the main results, explained simply:
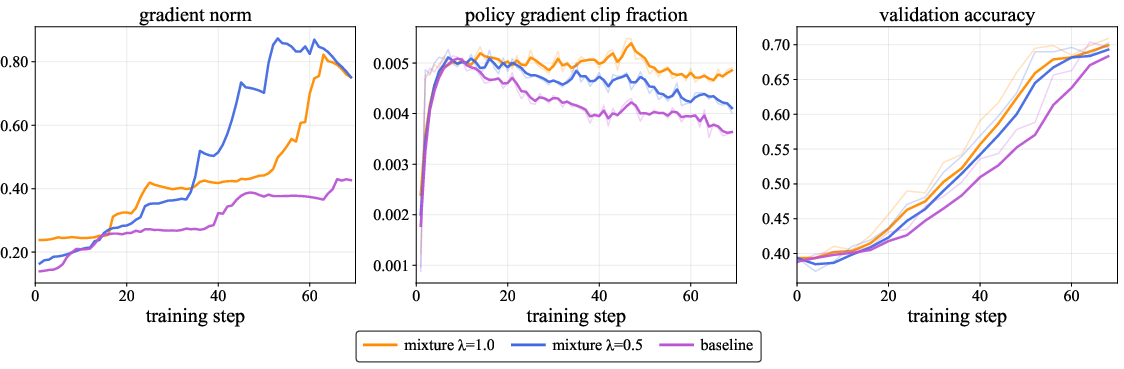
- Training becomes more stable: With VAS, the learning signals are stronger and less likely to fade. The model makes more meaningful updates each step.
- Better performance on tough benchmarks: Their 7B model reaches top scores across math and logic datasets like MathVerse, MathVista, MathVision, LogicVista, and ChartQA. Their smaller 3B model also performs impressively—often matching or beating other 7B models.
- Each piece helps: Starting with long CoT training gives a good base. Adding RL makes the model explore and reason better. Adding VAS on top makes RL training steadier and more effective.
- Clear efficiency gains: Measures like gradient strength and clip fraction indicate that VAS leads to stronger, well-controlled learning and faster convergence.
- OVS and TDS both matter: Experiments show that balancing correctness variability (OVS) and diversity of reasoning steps (TDS) gives the most reliable improvements.
Implications and Impact
This work could make it much easier for researchers and developers to train strong multimodal reasoning models:
- Smarter training: Choosing the right questions—those that are neither too easy nor too hard, and that encourage varied thinking—can dramatically improve learning.
- Open resources: The released datasets, models, and code help the whole community build, test, and compare new ideas more fairly and quickly.
- More robust reasoning: Better training stability means models can handle complex, multi-step problems in math, logic, and beyond more reliably.
Limitations and future directions
- VAS helps stability but doesn’t solve all RL issues.
- Computing VPS adds overhead, though you can update it less often or for a subset of questions to save time.
- VAS focuses on sampling; combining it with new RL algorithms and reward designs could push performance even further.
Overall, the paper shows that picking the right mix of practice questions—those that produce varied results and different solution paths—can make AI reasoning models learn faster and more stably, and the open resources make these gains accessible to everyone.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each item is framed to guide actionable future research.
- Domain generalization: VAS is evaluated primarily on math/logical reasoning (plus ChartQA). Test whether VAS consistently improves stability and performance on broader multimodal tasks (e.g., document understanding, complex scientific diagrams, open-domain VQA, video-temporal reasoning).
- Dependence on proprietary annotators/verifiers: Cold-start CoTs and RL short-answer verification rely on Gemini 2.5 and GPT-4o. Quantify biases introduced by closed models, benchmark with open-source judges, and provide a fully open annotation/verification pipeline with inter-annotator agreement and error analyses.
