Evolution of Concepts in Language Model Pre-Training
Abstract: LLMs obtain extensive capabilities through pre-training. However, the pre-training process remains a black box. In this work, we track linear interpretable feature evolution across pre-training snapshots using a sparse dictionary learning method called crosscoders. We find that most features begin to form around a specific point, while more complex patterns emerge in later training stages. Feature attribution analyses reveal causal connections between feature evolution and downstream performance. Our feature-level observations are highly consistent with previous findings on Transformer's two-stage learning process, which we term a statistical learning phase and a feature learning phase. Our work opens up the possibility to track fine-grained representation progress during LLM learning dynamics.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper tries to open the “black box” of how LLMs learn during pre‑training. Instead of only looking at a model after it’s fully trained, the authors watch how the model’s internal “ideas” (they call them features) appear, grow, change, and sometimes fade as training progresses. They build a tool, called a crosscoder, to track these features over time and connect them to what the model can actually do on real tasks.
Think of it like filming a time‑lapse of a garden: you don’t just look at the final flowers—you watch when each sprout appears, how fast it grows, which ones last, and how they affect the whole garden.
The main questions they ask
- When do different kinds of internal features first show up during training?
- Do simple features and complex features appear at different times?
- How do features change direction (what they focus on) as training goes on?
- Do these features actually cause improvements on real tasks (like grammar)?
- Is there a bigger pattern or “phase change” in how models learn over time?
How they studied it (explained with everyday ideas)
To follow the growth of features inside a model, the authors use snapshots of the model taken at many points during training—like saving the game at different levels. They do this on two Transformer LLMs (Pythia‑160M and Pythia‑6.9B) and look at activations (the internal signals) from a middle layer.
Here are the key tools and ideas, with plain‑language analogies:
- Feature: a direction in the model’s activity that detects a specific pattern, like “plural noun,” “previous token,” or “end of a phrase.” Imagine each feature as a specialist “detector” or a tiny rule that lights up when it sees what it’s good at.
- Superposition: many features share the same limited space (neurons), like several radio stations overlapping on one wire; the model learns to separate them when needed.
