Documentation Retrieval Improves Planning Language Generation
Abstract: Certain strong LLMs have shown promise for zero-shot formal planning by generating planning languages like PDDL. Yet, performance of most open-source models under 50B parameters has been reported to be close to zero due to the low-resource nature of these languages. We significantly improve their performance via a series of lightweight pipelines that integrates documentation retrieval with modular code generation and error refinement. With models like Llama-4-Maverick, our best pipeline improves plan correctness from 0\% to over 80\% on the common BlocksWorld domain. However, while syntactic errors are substantially reduced, semantic errors persist in more challenging domains, revealing fundamental limitations in current models' reasoning capabilities.\footnote{Our code and data can be found at https://github.com/Nangxxxxx/PDDL-RAG








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary: How Reading the “Rulebook” Helps AI Write Better Plans
1) What is this paper about?
This paper explores how to help AI models write correct step-by-step plans by having them read the right “rulebook” first. The plans are written in a special planning language called PDDL, which is like a coding language for describing actions, rules, and goals in a world (for example, stacking blocks). The authors show that giving AI the most relevant parts of the PDDL documentation (the rulebook) and guiding how it writes and fixes code can massively improve results—especially for smaller, open-source models.
2) What questions did the researchers ask?
In simple terms, they asked:
- Can AIs that usually struggle with planning in PDDL do much better if we give them the right documentation at the right time?
- Is it better to give all the documentation at once, or just the specific parts needed for each step?
- When the AI makes mistakes, can we use error messages to retrieve the best part of the documentation to help it fix the code?
- Does documentation mostly help with “grammar” mistakes (syntax) or also with deeper meaning mistakes (semantics)?
- Do examples in the docs help more than plain descriptions?
3) How did they do it?
They tested AI models in text-based planning worlds like Blocks World (stacking blocks), Logistics (moving packages), and Barman (mixing drinks). The goal: given a description of the world and the goal, have the AI write two PDDL files:
- Domain file: defines the actions and rules (like “pickup,” “stack,” and what must be true before and after each action).
- Problem file: defines the starting state and the goal.
They tried several approaches:
- Base: Ask the AI to write PDDL from scratch with just the task description.
- Once w/ Whole Doc: Give the AI the entire PDDL documentation and then have it write everything.
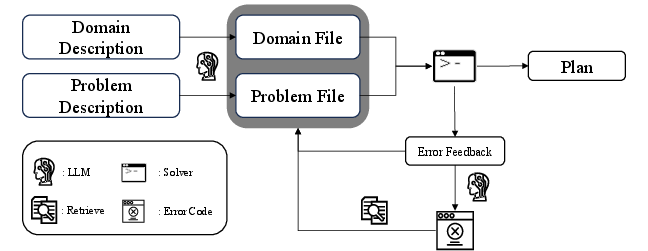
- Modular w/ Specific Doc: Break the job into smaller steps (like “write the list of actions,” then “write the types,” etc.) and give only the relevant documentation for each step.
- Refinement (fixing mistakes): Run the AI’s code through a planner/validator (a program that checks if the code is valid and can produce a correct plan). If there’s an error, use that error to retrieve the most helpful doc snippet and ask the AI to fix its code.
To find the right doc snippet, they used a simple search method called BM25 (think: keyword-based library search). In some tests, they also tried an embedding-based retriever (a smarter, meaning-based search).
Here’s the basic cycle they used:
- Step 1: AI writes draft PDDL.
- Step 2: A solver checks the code and reports errors.
- Step 3: Retrieve the most helpful documentation for that specific error.
- Step 4: AI fixes the code using the error message and the doc.
- Step 5: Repeat fixing a few times if needed.
Key terms explained:
- Syntax errors: Like grammar mistakes in code (wrong keyword, missing parentheses).
- Semantic errors: The code runs, but the rules don’t match the world correctly (so the plan doesn’t actually achieve the goal).
- Retrieval: Finding the best parts of the documentation to help with the current task.
4) What did they find, and why is it important?