- TDS definition and sensitivity: The diversity metric for TDS is under-specified (e.g., inverse self-BLEU, distinct-n). Compare multiple text- and embedding-based diversity measures, study sensitivity, and guard against rewarding superficial or degenerate diversity (e.g., paraphrase noise without semantic variance).
- Compute overhead and scalability: VPS updates require generating N rollouts per prompt and periodic recomputation. Measure wall-clock/throughput impacts at larger scales, and investigate efficient approximations (e.g., partial updates, bandit-style estimators, reservoir sampling, EMA over VPS) with accuracy–cost trade-offs.
- Theory-to-practice gap in GRPO: The Variance–Progress theorem assumes optimal baselines and smoothness and omits KL regularization; GRPO whitening and clipping introduce bias. Empirically validate the bound components (e.g., estimate per-prompt c_min and Γ), quantify finite-sample effects, and measure how clipping and whitening change gradient–variance correlations.
- Reward generality: Analyses focus on binary/whitened rewards. Extend to non-binary, partial-credit, or process-level rewards; redefine OVS accordingly; evaluate VAS under noisy or shaped reward regimes common in multimodal tasks.
- Adaptive control of VAS hyperparameters: λ (mixture), α/β (OVS/TDS balance), T_update, and N are fixed. Develop adaptive schedules driven by training signals (e.g., gradient norm, clip fraction, variance drift), with convergence guarantees and principled annealing strategies.
- Interaction with RL algorithm variants: Systematically benchmark VAS in combination with reward rescaling, entropy regularization, offline RL, CPL/LIMR-style sample prioritization, and VAPOEA-like approaches; identify additive effects, conflicts, and best-practice recipes.
- Ambiguity/noise prioritization risk: VPS can over-sample prompts with high variance due to label noise or ambiguous statements. Incorporate uncertainty-aware filtering and robustness checks; quantify sensitivity to annotation noise and propose safeguards.
- Coverage and forgetting: Emphasis on mid pass-rate prompts could undersample very easy or extremely hard cases. Assess catastrophic forgetting and coverage across difficulty strata; consider stratified or curriculum sampling to preserve broad competence.
- Multimodal trajectory diversity: TDS currently measures text sequence diversity. Extend to multimodal features (e.g., attention/visual grounding patterns, tool usage traces, spatial reasoning steps) and verify that trajectory diversity correlates with grounded correctness rather than text-only variance.
- Evaluation reliability: Auxiliary judging with GPT-4o for non-exact-match cases may introduce evaluation bias. Quantify judge disagreement, release deterministic evaluation scripts, and audit potential leakage or overfitting to judge preferences.
- Dataset quality and contamination: Synthetic long CoTs from Gemini may imprint stylistic biases or leak benchmark content. Conduct contamination audits, licensing reviews, and controlled experiments comparing synthetic vs. human-authored CoTs on downstream performance and robustness.
- Model/backbone generality: Results are shown for Qwen-based 3B/7B models. Test across diverse architectures and larger/smaller scales (e.g., LLaVA, InternVL, PaLI-style models) to determine whether VAS’s benefits are architecture-agnostic.
