Published 22 Sep 2025 in cs.SD and cs.LG | (2509.17609v1)
Abstract: Audio super-resolution (SR), i.e., upsampling the low-resolution (LR) waveform to the high-resolution (HR) version, has recently been explored with diffusion and bridge models, while previous methods often suffer from sub-optimal upsampling quality due to their uninformative generation prior. Towards high-quality audio super-resolution, we present a new system with latent bridge models (LBMs), where we compress the audio waveform into a continuous latent space and design an LBM to enable a latent-to-latent generation process that naturally matches the LR-toHR upsampling process, thereby fully exploiting the instructive prior information contained in the LR waveform. To further enhance the training results despite the limited availability of HR samples, we introduce frequency-aware LBMs, where the prior and target frequency are taken as model input, enabling LBMs to explicitly learn an any-to-any upsampling process at the training stage. Furthermore, we design cascaded LBMs and present two prior augmentation strategies, where we make the first attempt to unlock the audio upsampling beyond 48 kHz and empower a seamless cascaded SR process, providing higher flexibility for audio post-production. Comprehensive experimental results evaluated on the VCTK, ESC-50, Song-Describer benchmark datasets and two internal testsets demonstrate that we achieve state-of-the-art objective and perceptual quality for any-to-48kHz SR across speech, audio, and music signals, as well as setting the first record for any-to-192kHz audio SR. Demo at https://AudioLBM.github.io/.
The paper introduces AudioLBM, a latent-to-latent bridge model that utilizes instructive priors from low-resolution signals for effective audio super-resolution.
It employs frequency-aware conditioning and a cascaded architecture to enhance performance, enabling robust upsampling across various sampling rates.
Experiments demonstrate state-of-the-art results with reduced LSD, improved ViSQOL scores, and faster inference, scaling up to ultra-high resolutions like 192 kHz.
Audio Super-Resolution with Latent Bridge Models: A Technical Analysis
Introduction and Motivation
The paper introduces AudioLBM, a latent bridge model (LBM) framework for audio super-resolution (SR), targeting the upsampling of low-resolution (LR) audio waveforms to high-resolution (HR) signals. The approach is motivated by the limitations of prior generative models—diffusion and bridge-based methods—that often rely on uninformative priors (e.g., Gaussian noise) and operate in spectral or latent spaces that do not fully exploit the informative content of LR waveforms. AudioLBM addresses these issues by compressing audio into a continuous latent space and modeling the LR-to-HR mapping as a latent-to-latent generative process, thereby leveraging the instructive prior information inherent in the LR signal.
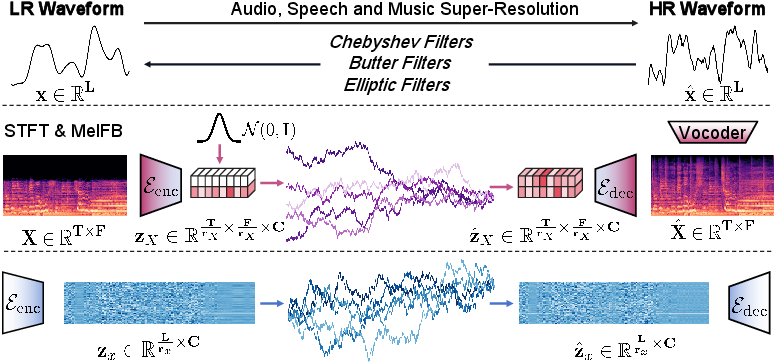
Figure 1: The top part shows how the low-resolution waveform is simulated during training via low-pass filtering, the middle part depicts the baseline method AudioSR synthesizing high-resolution content from Gaussian noise, and the bottom part presents the overview of AudioLBM, which learns a latent-to-latent generation process between LR and HR waveform latents.
Latent Bridge Model Formulation
Compression and Latent Representation
AudioLBM employs a convolutional VAE to encode both LR and HR waveforms into continuous latent representations. The encoder E maps xLR and xHR to zLR and zHR, respectively, with a fixed compression ratio rx. This design ensures that the LR latent contains informative cues for reconstructing the HR latent, avoiding the area removal and spectral misalignment issues observed in prior works.
