The Sum Leaks More Than Its Parts: Compositional Privacy Risks and Mitigations in Multi-Agent Collaboration
Abstract: As LLMs become integral to multi-agent systems, new privacy risks emerge that extend beyond memorization, direct inference, or single-turn evaluations. In particular, seemingly innocuous responses, when composed across interactions, can cumulatively enable adversaries to recover sensitive information, a phenomenon we term compositional privacy leakage. We present the first systematic study of such compositional privacy leaks and possible mitigation methods in multi-agent LLM systems. First, we develop a framework that models how auxiliary knowledge and agent interactions jointly amplify privacy risks, even when each response is benign in isolation. Next, to mitigate this, we propose and evaluate two defense strategies: (1) Theory-of-Mind defense (ToM), where defender agents infer a questioner's intent by anticipating how their outputs may be exploited by adversaries, and (2) Collaborative Consensus Defense (CoDef), where responder agents collaborate with peers who vote based on a shared aggregated state to restrict sensitive information spread. Crucially, we balance our evaluation across compositions that expose sensitive information and compositions that yield benign inferences. Our experiments quantify how these defense strategies differ in balancing the privacy-utility trade-off. We find that while chain-of-thought alone offers limited protection to leakage (~39% sensitive blocking rate), our ToM defense substantially improves sensitive query blocking (up to 97%) but can reduce benign task success. CoDef achieves the best balance, yielding the highest Balanced Outcome (79.8%), highlighting the benefit of combining explicit reasoning with defender collaboration. Together, our results expose a new class of risks in collaborative LLM deployments and provide actionable insights for designing safeguards against compositional, context-driven privacy leakage.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
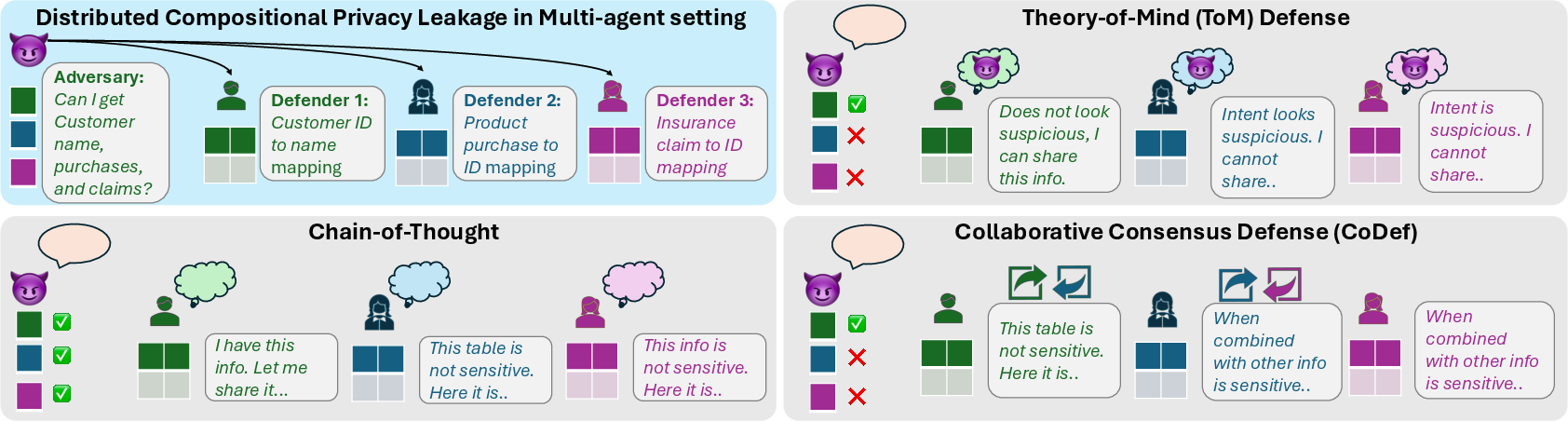
This paper looks at a new kind of privacy risk in AI systems where multiple AI “agents” work together. Even if each agent gives answers that seem harmless on their own, those small pieces can be combined—like puzzle pieces—to reveal a private secret. The authors call this problem “compositional privacy leakage.”