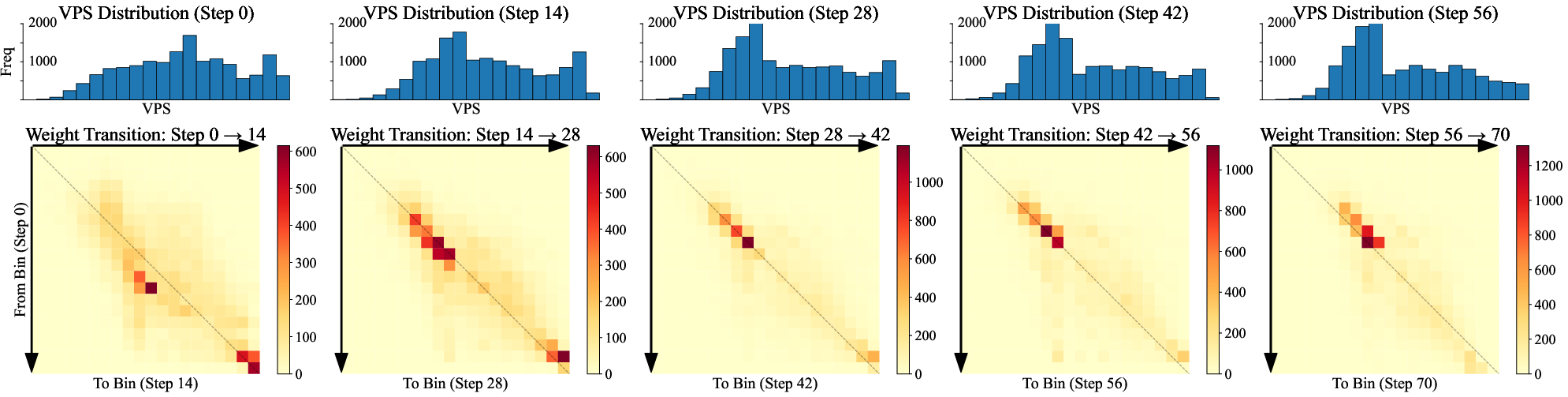
- VAS phase-out criteria: VPS distributions shift toward mid-range during training; optimal sampling may change as variance drops. Study when and how to anneal λ, or transition to uniform sampling, and define stopping criteria aligned with convergence diagnostics.
- Prompt-level effect attribution: Provide per-prompt analyses linking VPS bands to actual learning gains (loss reduction, gradient magnitude increases, pass-rate changes). Identify characteristics of “frontier” prompts that maximize improvement to inform future dataset curation.
- RL dataset composition and coverage: The 15k RL set is math+logic heavy. Expand to more vision-centric tasks (e.g., complex charts, diagrams, documents) and measure cross-domain transfer; report detailed coverage gaps and balance constraints.
- Fairness and distributional bias: VPS-weighted sampling may skew toward certain categories or difficulty types. Audit sampling distributions, measure fairness across domains/subpopulations, and enforce constraints (e.g., per-category quotas) to prevent unintended biases.
- Safety and hallucination risks: Promoting trajectory diversity may inadvertently increase hallucinations or unsafe generations. Integrate safety filters, measure hallucination and error modes, and evaluate trade-offs between diversity and reliability.
- VPS update efficiency and sample complexity: Updating all prompts every T_update with N rollouts is expensive. Derive sample complexity bounds for accurate VPS ranking, evaluate importance-weighted or bandit-style updates, and compare partial-refresh strategies at fixed budgets.
- Verifier robustness for multimodal math: Math-Verify/MathRuler/GPT-4o can fail with symbol extraction or units. Develop more robust multimodal verifiers (e.g., diagram-aware checkers), quantify failure cases, and standardize unit/format conventions.
- Process rewards integration: Current RL uses outcome-based correctness. Explore process-level reward shaping (step-wise checks), adapt OVS/TDS to process variance, and compare outcome vs. process reward regimes under VAS.
- Deployment behavior: Assess inference-time stability of VAS-trained policies (variance of answers across seeds/decoding settings), latency under longer CoTs, and calibration methods to ensure predictable outputs.
- Reproducibility details: While code, data, and checkpoints are released, provide exact training compute budgets, seeds, and data splits for cold-start and RL; include deterministic configs and run logs to enable end-to-end replication.
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now, leveraging the paper’s Variance-Aware Sampling (VAS), open datasets, codebase, and released checkpoints.
- Healthcare (document/chart understanding)
- Use case: Automate Q&A over medical charts, lab trend graphs, and tabular reports (e.g., extracting and explaining changes in vital-sign charts).
- Tools/Workflow: Apply MMR1-7B/3B for ChartQA and Doc-Table tasks; integrate with existing OCR/DocVQA pipelines; add domain-specific answer verification where feasible.