- Sparse autoencoder (SAE): a “dictionary” tool that tries to explain complicated signals using a small set of meaningful building blocks (features). “Sparse” means most features stay off most of the time, making each active feature easier to interpret.
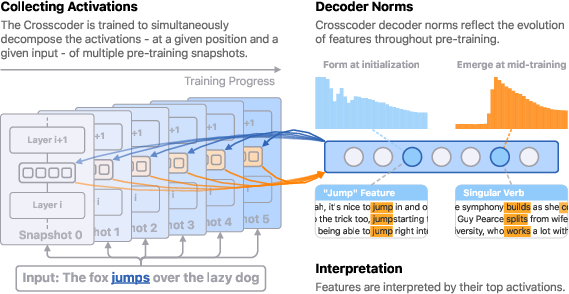
- Crosscoder: a special SAE that works across many time snapshots at once. It creates one shared set of features and learns how each snapshot “translates” those features back into the model’s activations. This lets you track the same feature across time, even if it rotates or changes a little.
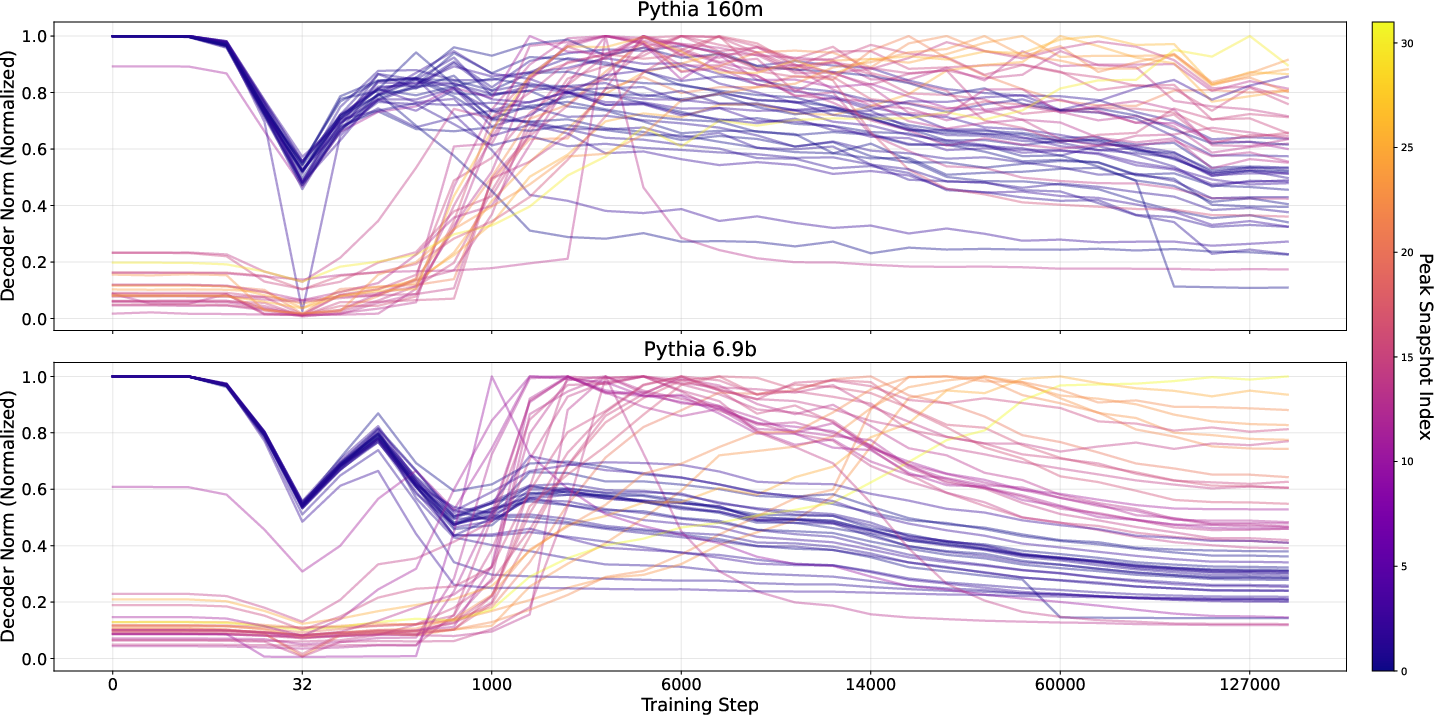
- Decoder norm (their practical trick): for each feature and snapshot, the size of its decoder vector acts like a volume meter for how “present” or “strong” that feature is at that moment in training. Bigger = stronger. Watching these sizes over time shows a feature’s growth curve.
They trained crosscoders on model activations collected from a broad text dataset (SlimPajama), using dozens of training checkpoints. Then they inspected:
- When features first appear and when they peak
- How long they last
- How their directions rotate over time
- Whether more complex features show up later
Finally, they tested whether the features they found actually matter for real tasks using attribution and ablation:
- Attribution: estimate how much a feature contributes to a task score (like subject‑verb agreement).
- Ablation: turn off selected features to see how much performance drops, or keep only a few features to see if they recover performance. This checks if the discovered features are necessary and/or sufficient.
What they found (and why it matters)
Here are the main takeaways, presented with minimal listing for clarity:
- Two kinds of features show up during training:
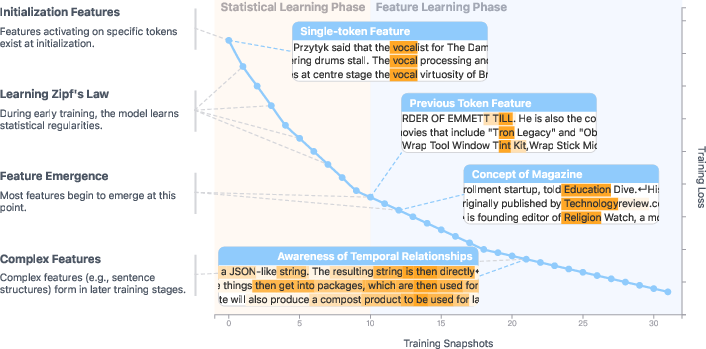
- Initialization features: present from the very start (even before meaningful learning), they dip around an early step (~128), recover, and slowly fade. These are like temporary scaffolding.
- Emergent features: these appear later (often around ~1,000 steps), then grow and persist. They’re the features that matter for real skills.
- There’s a common turning point around ~1,000 steps:
- Many features suddenly change “direction” around this time, meaning what they are sensitive to shifts significantly. After this turning point, they keep rotating more slowly. This suggests a phase change in how the model represents information.
- Complexity emerges later:
- Simpler features (like “previous token”) tend to appear early (around 1,000–5,000 steps).
- More complex features (like “induction” patterns—spotting that [A] [B] … [A] should be followed by [B], or context‑sensitive features) tend to appear later, often 10,000–100,000 steps.
