- The paper introduces a biologically-inspired saccadic vision framework that merges peripheral and fixation-based encoding to enhance fine-grained classification.
- It uses a multi-granular encoder and a priority map to select fixation patches for detailed image analysis without complex localization.
- Experimental results on FGVC benchmarks show improved accuracy and efficiency, demonstrating the promise of saccadic models in computer vision.
Saccadic Vision in Fine-Grained Visual Classification
Introduction
The paper "Saccadic Vision for Fine-Grained Visual Classification" (2509.15688) introduces a novel approach to Fine-Grained Visual Classification (FGVC). FGVC involves distinguishing between categories with subtle visual differences, such as bird species or insect types. Standard classification models struggle with FGVC due to high intra-class variability and minimal inter-class differences. Saccadic Vision, inspired by human visual mechanisms, offers a solution by utilizing a two-stage process that integrates peripheral and focus view representations through fixation sampling and encoding. This approach aims to overcome the limitations inherent in existing part-based methods.
Methodology
The proposed methodology consists of a biologically-inspired framework that emulates human saccadic vision. It involves a multi-granular encoder architecture that processes peripheral images followed by fixation patch sampling from a priority map. This priority map guides the selection of fixation points for detailed image analysis.
Multi-Granular Encoder: The framework utilizes a shared multi-stage encoder across input views, which allows for the extraction of peripheral features. A priority map is constructed from high-level features that facilitate fixation point sampling, effectively bypassing complex localization networks that are traditionally necessary in FGVC (Figure 1).
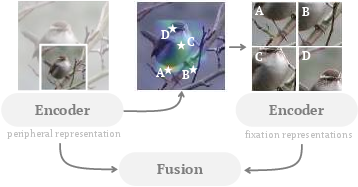
Figure 1: The saccader extends the usual forward prediction process by sampling fixation points from a priority map generated by the encoder, extracting fixation patches at these positions, and calling the encoder again with these refined inputs.
Fixation Sampling: Fixation points are sampled from the priority map using a non-maximum suppression algorithm to prevent redundancy and spatial collapse. The sampled fixation patches are re-encoded using the same shared encoder to provide a detailed view, which is fused with the peripheral representation using contextualized selective attention.
Fusion Process: The fusion of peripheral and focus representations is achieved through a weight-shared architecture that employs adaptive weighting for dynamic fixation patch relevance assessment. This eliminates redundant computation seen in conventional models by using selective attention and a single encoder for both types of visual representations (Figure 2).
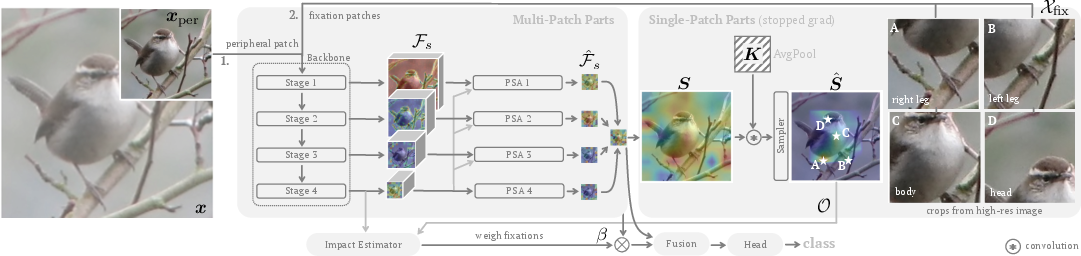
Figure 2: A multi-stage backbone is used to encode a downsampled (peripheral) view $\mathbf{x.$
Experimental Evaluation
The methodology was evaluated across several FGVC benchmarks, including CUB-200-2011, NABirds, Food-101, and Stanford-Dogs, as well as challenging insect datasets like EU-Moths and Ecuador-Moths. These experiments demonstrated that the proposed saccadic vision approach performs competitively with state-of-the-art methods, evidencing its adaptability across diverse datasets with varying complexities.
Performance Results: The model consistently surpassed baseline encoder performance and exhibited robust classification accuracy, especially in datasets featuring less background noise, where fixation sampling can operate without interference (Figure 3).
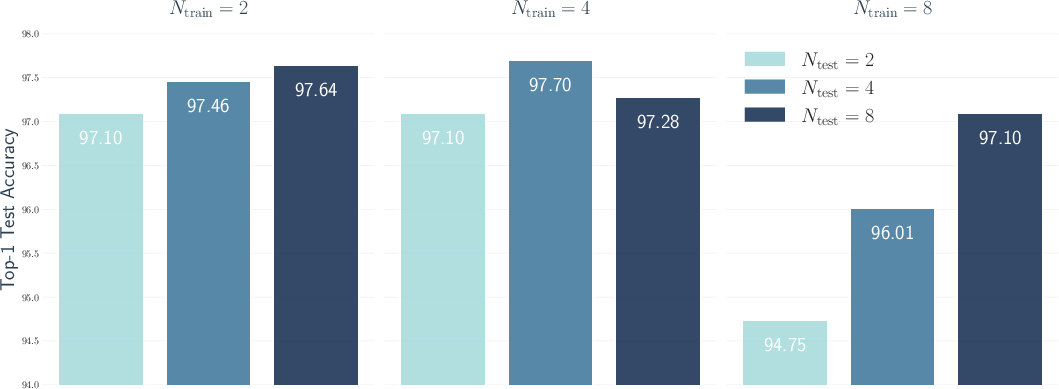
Figure 3: Average Top-1 Test Accuracy on EU with different number of fixation patches during training and testing.
Runtime Efficiency: Although the fixation sampling algorithm introduces linear complexity to the system, empirical measurements indicate slight exponential growth in runtime with increased testing samples, attributed to memory hierarchy effects and synchronization overhead (Figure 4).
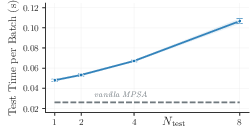
Figure 4: Average walltime in seconds (with confidence interval) over 32 test batches (EU) on an NVIDIA A40.
Conclusion
The saccadic vision framework represents a substantial advancement in FGVC by accurately modeling the human visual attention mechanism. Its strengths include reducing the need for complex localization networks and effectively consolidating feature representations across visual resolutions. However, implementing dynamic scale adaptations and affine transformations on fixation patches remains unexplored, suggesting avenues for future development. Moreover, integrating and extending fixation process models using information-theoretic principles emphasizes the potential for enhancing temporal sampling strategies. The framework's success underscores the viability of biologically-inspired models in advancing computer vision methodologies.