- Assumptions/Dependencies: Requires high-quality OCR; careful validation to avoid clinical misinterpretation; privacy/compliance (HIPAA/GDPR) and domain tuning.
- Education (math/science tutoring and assessment)
- Use case: Build step-by-step math and science tutoring assistants that explain reasoning and validate final answers, including visual reasoning over diagrams and charts.
- Tools/Workflow: Use the 1.6M long CoT cold-start data to fine-tune tutoring models; adopt RL with VAS for stability; deploy MMR1 checkpoints with vLLM inference.
- Assumptions/Dependencies: Reliable verifiers for correctness; guardrails for pedagogy and safety; compute and latency considerations for classroom devices (favor 3B model).
- Finance and Business Analytics (chart and document Q&A)
- Use case: Interactive analysis of financial reports, dashboards, and tables (e.g., “Why did Q3 revenue spike?” “What does this chart imply?”), with short verifiable outputs.
- Tools/Workflow: Fine-tune or directly deploy MMR1 on ChartQA/Doc-Table tasks; incorporate enterprise data connectors and secure access control.
- Assumptions/Dependencies: Domain-specific verifiers, confidentiality/compliance requirements, and calibration to reduce hallucinations.
- Scientific Communication and Research Support (figure/chart interpretation)
- Use case: Assist researchers and journalists by explaining plots, infographics, and experimental charts, with concise reasoning and validated short answers.
- Tools/Workflow: Plug MMR1 into figure/plot analysis workflows; use pass-rate filtering and VPS-guided sampling for continued RL fine-tuning on lab-specific datasets.
- Assumptions/Dependencies: Requires accurate figure parsing and metadata; domain adaptation for scientific notation and units.
- Software/ML Engineering (stable RL training for reasoning models)
- Use case: Integrate VAS into GRPO-based post-training to mitigate gradient vanishing and improve convergence for LLMs and MLLMs (including math, code, and vision-language tasks).
- Tools/Workflow: Implement VPS (OVS + TDS), mix weighted and uniform sampling (λ ≈ 0.5), periodically update VPS; adopt EasyR1/LLaMA-Factory pipelines; monitor gradient norms and clip fraction.
- Assumptions/Dependencies: Access to a task-specific verifier for pass-rate estimation; computational overhead for periodic VPS updates; multiple rollouts (N ≥ 8) to estimate variance/diversity.
- Model Evaluation and Benchmarking (academia and industry)
- Use case: Use released code, datasets, and MMR1 checkpoints as standardized baselines for multimodal mathematical and logical reasoning benchmarks.
- Tools/Workflow: Reproduce training with VAS; run ablations on λ, T_update, rollout count, and α/β weighting; apply unified prompts with boxed answers; evaluate via Math-Verify/MathRuler.
- Assumptions/Dependencies: Benchmark consistency; licensing adherence for datasets; compute resources for replication.
- Enterprise Document Automation (operations, compliance)
- Use case: Automate extraction and explanation from invoices, compliance tables, and dashboards with stepwise reasoning to produce validated short answers.
- Tools/Workflow: Deploy MMR1 for Doc-Table tasks; add domain verifiers (e.g., regex, business rules); use VPS-guided sampling for continuous fine-tuning on evolving document templates.
- Assumptions/Dependencies: Domain rule coverage; secure processing; need for rigorous evaluation before full automation.
- Training Observability and Ops (MLOps)
- Use case: Monitor training health using reward variance, actor gradient norms, and clip fraction; add a “Variance Monitor” to detect and preempt vanishing gradients.
- Tools/Workflow: Implement dashboards tracking VPS distributions, transitions, and clip fraction; trigger auto-tuning of λ and T_update.
- Assumptions/Dependencies: Proper logging and instrumentation; policy to react to variance signals (e.g., schedule VPS refresh, adjust rollout count).