- When they had an LLM rate feature complexity, later‑peaking features tended to be more complex.
- Features last:
- Once a meaningful feature emerges, it usually sticks around for a long time rather than disappearing quickly. That suggests the model builds stable building blocks.
- Features really drive task performance:
- On subject‑verb agreement (like “The teachers near the desk are”), they found specific features that:
- Detect plural nouns in subject position
- Recognize postpositional phrases (like “near the desk”) and their endings
- Turning off just a handful of these features significantly hurts performance across many training points. Keeping only these top features largely recovers performance. This shows these features are causal, not just coincidental.
- A two‑stage learning story:
- Early stage (statistical learning): The model mainly learns simple statistics—how often words appear (unigrams) and which words commonly follow each other (bigrams). The training loss drops fast as the model matches these frequency patterns.
- Later stage (feature learning in superposition): After the stats stabilize, the model starts forming interpretable, sparse features that capture more structured patterns. They measured “feature dimensionality” and saw signs of compression then expansion, consistent with moving from raw statistics into organized features that share space efficiently.
Why this matters: It gives a concrete, testable picture of how models go from memorizing basic word frequencies to building richer “concept detectors,” and it ties those detectors directly to real capabilities.
What this could change or enable
- Better training diagnostics: Instead of only tracking loss, we could watch “feature health” over time—when key features appear, how strong they are, and whether they rotate as expected.
- Safer, more controllable models: If we can identify and monitor the specific features that cause certain behaviors, we might nudge training to encourage helpful features and discourage harmful ones.
- Improved interpretability tools: Crosscoders show that it’s possible to align and track features across time, not just in a final model. This opens doors to understanding learning dynamics at a much finer level.
- Curriculum and data design: Knowing that simple features come first and complex ones later might help design training schedules or datasets that bring out desired skills more efficiently.
A few notes on limits and next steps
- They tested on two models and a set of relatively simple tasks. More models, layers, and harder tasks would further test the method.
- Crosscoders need many saved snapshots, which is compute‑heavy. Future versions might work more “online” during training.
- The picture is promising but not complete—there are likely more phases and more kinds of features to discover.
Bottom line
The paper shows that during pre‑training, LLMs seem to first learn broad word statistics, then shift into building stable, interpretable features that support real skills. Using crosscoders, the authors can watch those features appear, grow, rotate, and link them directly to performance on tasks like grammar. It’s a step toward turning training from a black box into something we can see, measure, and eventually guide.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, articulated as concrete items to guide future research.
- Validation of decoder norm as a proxy for feature presence: beyond linear probe checks, quantify how decoder norms track ground-truth causal feature strength under different regularizers, activation functions, and sparsity regimes; test for confounds where the training objective itself pushes norms to zero independent of model semantics.
- Sensitivity to crosscoder design choices: systematically vary activation functions, sparsity penalties (L0 approximations, L1/L0 hybrids, annealing schedules), and normalization strategies to measure effects on feature alignment across snapshots and downstream conclusions.
- Feature alignment fidelity across time: develop diagnostics to detect and quantify feature splitting, merging, and semantic drift across snapshots when using a single shared encoder and per-snapshot decoders; propose metrics for “alignment stability” and intervention tests when semantics change mid-training.
- Reconstruction error handling in attribution: measure how residual reconstruction error ε leaks into metric attribution and ablation conclusions; bound attribution errors as a function of reconstruction EV and derive procedures to correct or calibrate IG scores.
- Layer coverage: analyses focus on one middle layer per model; extend to early, mid, and late layers and attention vs MLP subcomponents to map where and how different feature types emerge, rotate, and consolidate across the network depth.
- Cross-layer evolution and circuit structure: combine cross-snapshot and cross-layer crosscoders to track end-to-end circuits forming over training, including how features in different layers co-emerge, hand off, or compete.
- Snapshot granularity and selection bias: assess whether the 32-snapshot stratified sampling misses short-lived events or turning points; evaluate robustness of findings with denser sampling later in training or adaptive snapshot selection driven by norm dynamics.
- Causes of the step-128 drop and recovery in initialization features: isolate whether optimizer details (Adam bias correction, LR warmup, weight decay), data ordering, or architectural factors explain this pattern, using controlled ablations and logging of optimizer states.
- Generalization across models and training recipes: replicate results across architectures (decoder-only vs encoder–decoder, MoE), tokenizers, context lengths, data mixtures, and training schedules (LR, batch size), to test universality of the statistical-to-feature learning phase transition and turning points.