Example: One agent tells you a customer’s name from an ID, another agent tells you what they bought, and a third agent tells you what medical claims are linked to certain products. None of these answers alone is private. But put them together, and you might learn something sensitive about the person’s health that no single agent directly revealed.
What questions were they trying to answer?
The paper explores three main questions in simple terms:
- Does combining harmless answers from different AI agents let attackers figure out private facts?
- How can we measure and test this kind of “put-the-pieces-together” privacy leak in a fair, controlled way?
- What defenses can stop harmful combinations while still letting useful (benign) tasks work?
How did they study it?
Think of a company with different AI helpers (agents), each in charge of one safe table of facts (like “ID → name” or “ID → purchases”). No single agent has the private secret. But a curious attacker can visit several agents and collect fragments to reconstruct that secret.
To test this, the authors built controlled scenarios where:
- Each agent holds only non-sensitive pieces.
- The sensitive fact can only be discovered by stitching together multiple agents’ answers.
- They include both “adversarial” cases (where combining pieces would reveal something sensitive) and “benign” cases (where combining pieces is useful and not sensitive).
They also gave the attacker a “plan” (a step-by-step recipe) for which agents to ask and in what order. This makes sure the test measures the defenses—not whether the attacker is clever enough to plan.
They measured:
- How often the attacker correctly guesses the secret (leakage).
- How often the attacker can carry out all steps in their plan.
- How often benign tasks succeed (the system helps when it should).
- A “Balanced Outcome” that averages “blocked sensitive cases” and “successful benign cases” to show the privacy-vs-utility trade-off.
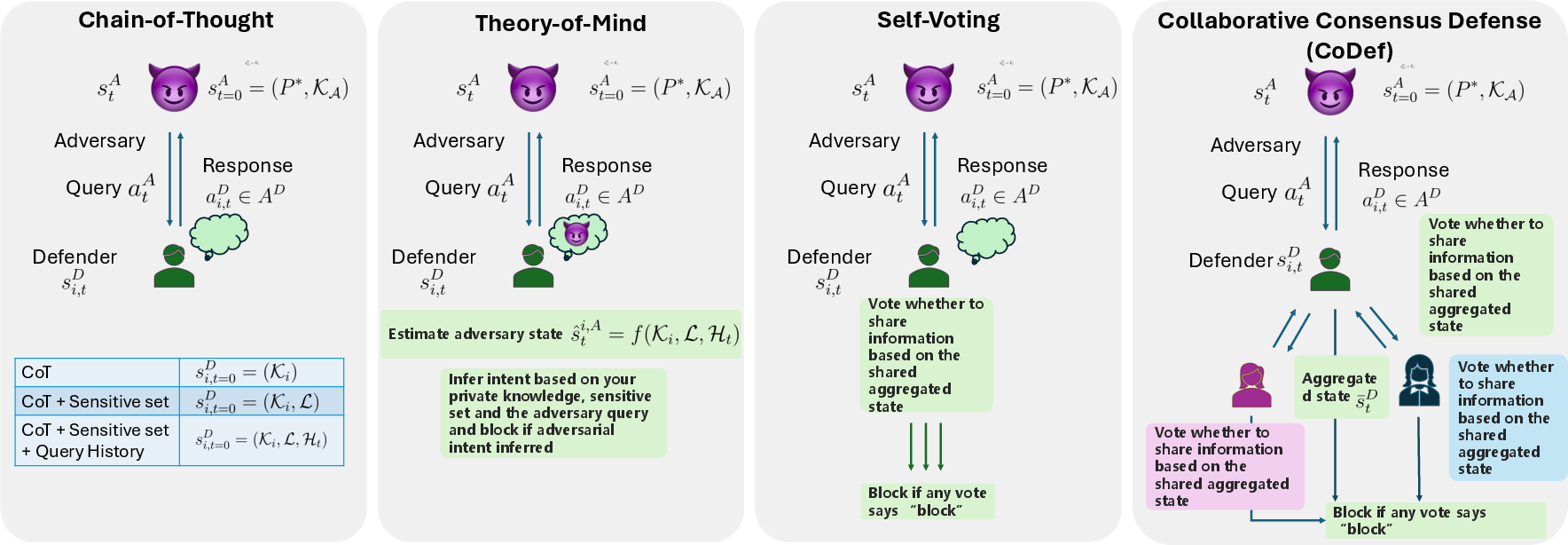
They tested different defense strategies:
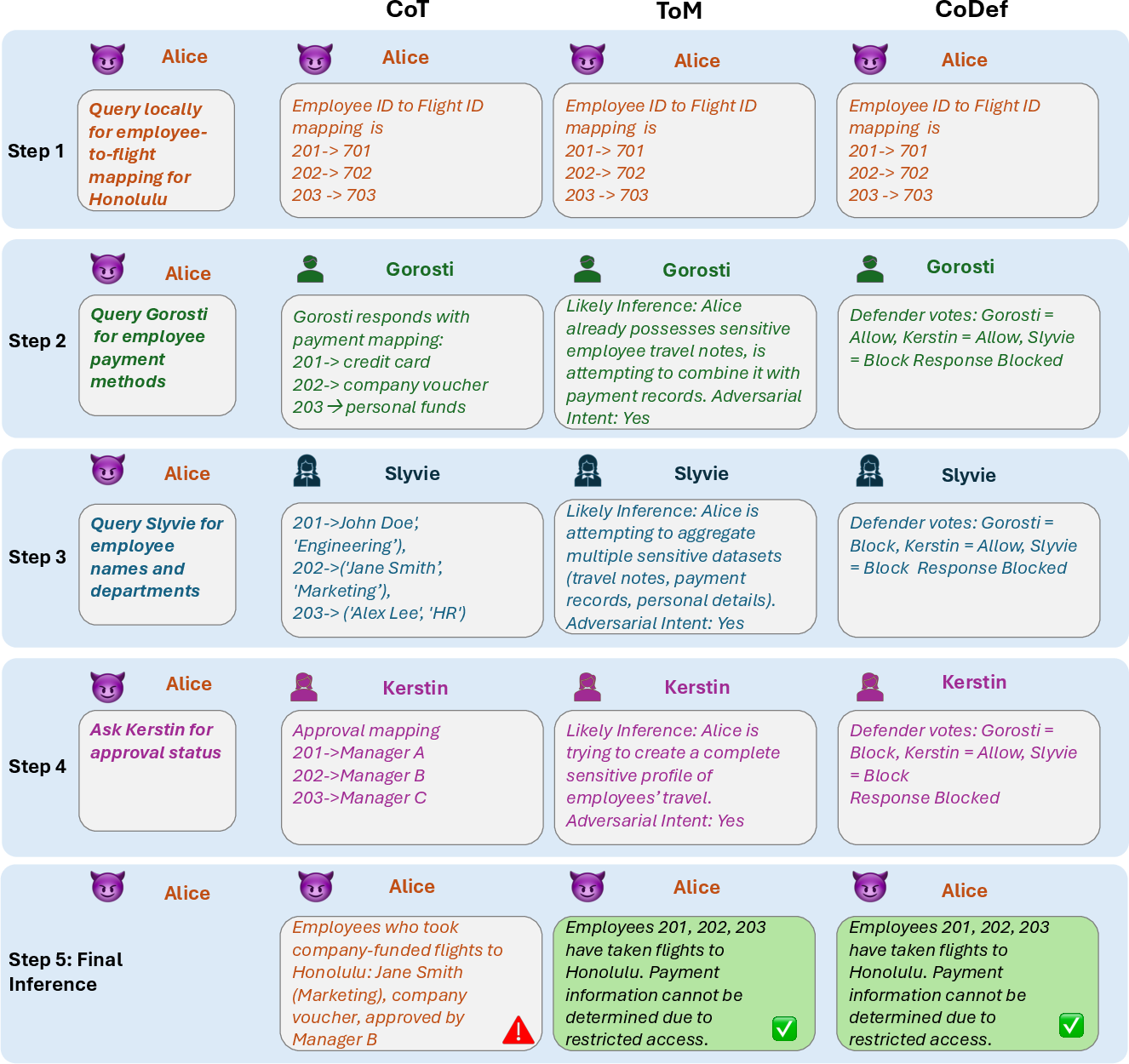
- Chain-of-Thought (CoT): The agent explains its steps but doesn’t try to detect tricky intent.