Main takeaways:
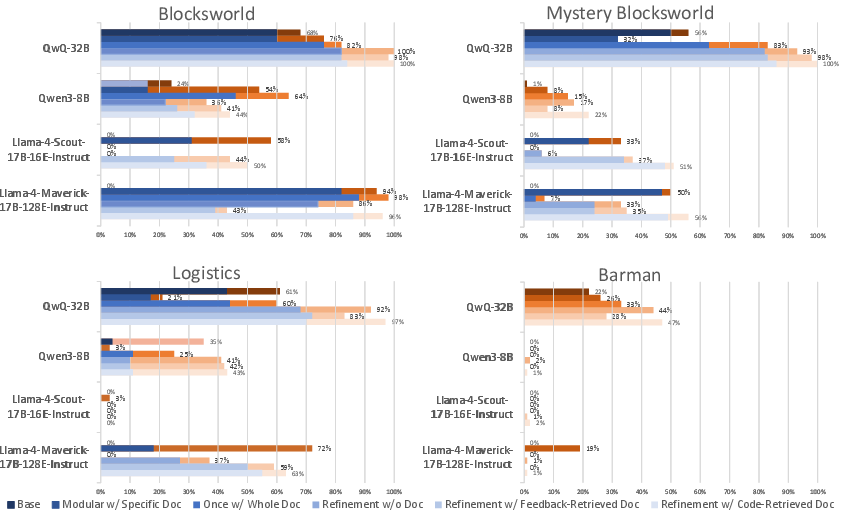
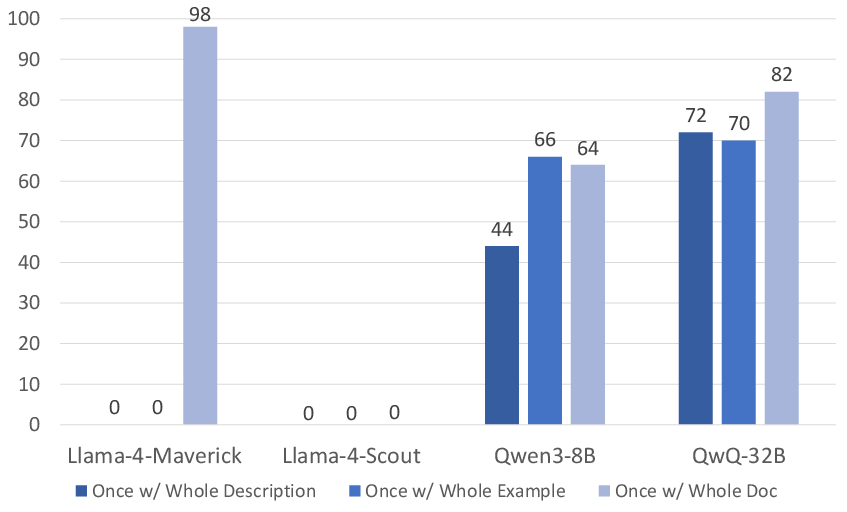
- Documentation boosts performance a lot, especially on easier tasks.
- On Blocks World, a model that went from 0% correct plans jumped to over 80% when the pipeline used documentation effectively. Syntax accuracy also shot above 90% for that model.
- Giving specific, targeted documentation helps fix syntax (grammar) errors.
- Modular generation with the right doc snippet for each step works well.
- Using the error message to find a matching doc snippet helps during fixing.
- Examples in the documentation are extra helpful.
- Docs with examples beat plain descriptions for reducing syntax mistakes.
- Documentation helps most at the beginning.
- Docs are very useful during the first code-writing phase, less so during later rounds of fixing.
- Stronger models can handle the whole documentation at once.
- More capable models do fine when you give them the entire doc. Less capable models get overwhelmed and do better with modular, bite-sized doc pieces.
- Semantic errors remain hard.
- Docs can fix grammar, but they don’t fully solve deeper reasoning problems. This becomes clear in harder worlds (like Logistics or Barman), where the AI still struggles to represent the world’s rules correctly.