- Data distribution mismatch in statistics analysis: the KL divergence analysis uses SlimPajama while Pythia was trained on The Pile; quantify bias introduced by distribution mismatch (and sampling 10M tokens) by recomputing KL with the actual training corpus, confidence intervals, and longer n-grams.
- Statistical learning scope: extend beyond unigram and bigram KL to trigrams, syntactic templates, and morphological distributions to sharpen the claim that early training is “mostly statistical” and identify precisely what statistics are learned when.
- Theoretical minimum loss claims: rigorously derive and validate the link between early training loss and entropy of the empirical distribution, accounting for temperature calibration, softmax curvature, label smoothing (if any), and tokenization artifacts.
- Measuring directional turning points: supplement cosine projection analyses with CCA/Procrustes alignment and random-feature baselines in high dimensions to verify orthogonality claims and characterize rotational dynamics more robustly.
- Feature lifetime thresholding: evaluate sensitivity of lifetime estimates to the 0.3 norm threshold; propose a principled, data-driven criterion (e.g., change-point detection, bootstrapped null distribution) to label persistence vs near-zero artifacts.
- Complexity assessment reliability: the LLM-based complexity scoring lacks ground truth and inter-rater reliability; validate with human annotation, cross-LLM agreement, and task-based probes to quantify scoring accuracy and bias.
- Discovery coverage of rule-based features: quantify recall/precision of the simple rules used to identify previous-token, induction, and context-sensitive features; develop scalable, validated detectors and examine false negatives/positives.
- Causal attribution limits: IG and linearized attributions on a single layer risk missing nonlinear interactions and cross-layer effects; compare with causal patching across multiple nodes/layers, randomized interventions, and counterfactual data to strengthen causal claims.
- Feature ablation implementation details: specify and test the ablation mechanism (zeroing f_i, shrinking decoders, or masking reconstructions) for side effects; verify that ablations do not induce distributional shifts that invalidate metric interpretations.
- Circuit competition and alternation: the observed alternation of dominant features in SVA circuits is described but not explained; analyze when and why circuits swap dominance, and whether optimizer dynamics, data shifts, or representational compression drive these changes.
- Total feature dimensionality measurement bias: dimensionality ratios depend on dictionary size and training quality; scale feature counts (e.g., 32k vs 98k vs >1M), apply debiasing, and calibrate against known ground-truth synthetic superposition benchmarks.
- Superposition quantification under imperfect dictionaries: develop methods to estimate “missing dimensions” of superposed features when the dictionary underfits, including upper/lower bounds and extrapolations from dictionary size scaling curves.
- Generalization to complex downstream tasks: extend attribution and ablation analyses to multi-hop reasoning, long-context tasks, chain-of-thought, code generation, and instruction-following to test whether the micro–macro connection holds under richer behaviors.
- Attribution to attention heads and MLP neurons: map crosscoder features back to concrete architectural units (heads, MLP neurons, residual paths) over time to link dictionary features with canonical transformer circuits and test known causal dependencies.
- Robustness across seeds and data shards: repeat experiments with multiple random initializations, data orders, and seeds to quantify variance in emergence timing, turning points, and directional rotations; report confidence intervals on key metrics.
- Calibration of decoder norm scales across features: the per-feature linear rescaling hides absolute magnitude differences; introduce global calibration (e.g., per-snapshot z-scores, temperature scaling) to enable cross-feature comparability of strength and emergence steepness.
- Online/continuous training tracking: propose and test architectures capable of streaming activations and gradients to capture continuous-time dynamics without discrete snapshot constraints, measuring whether conclusions change at finer temporal resolution.
- Faithfulness and completeness audits: provide rigorous quantitative audits (e.g., completeness scores, causal consistency tests across interventions) that tie reconstruction EV and feature sparsity to interpretability quality at each snapshot.
- Interplay with tokenization and positional encoding: examine how tokenization schemes and positional representations shape early statistical learning and later feature formation (e.g., previous-token features vs positional heuristics).
- Degeneration and pruning of features: characterize when and why features degenerate or are pruned later in training, and whether this reflects representational compression, task shifts, or competition for representational capacity.
- Integration with training-loop diagnostics: explore using crosscoder-derived signals (e.g., feature birth rates, dimensionality compression) to adapt learning rate schedules, regularization, or curriculum in real time, testing whether steering training dynamics improves performance or safety.