- Code Generation RL (software)
- Use case: Apply VAS to code RL with test-driven rewards (pass/fail), sampling problems with mid pass rates to maximize variance and stabilize learning.
- Tools/Workflow: Define OVS via test pass rate and TDS via trajectory diversity (e.g., distinct reasoning traces); integrate with CI test suites.
- Assumptions/Dependencies: Robust test harness; binary/verifiable metrics; managing compute for multiple rollouts.
- On-Device and Resource-Constrained Deployment (daily life, education)
- Use case: Use the 3B MMR1 model for local chart interpretation and math help on tablets/edge devices in classrooms and workshops.
- Tools/Workflow: Quantize and serve with efficient runtimes (e.g., vLLM variants, tensor RT engines); constrain context windows and use short-answer formats.
- Assumptions/Dependencies: Hardware acceleration; smaller context limits; careful prompt design to maintain reliability.
Long-Term Applications
These applications are high-impact but require more research, scaling, domain-specific data, safety validation, or integration effort.
- Clinical Decision Support (healthcare)
- Use case: Multimodal clinical reasoning over imaging annotations, trends, diagrams, and structured records, producing transparent step-by-step conclusions.
- Tools/Workflow: Train domain-specific MLLMs with VAS and strong clinical verifiers; incorporate process-based feedback; deploy under rigorous QA and human oversight.
- Assumptions/Dependencies: Regulatory approval; clinical-grade datasets; validated reward models; robust safety, privacy, and bias controls.
- Robotics and Industrial Automation (robotics, manufacturing)
- Use case: Interpret manuals, schematics, and task diagrams; reason about procedures and plan actions, with RL post-training stabilized by VAS.
- Tools/Workflow: Couple multimodal reasoning with control stacks; simulate diverse rollouts for variance; use trajectory diversity metrics tailored to action plans.
- Assumptions/Dependencies: High-fidelity simulators; safe reward designs; sim-to-real transfer; large compute budgets.
- Energy and Engineering Systems (energy, civil/mechanical engineering)
- Use case: Reason over complex technical diagrams and grid charts for diagnostics and safety analysis, offering transparent “analyze–plan–execute” steps.
- Tools/Workflow: Domain-specific datasets, verifiers for engineering constraints; VAS to avoid training collapse on sparse rewards and complex reasoning.
- Assumptions/Dependencies: Specialized annotation; liability and safety requirements; extensive validation before deployment.
- Scientific Discovery and Proof Assistance (academia, R&D)
- Use case: Assist with mathematical proofs, experimental design reasoning, and figure interpretation, with process-based RL stabilized via variance-aware sampling.
- Tools/Workflow: Build rich verifiers (symbolic checkers, unit/consistency checks); mix outcome and process rewards; continue training with VPS.
- Assumptions/Dependencies: High-quality reward models; benchmarked reliability; handling long-context reasoning and symbolic math.
- Public Sector Analytics and Policy Auditing (government, NGOs)
- Use case: Transparent analysis of budgets, infographics, and public reports, explaining evidence and uncertainty to citizens.
- Tools/Workflow: Standardize evaluation with open baselines (MMR1); build variance-aware sampling into auditing workflows to surface informative cases.
- Assumptions/Dependencies: Governance, audit trails, multilingual coverage, and fairness assessments.
- Multilingual and Low-Resource Reasoning (global education and access)
- Use case: Expand VAS-guided training to multilingual multimodal datasets for inclusive math/science tutoring and document/chart Q&A.
- Tools/Workflow: Create multilingual verifiers; curate diverse CoT corpora; tune VPS to language-specific dynamics.
- Assumptions/Dependencies: Data availability, cultural and linguistic adaptation, evaluation standards across languages.
- Standardization in RL Tooling and Frameworks (software/ML infrastructure)
- Use case: Productize VAS as a module in common RL post-training frameworks (e.g., TRL, RLlib), with APIs for OVS/TDS, VPS updates, and logging.