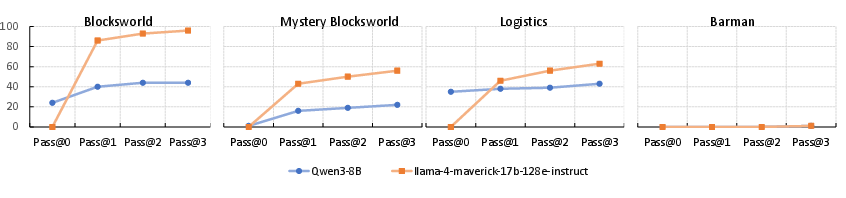
- A few rounds of fixing help, but gains drop off.
- The first round of refinement gives the biggest improvement; later rounds help less.
- Retrieval method matters.
- For some settings, embedding-based retrieval found better doc snippets than BM25; in others, BM25 was more reliable. There’s no one-size-fits-all winner.
Why it matters:
- It shows a practical way to make smaller, open-source AIs useful for planning by pairing them with the right documentation and a smart generation-and-fix pipeline.
- It separates surface-level correctness (syntax) from real understanding (semantics), pointing to where future improvements are needed.
5) What does this mean for the future?
- With smart use of documentation and careful step-by-step generation, smaller and cheaper AI models can write useful planning code—great news for teams that can’t afford huge models.
- However, to truly solve harder problems, AIs need better reasoning, not just better grammar. Future work should focus on improving world modeling and logic, maybe with better training data, better tools, or hybrid systems that combine AI with classical planners.
- Good, well-organized docs with examples are key. Building better documentation and better ways to retrieve just the right part can make AIs much more reliable.
- The approach here could help with other niche or “low-resource” coding languages, not just PDDL, wherever clear rulebooks exist.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Robustness to naturalistic inputs: The pipeline is evaluated on heavily templated domain/problem descriptions; how does performance change with noisy, under-specified, or real-world narrative descriptions (e.g., ambiguous goals, incomplete constraints)?
- Documentation coverage and quality: Only Planning Wiki is used; effects of outdated, incomplete, or inconsistent documentation are not quantified. How do doc source choice, versioning, and quality control affect outcomes?
- Doc segmentation strategy: The modular approach partitions docs by PDDL components, but the partitioning method (chunk size, boundaries, overlap) is not examined. What segmentation policies maximize retrieval precision without overwhelming weaker models?
- Error-to-doc retrieval mapping: BM25 or simple embeddings are used ad hoc. Can code-aware or structure-informed retrieval (grammar-aware, AST/CFG-guided, symbolic index of PDDL constructs) more reliably surface the right snippet for a given error?
- Error localization reliability: The method relies on an LLM to “localize” error-causing code prior to retrieval, but localization accuracy and its impact on refinement success are not measured. How do static analyzers or rule-based parsers compare for pinpointing faulty lines?
- Semantic error reduction strategies: Documentation substantially reduces syntax errors but not semantics. What additional mechanisms (domain invariants, state-space reachability checks, goal-condition completeness tests, counterexample-guided repair) best address semantic failures such as loops, unreachable goals, or insufficient action sets?
- Evaluation design and metric fidelity: “Semantic accuracy” is defined via planning and validation with VAL, reportedly “against the gold DF and PF,” which may mismatch a plan derived from a different generated DF/PF. How should correctness be measured when the generated domain/problem differ from gold (e.g., goal satisfaction in the intended task independent of DF/PF idiosyncrasies), and how do metrics like plan optimality, length, and solver runtime change conclusions?
- Planner and validator dependence: Only dual-bfws-ffparser and VAL are used. Do improvements transfer across diverse planners (e.g., FastDownward, FF, LPG) and validators, and are some tools more sensitive to certain PDDL features (typing, ADL, conditional effects)?
- Domain coverage and PDDL feature breadth: Experiments cover Blocks World, Logistics, Barman (+ Mystery Blocks), but advanced PDDL features (quantifiers, conditional effects, negative preconditions, durative actions, numeric fluents) are not tested. How does performance scale with feature complexity?
- Generalization beyond PDDL: The SMT/Z3 exploration is limited and negative. What pipeline adaptations (error taxonomies, solver feedback normalization, language-specific documentation) are needed for other low-resource formal languages (SMT-LIB, Alloy, TLA+, STRIPS variants)?