Practical Applications
Immediate Applications
Below are near-term, deployable uses derived from the paper’s methods and findings. Each item names candidate sectors, potential tools/workflows, and key assumptions or dependencies.
- Feature-evolution dashboards for pre-training and fine-tuning operations
- Sectors: Software/ML Ops, Energy/Cloud, Finance (budgeting)
- What: Integrate cross-snapshot crosscoders into training pipelines to visualize decoder-norm trajectories, the universal turning point (≈ step 1k), and emergence of key circuits (e.g., previous-token vs. induction features).
- Tools/Workflows: Feature Evolution Dashboard; Snapshot Selection Assistant; per-layer “feature health” monitors
- Assumptions/Dependencies: Access to frequent checkpoints and activations; crosscoder training overhead; decoder norms remain faithful proxies of feature strength on target stack/dataset.
- Early-warning and gating for capability emergence
- Sectors: Safety/Policy, Enterprise software, Healthcare
- What: Use attribution-based circuit tracing (integrated gradients on decomposed activations) to rank and monitor features causally tied to downstream task performance (e.g., induction, IOI, SVA). Trigger human review or training gates when risky capabilities or sensitive content features cross thresholds.
- Tools/Workflows: Capability Emergence Monitor; Safety Gate Triggers; automated alerts on decoder-norm spikes in risky feature classes
- Assumptions/Dependencies: Reliable mapping from features to capabilities; coverage limits in attribution; false positives/negatives must be managed.
- Data curriculum and mixture scheduling informed by the two-phase learning dynamic
- Sectors: Software/ML, Energy/Cloud
- What: Front-load simpler statistical corpora to accelerate unigram/bigram convergence in the statistical phase; introduce more structured/complex data as emergent features begin forming; adjust snapshot frequency and logging around the turning point to maximize observability.
- Tools/Workflows: Curriculum Scheduler driven by decoder-norm trends; dynamic dataset mixing rules
- Assumptions/Dependencies: Observed phase timing generalizes beyond Pythia; data pipelines are modular; continuous monitoring is available.
- Checkpoint triage for cheaper, targeted fine-tuning
- Sectors: All industries using LLMs; Healthcare, Finance (domain adaptation)
- What: Select pre-training snapshots close to the emergence of task-relevant features (e.g., later snapshots for induction-heavy tasks), cutting SFT/adapter costs and time to quality.
- Tools/Workflows: Snapshot Recommender; feature-to-task alignment reports
- Assumptions/Dependencies: Access to intermediate checkpoints or open-weight bases; stability of feature–task alignment across domains.
- Feature-aware pruning and distillation
- Sectors: Edge AI, Mobile, Robotics
- What: Identify features with low or negative attribution to target metrics and ablate/prune them; distill high-attribution features to compact models while preserving performance.
- Tools/Workflows: Feature-Aware Pruner; Sparse-Feature Distiller
- Assumptions/Dependencies: Crosscoder completeness/high-fidelity reconstructions; attribution validity under distribution shift.
- Model diffing and regression detection across training and chat-tuning
- Sectors: Software/ML Ops, Compliance
- What: Use crosscoders to compare feature dictionaries across pre-training and post-training (e.g., chat-tuning) to detect regressions or unexpected capability shifts.
- Tools/Workflows: Cross-snapshot Diff Reports; “before/after” capability fingerprints
- Assumptions/Dependencies: Consistent activation sampling; cross-snapshot feature alignment quality.
- Bias/toxicity emergence tracking
- Sectors: Social platforms, Hiring, Healthcare
- What: Track decoder-norm growth in features indicative of demographic, toxic, or sensitive patterns; intervene via data reweighting, gradient surgery, or gating.
- Tools/Workflows: Bias Emergence Tracker; targeted data augmentation when flagged
- Assumptions/Dependencies: Reliable feature labeling pipelines; careful validation to reduce spurious correlations.
- Training energy and budget planning around the phase transition
- Sectors: Energy/Cloud, Finance (FinOps)
- What: Plan compute usage and logging intensity to match the statistical-to-feature transition; defer expensive high-resolution logging until near turning points; adjust LR/optim schedules when feature formation plateaus.
- Tools/Workflows: Phase-Aware Training Planner; green-energy scheduling aligned to heavy phases
- Assumptions/Dependencies: Turning-point predictability in larger models; ops integration with cluster schedulers.
- Governance artifacts and model cards with feature-evolution summaries
- Sectors: Policy/Regulatory, Finance model risk, Healthcare compliance
- What: Publish “Feature Evolution Reports” summarizing phase timing, key emergent features, and causal links to metrics; support audits and internal/external disclosures.