Bridge Process and Training Objective
The generative process is formulated as a Schrödinger Bridge (SB) between the boundary distributions zT=zLR and z0=zHR. The forward SDE is parameterized to interpolate between these boundaries, and the model is trained to predict the noise component ϵθ using a denoising objective:
This latent-to-latent bridge process is inherently matched to the LR-to-HR SR task, in contrast to diffusion models that sample from uninformative noise.
Frequency-Aware Conditioning
To address data scarcity and improve generalization, AudioLBM introduces frequency-aware conditioning. Both the prior and target frequencies are embedded and prepended to the latent sequence, enabling the model to learn an any-to-any upsampling process. This explicit conditioning allows the model to adapt to arbitrary input and output sampling rates, improving robustness to real-world degradations and device artifacts.
Cascaded LBMs and Prior Augmentation
Cascaded Upsampling Beyond 48 kHz
AudioLBM is extended to ultra-high-resolution SR (96 kHz, 192 kHz) via a cascaded architecture. Each stage consists of a VAE and an LBM trained for a specific sampling rate. The output of one stage serves as the input to the next, progressively reconstructing higher-frequency content.
Prior Augmentation Strategies
To mitigate cascading errors, two augmentation strategies are introduced:
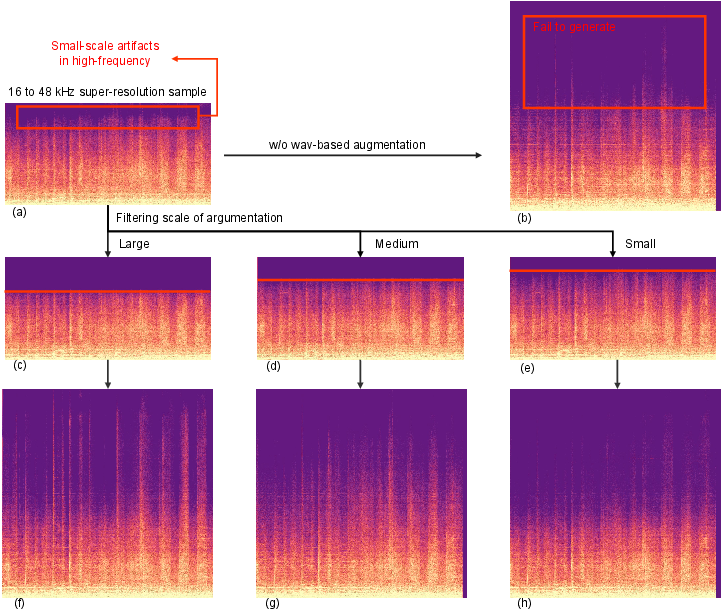
Waveform-based Filtering: Low-pass filtering is applied to the output of each stage to suppress high-frequency artifacts before feeding into the next LBM.
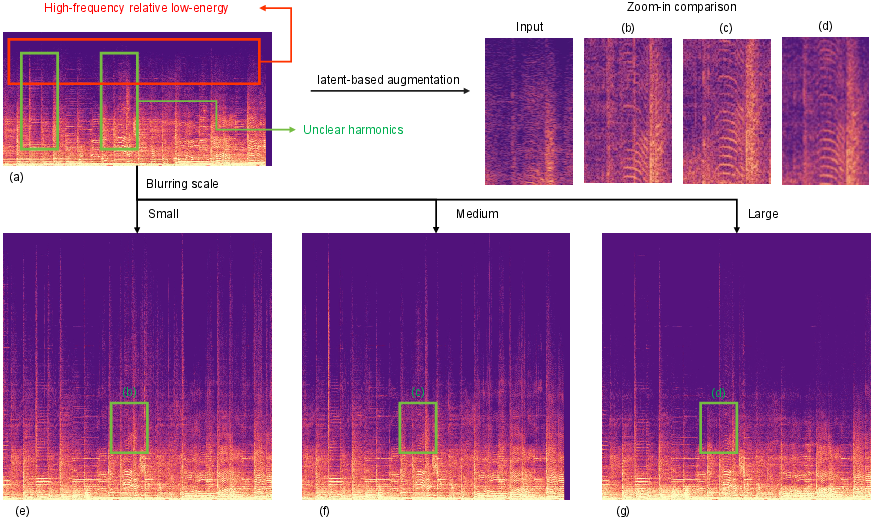
Latent-based Blurring: Gaussian blurring is applied to the latent representation, smoothing local fluctuations and improving alignment with the ground-truth HR latent.