- Tools/Workflow: Open-source libraries with pluggable verifiers; configuration-driven sampling strategies; prebuilt dashboards.
- Assumptions/Dependencies: Community adoption, consistent interfaces, and cross-model reproducibility.
- Governance and Training Auditing (AI assurance)
- Use case: Use reward variance and VPS distributions as training KPIs to detect collapse, overfitting, or reward hacking; support audits of post-training procedures.
- Tools/Workflow: Standard logging schemas; independent auditors reviewing variance trajectories and clip fractions; policy guidelines.
- Assumptions/Dependencies: Access to training logs; privacy-preserving audit mechanisms; accepted standards.
- Consumer Personal Analytics (daily life)
- Use case: Personal assistants that robustly explain household finance charts, health metrics, and study materials, with verifiable short answers and transparent reasoning.
- Tools/Workflow: Edge deployment of compact models; private data connectors; RL with VAS on user-specific tasks for personalization.
- Assumptions/Dependencies: Privacy and consent; domain-tailored verifiers; device capabilities and latency constraints.
- Advanced Reward Modeling and Variance-Aware Shaping (AI research)
- Use case: Combine TDS-driven diversity with richer process/outcome rewards to systematically raise variance and improve sample efficiency in complex tasks.
- Tools/Workflow: Design reward models that interact well with VPS; study theoretical bounds and clipping dynamics in GRPO variants.
- Assumptions/Dependencies: Continued research; careful empirical validation; generalization beyond math/logical reasoning.
Notes on Cross-Cutting Assumptions and Dependencies
- Verifiability: Many applications rely on concise, verifiable answers; building reliable domain-specific verifiers is crucial.
- Compute and Rollouts: VPS requires multiple rollouts per prompt (N ≥ 8) and periodic updates; plan for computational overhead or selective refresh strategies.
- Data Quality and Licensing: Use of the open datasets must respect licensing and suitability for domain-specific adaptation.
- Safety and Reliability: For regulated sectors (healthcare, finance, public policy), rigorous validation, calibration, and human-in-the-loop processes are necessary.
- Generalization: Current evidence is strongest in math/logical reasoning; broader domains may require new data, reward designs, and diversity metrics.
Glossary
- Ablation studies: controlled experiments that remove or modify components to assess their contribution to performance; "Comprehensive ablation studies and analyses provide further insight into the contributions of each component."
- AdamW: an optimizer that decouples weight decay from gradient-based parameter updates; "Training runs for $5$ epochs with AdamW, a cosine schedule, an initial learning rate of , and a $0.1$ warm-up ratio."
- Baseline (policy gradient): a prompt-dependent value subtracted from rewards to reduce variance while keeping the gradient estimator unbiased; "Subtracting a prompt-dependent baseline keeps the estimator unbiased:"
- Bernoulli variance: the variance of a binary random variable, equal to ; "which corresponds to the Bernoulli variance of correctness across responses."
- Chain-of-thought (CoT): explicit multi-step reasoning text accompanying answers; "the absence of open, large-scale, high-quality long chain-of-thought (CoT) data"
- Clipping: constraining update magnitudes or ratios to stabilize training and control divergence; "optionally clipped to to control KL divergence."
- Cold-start: an initial supervised fine-tuning phase used to prime a model before reinforcement learning; "our training pipeline includes two stages: a supervised cold-start stage followed by a reinforcement learning stage using GRPO"
- Cosine schedule: a learning rate schedule that follows a cosine curve over training; "Training runs for $5$ epochs with AdamW, a cosine schedule, an initial learning rate of , and a $0.1$ warm-up ratio."
- Entropy regularization: adding an entropy term to the objective to encourage exploration and prevent premature convergence; "A range of remedies has been proposed, including reward rescaling~\citep{li2024remax,huang2025lean}, entropy regularization~\citep{liu2024improving}, and improved sample selection~\citep{wang2024cpl,zhang2025focused,li2025limr},"
- Fisher information: the expected squared norm of the score function that scales gradient variance; "where is a Fisher-information term depending on the policy but not on the rewards."