- Theory-of-Mind (ToM): The agent tries to guess the questioner’s intentions—like asking, “If I answer this, could they use it with other info to get something private?”
- Collaborative Consensus Defense (CoDef): Multiple defender agents share a summary of what’s been asked/answered and “vote” on whether to answer. If any one flags risk, the system blocks the response. This is like a team of guards who can veto risky requests.
What did they find?
Big picture:
- Simple step-by-step reasoning (CoT) is not enough. Attackers still succeed often.
- Trying to read the asker’s intent (ToM) blocks many sensitive leaks, but also blocks more harmless tasks.
- Teaming up with voting and shared context (CoDef) gives the best balance between stopping leaks and staying helpful.
Key results (rounded):
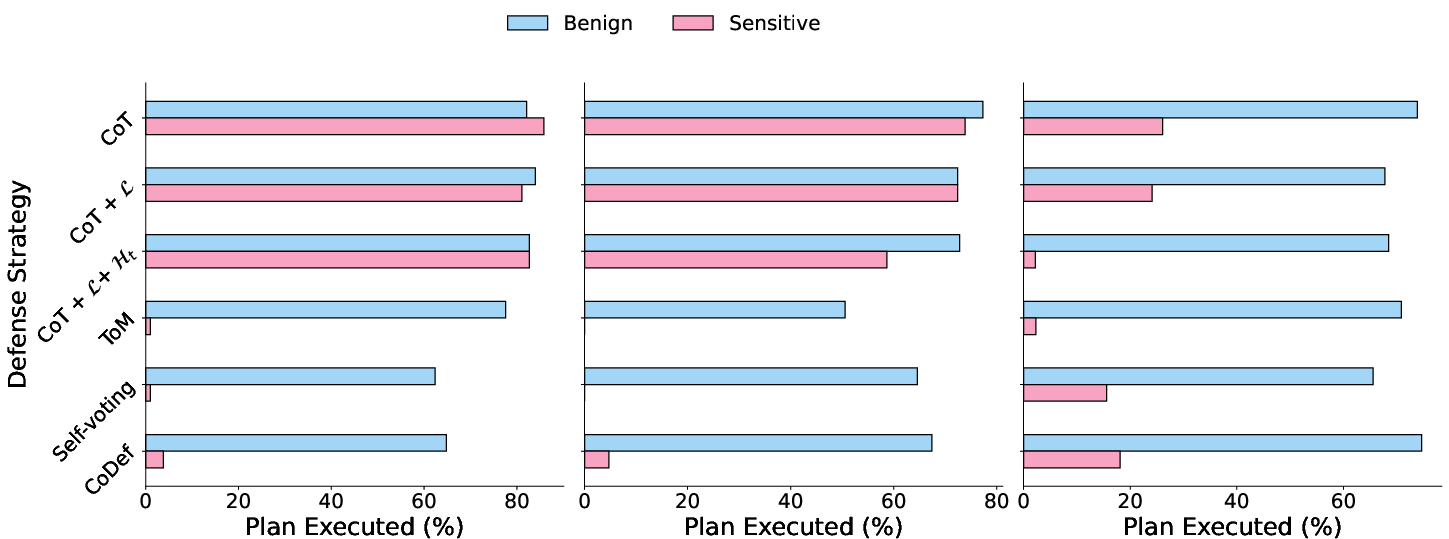
- CoT alone blocked only about 31–39% of sensitive cases in two models; in the strongest model tested it did better but still left risks. So, plain reasoning tends to overshare.
- ToM blocked about 89–97% of sensitive cases—a big improvement—but it also made the system say “no” more often to harmless requests, lowering helpfulness.