- Tools/Workflows: Report Generator; standardized feature-evolution schemas for model cards
- Assumptions/Dependencies: Emerging standards; willingness to disclose training dynamics.
- Teaching and communication aids for ML education
- Sectors: Education, Upskilling in industry
- What: Use real examples (e.g., decoder-norm rotations, hierarchy from previous-token to induction to context-sensitive features) to teach representation learning and interpretability.
- Tools/Workflows: Interactive notebooks; classroom labs with public Pythia checkpoints
- Assumptions/Dependencies: Availability of open checkpoints; simplified demos fit course time/compute.
Long-Term Applications
These use cases require further research, scaling, or ecosystem development before broad deployment.
- Real-time, in-the-loop crosscoders for training-time control
- Sectors: ML Ops, Safety
- What: Online crosscoders that update as training proceeds, enabling immediate visibility into feature formation and on-the-fly interventions (e.g., learning-rate/curriculum tweaks).
- Tools/Workflows: Streaming Crosscoder; asynchronous activation sampling
- Assumptions/Dependencies: Algorithmic advances to reduce overhead; distributed training integration.
- Feature-level regularization and capability shaping
- Sectors: Safety/Policy, Healthcare, Finance
- What: Penalize/encourage formation of specific feature families during training; enforce caps on risky feature norms; promote monosemantic features for auditability.
- Tools/Workflows: Feature-aware Optimizer; interpretable regularizers embedded in the loss
- Assumptions/Dependencies: Reliable, low-latency attribution; tight coupling of features and behaviors with low collateral damage.
- Superposition-aware architectures and training schemes
- Sectors: Software/Hardware co-design
- What: Architectures with built-in dictionary bottlenecks or constraints that reduce harmful superposition while preserving performance; explicit feature channels for interpretability.
- Tools/Workflows: Monosemantic layers; orthogonality-promoting objectives
- Assumptions/Dependencies: Competitiveness vs. standard Transformers; no undue loss in accuracy.
- Automated curriculum discovery and optimization
- Sectors: Enterprise ML, EdTech
- What: Use feature evolution trajectories as signals for auto-search over data curricula that accelerate desired capabilities and suppress undesired ones.
- Tools/Workflows: AutoCurriculum Search; closed-loop training with feature feedback
- Assumptions/Dependencies: Robust generalization of feature–data relationships; compute for meta-optimization.
- Safety regulation and compliance triggers based on feature thresholds
- Sectors: Policy/Regulation, Government procurement
- What: Define standardized thresholds on decoder norms/attributions for dangerous feature classes that trigger audits, red-teaming, or training suspension.
- Tools/Workflows: Regulator-grade “feature threshold” specifications; certifiable logging infrastructure
- Assumptions/Dependencies: Community consensus on hazard taxonomies; validated mappings from features to harm.
- Feature-based modularization and distillation into plug-in capabilities
- Sectors: Edge AI, Robotics, Healthcare devices
- What: Distill models into composable feature modules; ship only the feature packs needed for a domain; hot-swap modules as capabilities evolve.
- Tools/Workflows: Feature Module Builder; capability pack manager
- Assumptions/Dependencies: Stable feature alignment across updates; sufficient reconstruction fidelity.
- IP and data-lineage forensics via feature–dataset links
- Sectors: Legal/IP, Media
- What: Attribute certain features to specific data sources or styles; detect memorization; enable IP compliance and data provenance claims.
- Tools/Workflows: Feature–Data Traceback; memorization detectors keyed by feature activations
- Assumptions/Dependencies: Strong statistical linkage methods; low false attribution rates.
- Risk-scored model marketplaces using “feature fingerprints”
- Sectors: Finance, Government, Enterprise procurement
- What: Marketplaces listing models with standardized feature-evolution fingerprints and risk scores, aiding buyers in compliance and capability selection.
- Tools/Workflows: Fingerprint Generator; third-party verification services
- Assumptions/Dependencies: Inter-vendor standards; incentives for disclosure.
- Domain-specific safety layers and guardrails built from feature libraries
- Sectors: Enterprise SaaS, Healthcare, Education
- What: Construct guardrails that target high-risk feature families (e.g., self-harm, PHI exposure) detected in context; adaptively block or steer outputs.
- Tools/Workflows: Feature-aware Guardrail SDKs; runtime monitors for feature activations
- Assumptions/Dependencies: Reliable online feature readout; latency/throughput constraints.