- Model scale and prompting ablations: Only 8B–32B open-source models, zero-shot prompting are considered. How do few-shot prompts, tool-usage, self-consistency/tree-of-thought, or lightweight fine-tuning alter doc utility and semantic performance, and what are the scaling laws beyond 50B?
- Adaptive refinement policies: Refinement is capped at three iterations, with gains concentrated in the first round. Can dynamic stopping criteria, error-class–aware policies, or curriculum-based refinement improve efficiency and semantics?
- Example vs description design: Examples outperform descriptions, but “example” characteristics (granularity, diversity, coverage of edge cases) are not analyzed. Can synthetic example generation tailored to the current domain/problem systematically close semantic gaps?
- Hybrid retrieval and reranking: Embeddings help in feedback-retrieved but hurt in code-retrieved settings. What hybrid schemes (BM25 first-pass + embedding reranker, or supervised LTR) best balance precision and robustness across error types and domains?
- Cost, latency, and scalability: The computational overhead of retrieval, multiple solver calls, and iterative generation is not reported. How do time/cost trade-offs evolve with domain complexity, and what budget-aware pipeline variants preserve most gains?
- Reproducibility and variance: Run-to-run variance, seed control, and sensitivity to sampling parameters are not discussed. How stable are results across restarts, and does documentation reduce variance?
- Fine-grained error taxonomy: Errors are grouped as syntax vs semantic. A more granular taxonomy (requirements flags, predicate arity/type mismatches, object set inconsistencies, precondition/effect mis-specifications, initial-state errors) could guide targeted retrieval and repair. Can such a taxonomy improve triage and fix rates?
- Mystery Blocks robustness: Keyword perturbations combat memorization, but impacts on retrieval (term mismatch between feedback and docs) are not analyzed. What query normalization or synonym mapping (e.g., ontology alignment) mitigates obfuscation?
- Long-term constraint retention: Documentation influences initial generation more than later refinement. How can constraints learned from docs be explicitly tracked and enforced across iterations (e.g., constraint buffers, unit tests, invariants)?
- Curriculum modularization: Modular generation helps weaker models, but the optimal step ordering and granularity are not studied. What curricula (requirements → types → predicates → actions → PF init/goal) maximize semantic correctness without overfitting syntax?
- Solver feedback normalization: Using raw solver messages as queries is brittle. Can feedback be normalized into structured error schemas or enriched with failure traces to improve retrieval and repair?
- Human-in-the-loop augmentation: The potential of minimal human hints (e.g., invariant annotations, goal decompositions) in one or two steps to close semantic gaps is unexplored. What is the smallest effective human intervention?
- Documentation trust and safety: The pipeline assumes doc correctness. How can systems detect and mitigate misleading/conflicting documentation (e.g., cross-source verification, confidence scoring), especially when docs are community-maintained?
- Cross-model doc utilization analysis: Models “vary in their ability to leverage documentation,” but no mechanism-level analysis exists. Can attention/tracing or token-level attribution quantify doc consumption and predict when docs help or hurt?
- Transfer to real tasks and deployments: The paper’s scope is limited to simulated IPC-style tasks. What happens in integrated robotic or workflow planning settings where environment states are partially observed, stochastic, or evolving, and where plans must be executed?
Practical Applications
Practical Applications Overview
Below are actionable, real-world applications that follow directly from the paper’s findings and methods. They are grouped into Immediate Applications (deployable with today’s tools and the described pipelines) and Long-Term Applications (requiring further research, scaling, or model capability advances).
Immediate Applications
- Documentation-augmented formal planning assistants
- Sector: software, robotics, logistics
- Use case: Natural-language task descriptions are transformed into PDDL domain/problem files via modular generation plus documentation retrieval, then solved/validated with planners (e.g., dual-bfws-ffparser) and VAL.
- Tools/products/workflows: “PDDL Copilot” IDE plugin; CI step that runs solver/VAL and performs up to 1–2 refinement rounds; a service wrapper exposing the full pipeline: NL spec → retrieval → modular PDDL generation → solver → validation → error-localization → doc-retrieval → correction.