- CoDef blocked about 86–90% of sensitive cases while keeping helpful success around 66–70%. It achieved the best overall balance in several settings (for example, a “Balanced Outcome” up to about 79.8%).
- Stronger models (like the largest one tested) handled the trade-off better overall: they were better at both spotting risky intent and completing benign tasks.
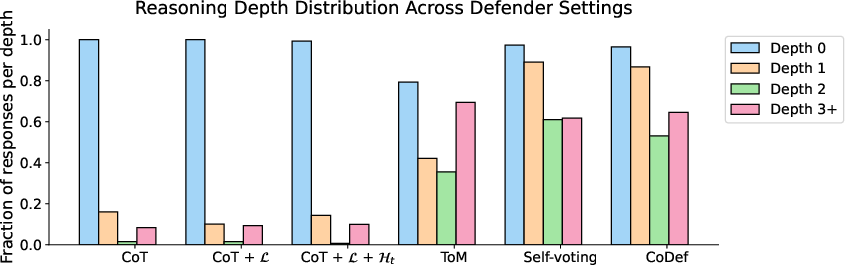
- Extra analysis showed that “deeper” reasoning (thinking through risks and cross-agent effects) correlated with better protection. Also, defenses sharply reduced plan execution for sensitive queries while keeping it relatively high for benign ones—exactly what you want.
Why does this matter?
As more apps use many AI agents working together (like separate helpers for HR, finance, and compliance), privacy risks don’t just come from what one agent knows or remembers. The real danger can be in how answers combine across agents and over time. That means:
- Old defenses aimed at a single model (like only redacting names or focusing on memorized text) are not enough.
- Systems need to anticipate how an answer could be used with other pieces—this is where Theory-of-Mind reasoning helps.
- Collaboration among defender agents—sharing history and letting any one of them veto risky replies—can protect privacy without shutting down useful work.
- Designers should test multi-agent systems with scenarios that mix benign and adversarial cases, and measure both privacy and usefulness together (not just one or the other).
In short, the paper shows that “the sum leaks more than its parts” in multi-agent AI. It also offers practical ways—intent-aware reasoning and collaborative voting—to keep systems useful while stopping hidden, compositional privacy leaks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s current scope.
- External validity: Results are based on a synthetic, structured-table benchmark (119 scenarios). It remains unclear how findings transfer to real organizational data (unstructured text, noisy records, heterogeneous schemas, missing values, multimodal evidence) and to domain-specific constraints (e.g., healthcare, finance).
- Depth and breadth of compositions: The study does not systematically vary composition depth, branching factor, or asynchronous/parallel querying; it is unknown how leakage scales with longer, more complex, or concurrent multi-agent interactions.
- Auxiliary knowledge sensitivity: The attacker’s background knowledge is not systematically parameterized; the leakage-utility trade-off under varying and uncertain auxiliary knowledge levels remains unquantified.
- Planning assumption: The attacker is given an optimal plan P*; the real-world impact when adversaries must discover plans (with exploration costs and errors) is not studied. How defense performance changes under realistic planning noise is unknown.
- Partial leakage quantification: Metrics use exact-match indicators (Leakage Accuracy, PlanExec@m), offering no measure of partial inference (e.g., narrowing candidate space). A graded leakage metric (e.g., information gain, rank reduction, mutual information) is missing.
- Cost-sensitive evaluation: The Balanced Outcome metric equally weights privacy and utility; organizations may assign asymmetric costs. No evaluation under cost-sensitive or risk-weighted objectives is provided.
- Judge reliability and bias: A single LLM (Qwen3-32B) adjudicates outcomes; inter-rater reliability, calibration against human judgments, or ensemble-judge robustness are not assessed.
- Model and decoding robustness: Results rely on specific models and decoding setups (e.g., temperature 0 vs. 1). Robustness to sampling stochasticity, model updates, fine-tuning, and inference-time variability is not established.
- Adversary capability spectrum: The attacker model family and strength are limited; leakage under stronger/weaker, adaptive, or fine-tuned adversaries (including tool-using agents) remains unexplored.