- Backward-compatible continual learning via feature alignment
- Sectors: Software/ML Ops
- What: Use cross-model feature alignment to ensure updates preserve critical capabilities; provide migration tools that monitor and correct feature drift.
- Tools/Workflows: Compatibility Checker; drift-correction training loops
- Assumptions/Dependencies: Stable cross-model alignment methods; diverse evals to verify compatibility.
- Agent/robotics capability gating at the circuit level
- Sectors: Robotics, Cybersecurity
- What: Detect and throttle features associated with unsafe exploration, deception, or hacking; gate actuation when feature norms exceed safe envelopes.
- Tools/Workflows: Safety Envelope Monitors; actuation gates tied to feature thresholds
- Assumptions/Dependencies: Robust adversarial resilience; strong causal links from features to behaviors.
- Energy-aware, phase-aligned training policies at fleet scale
- Sectors: Energy/Cloud, Green computing
- What: Align the statistically heavy vs. feature-heavy phases with grid availability/pricing; proactively schedule heavy logging and compute during low-carbon windows.
- Tools/Workflows: Energy-Aware Trainers; grid-integrated schedulers
- Assumptions/Dependencies: Accurate phase forecasting for large models; orchestration across datacenters.
Notes on cross-cutting assumptions
- Generalization: Findings (e.g., turning point near step 1k, hierarchy from previous-token to induction to context-sensitive features) were shown on Pythia models; validation on larger, different architectures and datasets is needed.
- Observability: Most immediate uses require access to intermediate checkpoints and activations; closed models without snapshots will limit applicability.
- Attribution fidelity: Integrated gradients on crosscoder-decomposed activations provide a first-order view; causal claims should be validated with ablations/interventions.
- Cost/latency: Training crosscoders across many snapshots is compute- and memory-intensive; online or streaming variants will be needed for production-scale training.
Glossary
- Activation variance explained: A measure of how much of the original activation variability is captured by a reconstruction method. "We evaluate reconstruction quality (measured by activation variance explained) and sparsity (measured by L0 norm averaged across snapshots)."
- Attribution-based circuit tracing: Techniques that assign credit to internal components (features) to explain model behavior causally. "we employ attribution-based circuit tracing techniques~\citep{syed2023attributionpatching, ge2024automatically, marks2025sparsefeaturecircuits}"
- Attribution patching: An attribution method comparing clean vs. corrupted inputs to isolate components responsible for performance differences. "we can employ the full framework of attribution patching~\citep{syed2023attributionpatching, marks2025sparsefeaturecircuits}"
- Attribution score: A quantity assigning contribution of a feature to a task-specific metric, often via gradients. "This attribution score employs first-order Taylor expansion as a linear approximation of model computation."
- Bigram KL divergence: The Kullback–Leibler divergence between model and true distributions over token pairs, measuring statistical mismatch. "and bigram KL divergence $\mathrm{D}_{\mathsf{KL}(P(x_i \mid x_{i-1}) \parallel Q(x_i \mid x_{i-1}))$."
- Cosine similarity: A normalized dot product indicating directional alignment in high-dimensional spaces. "with directions at the final snapshot maintaining notable cosine similarities to their initial post-step 1,000 orientations"
- Cross-layer superposition: Overlapping representation of multiple features across different layers, making them hard to disentangle. "introduced to resolve cross-layer superposition and track features distributed across layers"
- Crosscoder: A sparse dictionary learning model that jointly reads/writes across multiple correlated activation sets (e.g., snapshots) to align features. "We introduce crosscoders to study feature evolution in LLM pre-training."
- Decoder norm: The norm of a decoder vector associated with a feature, used as a proxy for that feature’s strength/presence. "the decoder norm directly reflects the strength and presence of feature at snapshot ."
- Dictionary learning: Methods that represent data as sparse combinations of learned basis vectors (dictionaries). "using a sparse dictionary learning method called crosscoders."
- Feature attribution: Analysis assigning contributions of internal features to model outputs or metrics. "Feature attribution analyses reveal causal connections between feature evolution and downstream performance."
- Feature dimensionality: An estimate of the effective number of independent directions spanned by features under superposition. "Total feature dimensionality undergoes compression and expansion."
- Feature learning phase: A later training stage where interpretable features emerge in superposition to further reduce loss. "which we term a statistical learning phase and a feature learning phase."
- Grokking: Delayed generalization where models abruptly transition from memorization to rule-based performance after extended training. "generalization and grokking"
- Information Bottleneck (IB) theory: A framework viewing learning as a trade-off between compression of inputs and prediction quality. "Information Bottleneck (IB) theory~\citep{tishby2015informationbottleneck} formulates deep learning as optimizing compression-prediction tradeoffs."
