- The paper introduces a single-decoder Transformer that interleaves semantic and acoustic tokens using a unified tokenizer, streamlining speech generation.
- It achieves state-of-the-art acoustic consistency and speaker preservation while maintaining competitive linguistic performance through autoregressive token prediction.
- Experiments reveal a trade-off between audio fidelity and linguistic coherence, highlighting the impact of model size and quantizer settings on performance.
Llama-Mimi: Speech LLMs with Interleaved Semantic and Acoustic Tokens
Introduction and Motivation
Llama-Mimi presents a streamlined approach to speech language modeling by leveraging a unified tokenizer and a single Transformer decoder to jointly model interleaved semantic and acoustic tokens. This design contrasts with prior multi-stage or multi-transformer architectures, such as AudioLM and Moshi, which introduce architectural complexity and deployment challenges. The motivation is to simplify the speech generation pipeline while maintaining or improving performance in both acoustic fidelity and linguistic coherence.
Model Architecture
The core of Llama-Mimi is a single-decoder Transformer (Llama 3 backbone) that autoregressively predicts sequences of interleaved semantic and acoustic tokens. The unified tokenizer, based on Mimi, converts audio waveforms into residual vector quantizer (RVQ) tokens, with the first-level quantizers semantically distilled from WavLM. Tokens are ordered per frame, and the model predicts semantic tokens first, conditioning subsequent acoustic tokens on them within each frame. The vocabulary is extended to include audio tokens and special delimiters, enabling seamless integration of text and audio modalities.
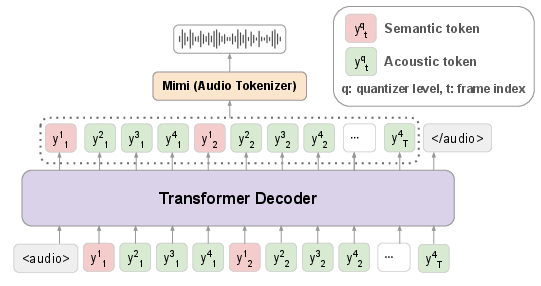
Figure 1: Model architecture of Llama-Mimi, illustrating the unified tokenizer and single-decoder Transformer for interleaved semantic and acoustic token modeling.
This architecture allows the model to attend to all past tokens, capturing both long-term dependencies and fine-grained acoustic variations. Training follows standard next-token prediction, with inference proceeding autoregressively until the end-of-audio token is generated.
Experimental Setup
Llama-Mimi is instantiated in two sizes: 1.3B and 8B parameters. Training utilizes large-scale English speech corpora (Libri-Light, The People's Speech, VoxPopuli, Emilia), totaling approximately 240k hours. Audio is tokenized at 12.5Hz with Q=4 quantizers, yielding 50 tokens/sec. Models are initialized from pretrained Llama 3 checkpoints, with Mimi parameters frozen. Training is performed on 32 NVIDIA H200 GPUs using FSDP, with a global batch size of 1,024 and a maximum sequence length of 1,024 tokens.
Evaluation Methodology
Likelihood-Based Evaluation
Acoustic consistency and alignment are assessed using SALMon, which measures the model's ability to assign higher likelihoods to natural samples versus those with unnatural acoustic changes. Semantic knowledge is evaluated with sWUGGY, sBLIMP, and sTopic-StoryCloze, focusing on word validity, grammaticality, and continuation coherence. Perplexity is computed over semantic tokens, except for SALMon.
Generation-Based Evaluation
Speech generation is evaluated by prompting the model with short audio and generating continuations. Speaker consistency is measured via cosine similarity of WavLM-based embeddings. Spoken content quality is assessed using an LLM-as-a-Judge framework, where GPT-4o rates transcribed continuations for relevance, coherence, fluency, and informativeness. This approach addresses the instability of perplexity-based metrics, which are sensitive to sequence length and sampling.
Results and Analysis
Llama-Mimi achieves state-of-the-art results in acoustic consistency, outperforming baselines such as GSLM, TWIST, and Flow-SLM. The model's ability to attend to all tokens enables superior modeling of subtle acoustic properties and speaker identity. On semantic tasks, Llama-Mimi performs slightly below SSL-based models, attributed to longer sequence lengths that challenge global information capture. Increasing model size improves semantic performance but has minimal impact on acoustic metrics.
Speaker Consistency and Content Quality
Llama-Mimi demonstrates strong speaker preservation, with higher similarity scores than baselines. LLM-as-a-Judge scores for spoken content quality are more reliable than perplexity, with larger models achieving better ratings and ground-truth references scoring highest. This validates the effectiveness of the LLM-based evaluation framework.
Qualitative Generation
Qualitative analysis shows that the 8B model produces more natural and coherent continuations than the 1.3B variant, indicating that model capacity is critical for handling long sequences and maintaining coherence.
Quantizer Ablation
Increasing the number of quantizers (Q) improves audio quality and speaker similarity but degrades spoken content quality. This trade-off highlights the challenge of balancing acoustic fidelity with linguistic coherence, as longer token sequences strain the model's ability to maintain global context.
Implementation Considerations
- Computational Requirements: Training Llama-Mimi requires significant resources (32 H200 GPUs, large batch sizes), but the single-decoder architecture simplifies deployment compared to multi-stage pipelines.
- Tokenization Strategy: Unified tokenization enables joint modeling of semantic and acoustic information, reducing the need for specialized tokenizers and facilitating end-to-end training.
- Sequence Length: Longer token sequences, especially with higher quantizer counts, can hinder linguistic performance. Careful tuning of quantizer number and frame rate is necessary to balance fidelity and coherence.
- Evaluation: LLM-as-a-Judge provides a robust alternative to perplexity for spoken content quality, especially in open-ended generation scenarios.
Implications and Future Directions
Llama-Mimi demonstrates that a single-decoder Transformer with unified tokenization can achieve competitive or superior performance in speech generation tasks, simplifying the architecture and deployment. The observed trade-off between acoustic fidelity and linguistic coherence suggests future work in dynamic token allocation, adaptive quantization, or hierarchical attention mechanisms to mitigate sequence length challenges. The LLM-as-a-Judge evaluation framework may become standard for assessing generative spoken content, given its reliability and alignment with human judgment.
Conclusion
Llama-Mimi advances speech language modeling by unifying semantic and acoustic token processing within a single Transformer decoder. The model achieves state-of-the-art acoustic consistency and speaker preservation, with a clear trade-off between audio fidelity and long-term coherence. The adoption of LLM-as-a-Judge for spoken content evaluation sets a precedent for future benchmarking. This work paves the way for more efficient, scalable, and robust speech generation systems, with potential extensions in multilingual, multimodal, and streaming applications.