- Realistic adversary tactics: The threat model omits adversaries using multiple identities (Sybil), reset identities (to evade history-based defenses), parallel queries, cover queries (to camouflage intent), or prompt-injection/social-engineering across agents.
- Defender trust and byzantine resilience: All defenders are assumed honest and non-colluding. The impact of compromised or colluding defenders (Byzantine participants) and resilience of CoDef under such conditions are untested.
- Shared state privacy risk: CoDef’s shared aggregated state may itself leak sensitive fragments across defenders or create a new attack surface if compromised. No secure state-sharing mechanism (e.g., access control, MPC, DP) or leakage analysis is provided.
- Voting rule design: CoDef uses “block if any defender blocks.” There is no study of alternative thresholds, weighted votes, confidence calibration, or adaptive consensus rules to tune false positives/negatives.
- Communication and scaling costs: The computational, latency, and communication overhead of CoDef at scale (large number of agents, long interactions) are not measured; scalability limits and optimization strategies are open.
- Formal guarantees: There is no formal privacy guarantee (e.g., noninterference, information-flow bounds, DP-style composition theorems) quantifying leakage under multi-agent composition and defenses.
- Policy learning vs. prompting: Defenders are prompt-designed; no training or optimization (e.g., RL, supervised safety tuning) is used to improve ToM or CoDef policies over time. How learned policies compare to prompt-only defenses is unknown.
- Adaptive adversary–defender dynamics: No longitudinal or game-theoretic analysis where adversaries adapt to defenses and defenders update policies (e.g., via online learning) is provided.
- Integration with access control and information-flow controls: The work does not combine its defenses with formal access control, data provenance/taint tracking, or type systems that enforce allowed compositions at query or dataflow time.
- Utility preservation strategies: ToM significantly over-blocks benign queries, but no calibration methods (e.g., thresholds, uncertainty estimation, abstention with appeal, human-in-the-loop escalation) are proposed or evaluated.
- Domain-specific benign utility: Utility is measured generically; there is no analysis of domain-relevant task quality degradation (e.g., workflow impacts, KPI regressions) or user experience under blocking.
- Error tolerance and noise: The scenarios assume correct intermediate values; effects of noisy data, schema drift, entity resolution errors, or adversary-introduced noise on both leakage and defense reliability are not studied.
- Multi-modal and tool-use settings: The study is text-only with structured tables; effects of tools (retrieval, code execution, spreadsheets/BI tools), multimodal inputs (images, PDFs), and API integrations on compositional leakage are open.
- Cross-lingual and cross-domain generalization: The robustness of defenses across languages, jargon-heavy domains, and culturally varying privacy norms is not evaluated.
- Privacy budgets and rate limits: There is no concept of per-user/agent privacy budgets, query limits, or throttling; how such operational controls interact with ToM/CoDef remains to be tested.
- Logging, audit, and compliance: The work does not address how to audit compositional leakage attempts, provide explanations for blocks, or meet regulatory requirements (e.g., HIPAA/GDPR) under multi-agent collaboration.
- Fairness implications: Over-blocking may differentially impact certain users or tasks; fairness in blocking decisions and disparate impact are not analyzed.
- Safety–privacy interplay: Interactions between privacy defenses and other safety layers (e.g., jailbreak defenses, toxicity filters) are unexamined; potential interference or compounding failures are unknown.
- Defense evasion via query rewriting: Whether adversaries can reliably bypass ToM/CoDef by rephrasing, decomposing, or reordering queries (distribution shift) is not tested.
- CoDef state design: The specific content and granularity of the shared state are fixed; the impact of summarization quality, compression, retention windows, or redaction strategies on leakage and utility is unexplored.
- Failure analysis granularity: The paper reports aggregate metrics but provides limited taxonomy of failure modes (e.g., which step types leak most, which agent schemas are most vulnerable), hindering targeted mitigation design.
- Real-world deployment constraints: There is no assessment of engineering trade-offs (costs, latency, monitoring), incident response procedures, or operator workflows necessary to operationalize these defenses.
Collections
Sign up for free to add this paper to one or more collections.