Figure 2: Visual comparison of waveform-based filtering strategies, showing the effect of different cutoff frequencies and their impact on super-resolution outputs.
Figure 3: Visual comparison of latent-based blurring strategies, illustrating the effect of different blur ratios on harmonic structure and high-frequency energy.
These deterministic augmentations outperform random noise-based strategies, providing stable and reliable guidance for cascaded SR.
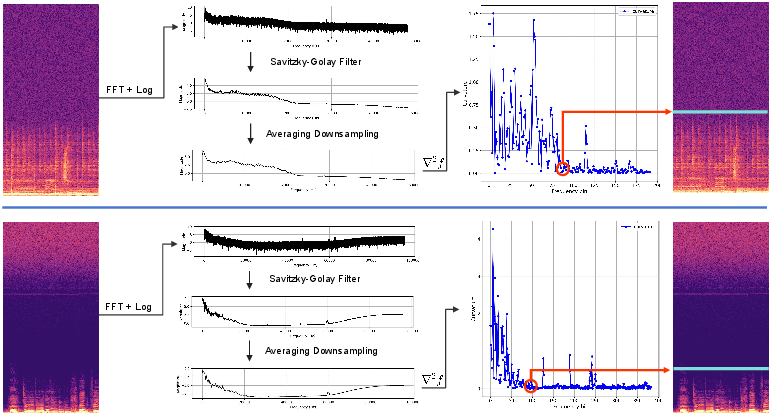
Data Preprocessing and Effective Bandwidth Estimation
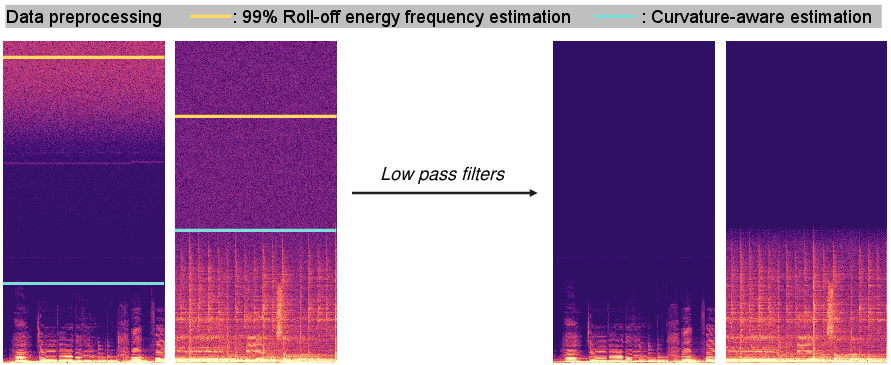
The paper proposes a curvature-aware spectral analysis pipeline to estimate the effective bandwidth feff of input audio, enabling adaptive low-pass filtering during both training and inference. This approach is robust to high-frequency noise and device artifacts, ensuring that SR models operate on the informative signal subspace.
Figure 4: Data preprocessing pipeline estimating the effective cut-off frequency and removing spectral noise for improved SR training samples.
Figure 5: Curvature-aware estimation pipeline for detecting the effective cut-off frequency feff via second-order curvature over the log-magnitude spectrum.
Experimental Results and Ablations
Objective and Perceptual Metrics
AudioLBM achieves state-of-the-art results on VCTK, ESC-50, Song-Describer, and internal datasets. Notable improvements include:
Average 21.5% reduction in LSD and 3.05% increase in ViSQOL over prior systems for any-to-48 kHz SR.