- Group Relative Policy Optimization (GRPO): a reinforcement learning framework that normalizes rewards within groups of rollouts for efficient fine-tuning; "Group Relative Policy Optimization (GRPO; \citet{shao2024deepseekmath}) has emerged as a widely adopted RL framework due to its efficiency and scalability"
- Importance ratio: the likelihood ratio used to weight gradients in off-policy or normalized updates; "The gradient estimator then multiplies by the importance ratio , optionally clipped to to control KL divergence."
- KL divergence: a measure of difference between probability distributions used to constrain policy updates; "optionally clipped to to control KL divergence."
- KL regularization: penalizing divergence from a reference policy to stabilize training; "Here, we omit the KL regularization, as it only rescales constants and does not affect the variance argument."
- Law of total variance: a decomposition of variance into within- and between-conditional components; "The law of total variance gives"
- Multimodal reasoning models: models that perform reasoning over inputs from multiple modalities (e.g., text and images); "Large multimodal reasoning models have achieved rapid progress"
- Outcome Variance Score (OVS): a score measuring correctness variability across rollouts via the pass rate; "Inspired by \citet{foster2025learning}, we directly calculate the Outcome Variance Score (OVS) as:"
- Pass rate: the proportion of generated responses that match the ground-truth answer; "The pass rate for is then defined as:"
- Policy gradient: the gradient of expected reward with respect to policy parameters used to update the model; "we theoretically establish that reward variance lower-bounds the expected policy gradient magnitude"
- REINFORCE: a Monte Carlo policy-gradient algorithm using the score-function estimator; "We first establish a VarianceâProgress Theorem for the vanilla REINFORCE algorithm~\citep{williams1992reinforce}"
- Reward model: a learned function that assigns scalar rewards to prompt–response pairs; "A learned reward model assigns a scalar reward."
- Reward variance: variability of rewards across sampled responses that influences gradient magnitude and stability; "the reward variance is the only prompt-dependent factor controlling the dispersion of stochastic gradients."
- Rollout: a sampled response or trajectory generated by the policy for a given prompt; "Sample rollouts from "
- Score-function identity: the identity expressing gradients as expectations of rewards times the score of the policy; "Score-function identity."
- Self-BLEU: a diversity metric computed by measuring BLEU of a sample against others from the same set; "inverse self-BLEU or distinct-n"
- Trajectory Diversity Score (TDS): a score quantifying variability among reasoning trajectories; "We further define the Trajectory Diversity Score (TDS) to characterize variability in reasoning processes."
- Trust region: the constrained region in parameter space within which policy updates are kept to ensure stable learning; "the model performs substantial yet constrained updates, exploits the trust region more fully, and extracts stronger signals from each batch."
- Variance-Aware Sampling (VAS): a data selection strategy that promotes reward variance to stabilize optimization; "we introduce Variance-Aware Sampling (VAS), a dynamic data selection strategy designed to mitigate gradient vanishing in GRPO-based training for multimodal reasoning models."
- Variance Promotion Score (VPS): a weighted combination of OVS and TDS used to guide sampling; "VAS employs the Variance Promotion Score (VPS), which evaluates each prompt's potential to induce reward variance."
- Verifier: a task-specific function that checks whether a response matches the ground-truth answer; "A task-specific verifier evaluates each response, returning $1$ if matches and $0$ otherwise."
- vLLM: an efficient inference engine for LLMs; "Inference is performed using vLLM~\citep{kwon2023efficient} for efficient generation."
- Whitening (of rewards): normalizing centered rewards by the standard deviation to stabilize gradient estimation; "the sample standard deviation whitens centered rewards:"
Collections
Sign up for free to add this paper to one or more collections.