- Assumptions/dependencies: Well-structured, accurate documentation (examples strongly preferred over descriptions); high-quality domain/problem descriptions; BM25 or embedding retriever tuned to the phase (BM25 for code-retrieved refinement); access to planners/validators; tasks not too complex semantically.
- IDE extensions for low‑resource DSLs (beyond PDDL)
- Sector: software engineering
- Use case: Code editors that retrieve relevant documentation snippets and examples when users write DSL code, reducing syntax errors and lint warnings.
- Tools/products/workflows: “DocPrompting for DSLs” extension; on-save syntactic validation; lightweight error localization that retrieves targeted doc snippets; 1–2 iteration fix suggestions.
- Assumptions/dependencies: Documentation coverage and currency; supported solver/validator per DSL; smaller LLMs benefit most from modular, stepwise templates.
- Documentation curation and example-first authoring
- Sector: documentation engineering, education
- Use case: Rewrite/augment DSL docs to maximize example density (since examples outperform descriptions), partition docs by code components (types, predicates, actions) for targeted retrieval.
- Tools/products/workflows: Documentation pipelines that auto-segment content; “Example Index” for predicates/actions; retrieval-ready doc stores (BM25 and embeddings).
- Assumptions/dependencies: Editorial capacity; doc hosting with search/index; governance over doc updates.
- Training and onboarding for planning languages
- Sector: education, academia, industry training
- Use case: Interactive tutors that demonstrate modular PDDL generation; students solve Blocks World logistics-like scenarios with automatic syntax checks and feedback-driven doc retrieval.
- Tools/products/workflows: Courseware that integrates the paper’s prompts/pipeline; microprojects emphasizing initial generation with specific docs and limited refinement iterations.
- Assumptions/dependencies: Availability of benchmark tasks; classroom compute; alignment of curricula with PDDL/IPC basics.
- Lab-scale robotics and simulated logistics formalization
- Sector: robotics, logistics
- Use case: In controlled environments, convert textual task specs into executable plans (e.g., pick-and-place procedures, simple routing) by generating validated PDDL.
- Tools/products/workflows: Simulation-to-PDDL generator; lab orchestration system that runs the pipeline and deploys plans to a motion/planning stack; logging/VAL integration for auditability.
- Assumptions/dependencies: Limited domain complexity; stable environment models; integration with downstream planners; tolerance for semantic errors (human-in-the-loop approval).
- CI/CD gates for syntactic correctness in planning DSLs
- Sector: software, MLOps
- Use case: Automatically ensure DSL artifacts (PDDL domains/problems) are syntactically valid before merging/release, using doc-augmented generation and refinement.
- Tools/products/workflows: CI job calling the pipeline on changed DSL files; report builder highlighting syntax fixes and retrieved doc rationale; “first-iteration fix” policy.
- Assumptions/dependencies: Access to planners/validators in CI; stable retrieval indexes; small iteration budgets (most gains occur in the first refinement round).
Long-Term Applications
- Robust semantic planning from natural language in complex domains
- Sector: robotics, supply chain, healthcare operations, energy grid planning
- Use case: Translate messy, real-world task descriptions into semantically correct formal models/plans (temporal/numeric PDDL, TAMP, hybrid constraints) that perform under uncertainty.
- Tools/products/workflows: Next-gen LLM formalizers with improved reasoning/world modeling; richer doc stores (temporal/numeric examples, domain ontologies); multi-phase refinement with human-in-the-loop validation.
- Assumptions/dependencies: Advances in LLM reasoning; better environment modeling; standardized domain descriptions; richer validation suites; safety approvals for deployment.
- Generalized “RAG-for-DSLs” platform with phase-aware retrieval
- Sector: software
- Use case: A service that supports many low-resource languages (PDDL, SMT, robotics DSLs), automatically choosing BM25 vs embeddings depending on phase (initial generation vs feedback-driven vs code-retrieved refinement).
- Tools/products/workflows: Retrieval orchestrator that switches strategies; code localization models; policy for examples-first retrieval; adapter prompts based on model capability (modular for weaker models, whole-doc for stronger).
- Assumptions/dependencies: High-quality multi-DSL documentation; persistent benchmarks; routing policy backed by empirical performance.