Superior SSIM and SigMOS scores for speech upsampling, outperforming GAN-based and diffusion-based baselines.
Ablation Studies
Ablations confirm the effectiveness of frequency-aware conditioning, waveform and latent-based augmentation, and the cascaded architecture. Moderate filtering and blurring ratios yield optimal trade-offs between artifact removal and content preservation.
Qualitative Analysis
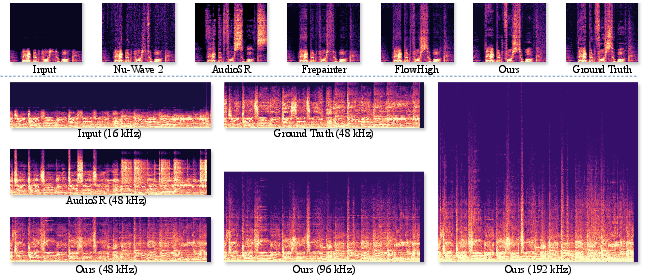
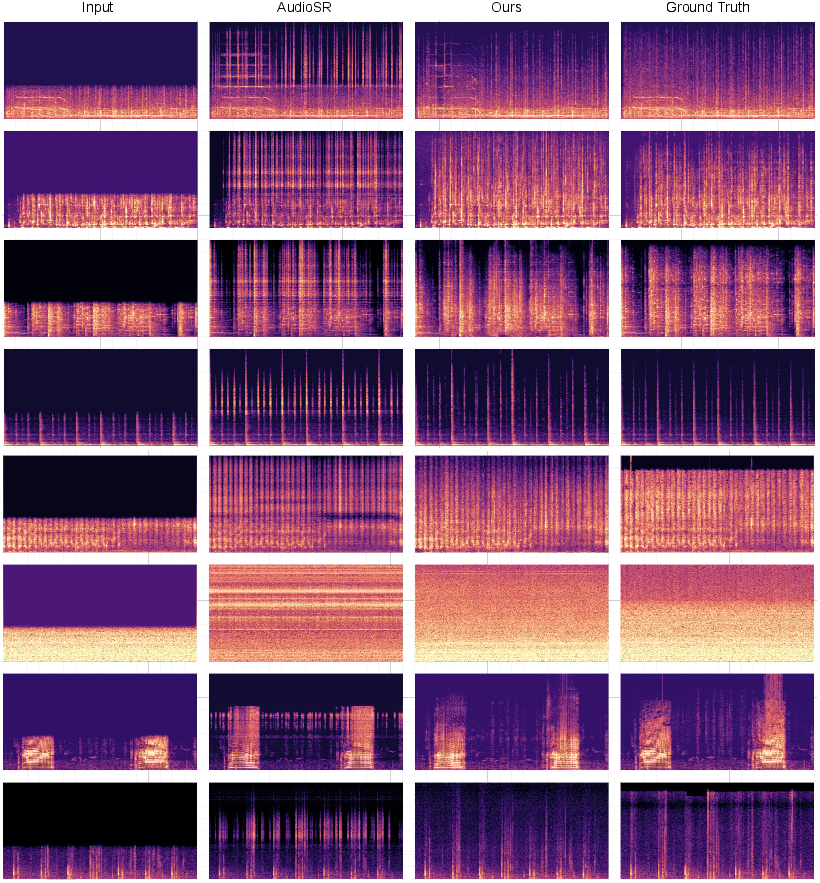
Figure 6: STFT spectrograms for case studies on speech and music SR, demonstrating detailed full-band reconstruction and improved harmonic structure.