- Indirect Object Identification (IOI): A mechanistic interpretability benchmark task probing specific circuit behavior in LLMs. "indirect object identification (IOI)~\citep{wang2023ioi} tasks"
- Induction features: Features that activate on repeated substrings to help predict subsequent tokens in copy-like patterns. "induction features (which activate on the second [A] in patterns [A] [B]...[A] [B] and help predict [B])"
- Induction heads: Attention heads implementing induction-like copying behavior over repeated token patterns. "between induction heads and previous token heads~\citep{olsson2022induction}"
- Initialization features: Features present from random initialization that may transiently drop and recover early in training. "Initialization features that exist from random initialization, exhibit a sudden drop and recovery around step $128$, then gradually decay."
- Integrated gradient (IG): An attribution method integrating gradients along a path from a baseline to the input to estimate contributions. "we employ the integrated gradient (IG) version of the attribution scores"
- KL divergence: A measure of divergence between two probability distributions, used to assess statistical learning. "we compute the KL divergence between the true token distribution and the model's predicted distribution ."
- L0 regularization: A sparsity-inducing penalty that counts nonzero coefficients, typically approximated for differentiability. "a differentiable substitute for L0 regularization"
- L1 regularization: A convex sparsity penalty summing absolute values of coefficients. "such as L1 regularization"
- Linear probes: Simple linear models trained on fixed activations to test whether information is linearly decodable. "serve as a proxy of feature strength using linear probes."
- Logit differences: Differences between logits for correct vs. corrupted targets, used as evaluation metrics. "using logit differences between clean and corrupted answers as metrics."
- Monosemantic features: Features that activate for a single interpretable concept, not conflating multiple meanings. "Sparse Autoencoders (SAEs)~\citep{bricken2023monosemanticity, hubun2024sae,he2024llamascope} extract monosemantic features from superposition"
- Neural Tangent Kernel (NTK): A theoretical framework where wide neural networks behave like kernel machines during training. "Neural Tangent Kernel (NTK) theory~\citep{jacot2018ntk} establishes that infinite-width networks evolve as kernel machines"
- Real Log Canonical Threshold: A quantity from algebraic geometry and SLT that measures model singularity and predicts phase transitions. "introduces the Real Log Canonical Threshold to provide geometric complexity measures predicting phase transitions"
- Reconstruction loss: The loss term measuring discrepancy between original activations and their reconstruction from features. "Reconstruction loss"
- Scaling laws: Empirical relationships predicting loss as a function of compute, data, and model size. "scaling laws~\citep{hestness2017scaling, kaplan2020scalinglaws, bahri2021explainscalinglaws} reveal the predictable relationships between compute, data, and loss"
- Singular Learning Theory (SLT): A framework treating neural networks as singular statistical models to analyze generalization and phases. "Singular Learning Theory (SLT) treats neural networks as singular statistical models."
- Sparse autoencoder (SAE): A model that learns sparse feature representations to decompose superposed activations. "Sparse Autoencoders (SAEs)~\citep{bricken2023monosemanticity, hubun2024sae,he2024llamascope} extract monosemantic features from superposition"
- Sparse codes: Low-activity feature representations where only a few features are active per input. "the unified feature space (or sparse codes) they reveal."
- Sparse penalty: A regularization term encouraging sparsity in feature activations. "the sparse penalty will suppress the decoder norms"
- Sparsity loss: The component of the objective that penalizes non-sparse activations. "Sparsity loss"
- Statistical learning phase: An early training stage focused on matching simple distributional statistics before feature emergence. "which we term a statistical learning phase and a feature learning phase."
- Subject-verb agreement (SVA): A linguistic evaluation where models must match verb number to the subject. "subject-verb agreement (SVA)~\citep{matthew2021sva}"
- Superposition: The overlapping encoding of many features within fewer neurons or dimensions than features. "By disentangling the phenomenon of superposition"
- Unigram KL divergence: The KL divergence between model and true marginal token distributions. "We then evaluate unigram KL divergence $\mathrm{D}_{\mathsf{KL}(P(x) \parallel Q(x))$"
- Zipf's law: A statistical regularity in token frequency distributions, often learned early by LLMs. "Zipf's law~\citep{zipf1935psychobiology, piantadosi2014zipfs}"
Collections
Sign up for free to add this paper to one or more collections.