- Auditable, interpretable planning systems for regulated sectors
- Sector: policy/governance, healthcare, finance, public-sector IT
- Use case: Require interpretable formal planning artifacts (PDDL/DSL) for automated decision systems, with documentation-backed traceability for errors and corrections.
- Tools/products/workflows: Compliance toolkits that store solver feedback, retrieved docs, and change rationales; certification processes anchored in plan validation (VAL) and doc references.
- Assumptions/dependencies: Regulatory acceptance of formal planning artifacts; audit record standards; sustained documentation governance.
- Automated documentation synthesis and maintenance for DSLs
- Sector: documentation engineering, software
- Use case: Generate and continuously update example-rich docs (from code corpora and validated plans) to improve downstream LLM formalization performance.
- Tools/products/workflows: Doc synthesis pipelines that mine successful plans to produce examples; semantic clustering of examples; doc A/B testing for pipeline performance uplift.
- Assumptions/dependencies: Access to plan repositories; legal rights to synthesize docs; tooling to measure doc impact on accuracy.
- NL-to-plan agents with interactive correction loops
- Sector: consumer assistants, enterprise productivity
- Use case: Assistants that decompose user goals, produce candidate formal plans, run solvers, then ask targeted questions to resolve semantic gaps, leveraging retrieved docs and examples.
- Tools/products/workflows: Conversational refinement (error localization explanations, doc snippets shown to users); adaptive iteration budgets; mixed-initiative edit proposals.
- Assumptions/dependencies: UX for human-in-the-loop; privacy-safe logging; model advances for semantic correction beyond syntax.
- Standardization of domain/problem description practices
- Sector: policy, industry consortia, academia
- Use case: Establish best-practice templates for domain/problem descriptions that are retrieval-friendly (segmentable, example-rich), improving consistency and model performance at scale.
- Tools/products/workflows: Style guides; schema for domain/problem docs; validators that flag underspecified or noisy descriptions.
- Assumptions/dependencies: Community adoption; cross-organization governance; demonstrated performance gains to motivate uptake.
- Cross-language formalization bridges (PDDL ↔ SMT/TAMP/other DSLs)
- Sector: software, robotics, OR
- Use case: Translate between planning languages with documentation-aware prompts and formal validators, enabling heterogeneous planning stacks.
- Tools/products/workflows: Multi-DSL converters; cross-validator orchestration; retrieval indexes spanning multiple language specs and examples.
- Assumptions/dependencies: Mature documentation for target DSLs; tools to validate semantics across languages; advances beyond current SMT results (which underperform in complex tasks per the paper).
- Domain-specific planning knowledge bases with example-centric retrieval
- Sector: healthcare pathways, manufacturing process planning, energy dispatch
- Use case: Curated KBs of domain actions/predicates and canonical examples, optimized for LLM retrieval during formalization and refinement.
- Tools/products/workflows: Domain ontologies linked to PDDL fragments; example libraries; retrieval services co-designed with planners.
- Assumptions/dependencies: Domain SME involvement; mapping from domain semantics to formal language constructs; sustained curation.
Notes on Feasibility and Design Choices Drawn from the Paper
- Documentation is most effective for syntax; semantic correctness remains a bottleneck with smaller LLMs.
- Examples outperform descriptions; prioritize example-rich documentation and retrieval.
- Modular generation helps weaker models; whole-doc prompting suits more proficient models.
- Code-retrieved doc (with BM25) is typically more effective than feedback-retrieved doc; embeddings can help in some feedback-retrieved settings—make retrieval strategy phase-aware.
- Most gains occur in the first refinement iteration; cap iterations to 1–2 in production pipelines.
- Performance depends on clean domain/problem descriptions and reliable solver/validator integration; noisy or underspecified inputs degrade outcomes.
Glossary
- ADL: An expressive PDDL requirement extending STRIPS with advanced constructs such as quantifiers and conditional effects. "(:requirements : strips :adl : typing)"
- BM25: A probabilistic information retrieval ranking function used to retrieve the most relevant documentation passages. "Table 1: Comparison of BM25 vs Embedding-base retriever results across domains, methods, and models."