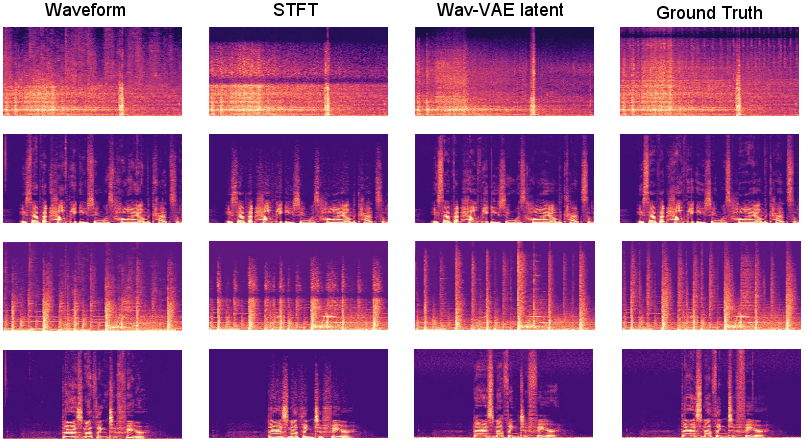
Figure 7: Super-resolution results for bridge models on different modeling spaces, highlighting the superior generalization and spectral detail of AudioLBM.
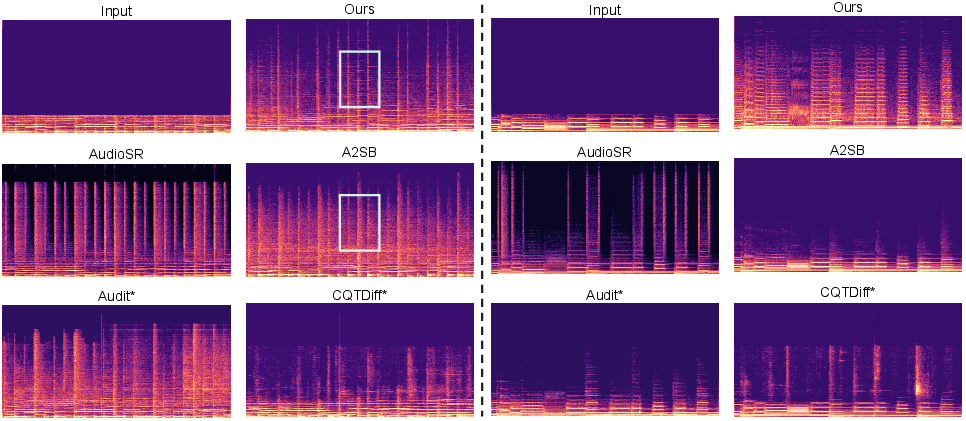
Figure 8: Qualitative comparison from A2SB's demo page, showing AudioLBM's improved harmonic richness and structural coherence.
Figure 9: Additional comparison with AudioSR, illustrating AudioLBM's better alignment and coherence across the frequency spectrum.
Implementation Considerations
Compression Rate: Lower compression rates in the VAE yield better reconstruction and SR performance, though at increased computational cost.
KL Divergence: Minimal or zero KL regularization is preferred for bridge models, as the prior is a Dirac distribution rather than Gaussian.
Inference Efficiency: AudioLBM achieves faster real-time factors (RTF) than other iterative methods, with scalable performance up to 192 kHz.
Model Architecture: The DiT-based noise predictor and Bridge-gmax schedule are critical for stable training and high-fidelity generation.
Implications and Future Directions
AudioLBM establishes a unified, high-fidelity SR framework that generalizes across speech, music, and sound effects, and is the first to demonstrate high-quality upsampling to 96 kHz and 192 kHz. The latent bridge formulation, frequency-aware conditioning, and cascaded architecture provide a blueprint for future generative models in audio and other modalities (e.g., image, video, time series).
Potential future developments include:
Extension to multimodal restoration tasks (e.g., image/video SR, time-series denoising).
Integration with generative compression and editing frameworks for end-to-end audio synthesis and manipulation.
Addressing ethical concerns related to misuse, authenticity verification, and creative labor in generative audio systems.
Conclusion
AudioLBM advances the state of audio super-resolution by modeling the LR-to-HR mapping as a latent-to-latent bridge process, leveraging frequency-aware conditioning and cascaded architectures to achieve robust, high-fidelity upsampling across diverse domains and sampling rates. The technical innovations and empirical results presented in the paper provide a strong foundation for future research in generative modeling and restoration of audio and other high-dimensional signals.