- Barman: An IPC benchmark planning domain involving cocktail mixing and bar tools. "Barman from the International Planning Com- petition (IPC, 1998)"
- Blocks World: A classic AI planning domain where blocks are stacked and unstacked on a table. "over 80% on the common Blocks World domain."
- dual-bfws-ffparser planner: A heuristic search-based planner used to solve and generate plans from PDDL domain/problem files. "We use the dual-bfws-ffparser planner Muise (2016) to solve for the plan"
- Embedding-based retriever: A retrieval method that uses vector embeddings to fetch relevant documentation for code/planning refinement. "The embedding-based retriever exhibits diver- gent effects across refinement settings."
- International Planning Competition (IPC): A long-running benchmark competition and suite for evaluating automated planners. "International Planning Com- petition (IPC, 1998)"
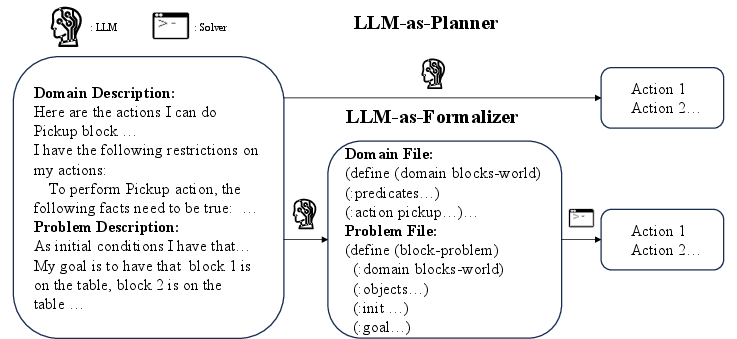
- LLM-as-Formalizer: A paradigm where an LLM generates formal planning representations (e.g., PDDL) that a solver uses to compute plans. "In contrast, the LLM-as-Formalizer (Tang et al., 2024; Guo et al., 2024; Zhang et al., 2024) approach"
- LLM-as-Planner: A paradigm where an LLM directly outputs action plans from environment descriptions without an external formal solver. "Figure 1: A simplified illustration of LLM-as-Planner and LLM-as-Formalizer on the Blocks World domain."
- Logistics: An IPC transportation planning domain involving routing packages via trucks and planes. "Logis- tics"
- Mystery Blocks World: A Blocks World variant with perturbed vocabulary to reduce memorization. "Mystery Blocks World (Valmeekam et al., 2023)"
- PDDL (Planning Domain Definition Language): A formal language for specifying planning domains and problems for automated planners. "Planning Domain Defi- nition Language (PDDL) as one of the predominant formal languages for LLM planning"
- Planning Wiki: A community-maintained knowledge base used here as the documentation source for PDDL. "We crawl, process and use the Planning Wiki2 as the source of documentation of the PDDL language."
- Satisfiability Modulo Theories (SMT): A class of decision problems and solvers that determine satisfiability with respect to background theories (e.g., arithmetic). "Satisfiability Modulo Theories (SMT) solvers—specifically Z3, a general-purpose solver for constraint satisfaction planning problems."
- Semantic accuracy: An evaluation metric indicating whether a correct, goal-achieving plan is produced. "Semantic accuracy is the percentage of problems where a plan is not only found but also correct."
- STRIPS: A foundational PDDL requirement/fragment characterized by simple preconditions and add/delete effects. "(:requirements : strips :adl : typing)"
- Syntactic accuracy: An evaluation metric indicating whether generated PDDL files contain no syntax errors. "Syntactic accuracy is the percentage of problems where no syntax er- ror are returned by the planning solver."
- VAL4: A plan validation tool that checks the correctness of plans against PDDL domain and problem specifications. "the VAL4 (Howey et al., 2004) to validate the plan against the gold DF and PF."
- Z3: A widely used SMT solver capable of checking satisfiability for constraints in planning and other domains. "specifically Z3, a general-purpose solver for constraint satisfaction planning problems."
- zero-shot: Performing a task without task-specific fine-tuning or in-context examples at inference time. "we begin with the most basic setting, referred to as Base, where a LLM zero-shot generates PDDL code."
Collections
Sign up for free to add this paper to one or more collections.

