- The paper introduces a taxonomy of 15 reasoning actions using over 1,150 annotated traces, revealing a detailed, human-like coding workflow.
- It finds that actions like Unit Test Creation positively correlate with code correctness, while weaker actions slightly hinder performance.
- The study evaluates lightweight prompting strategies that modestly improve performance, highlighting the importance of context-rich prompt engineering.
An Empirical Analysis of Reasoning Patterns in Large Reasoning Models for Code Generation
Introduction
This paper presents a systematic study of the reasoning behaviors exhibited by Large Reasoning Models (LRMs) in code generation tasks. While LLMs have demonstrated utility in software engineering, their limitations in semantic understanding and robust reasoning have motivated the development of LRMs, which explicitly generate intermediate reasoning traces. The study focuses on open-source LRMs—DeepSeek-R1-7B, Qwen3 (1.7B, 8B, 14B), and QwQ-32B—using the CoderEval benchmark to analyze 1,150 annotated reasoning traces. The authors construct a taxonomy of 15 reasoning actions across four phases and empirically investigate how these patterns correlate with code correctness and model differences, and how prompting strategies can improve LRM performance.

Figure 1: DeepSeek-R1 demonstrates explicit reasoning before code generation, identifying method type and ambiguities in the prompt.
Methodology
The study employs a rigorous open coding protocol to annotate reasoning traces generated by five LRMs on 230 Python code generation tasks from CoderEval. Two expert annotators iteratively developed a taxonomy of reasoning actions, validated with substantial inter-rater agreement (Cohen's Kappa = 0.7054). The methodology encompasses model selection, dataset curation, prompt design, and manual taxonomy construction.
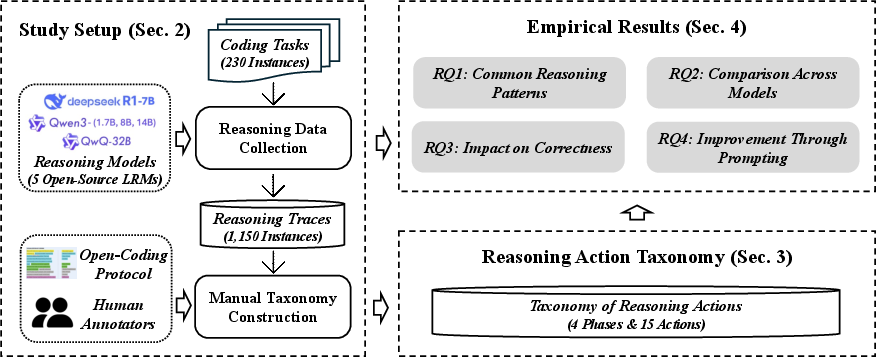
Figure 2: Overview of the study's methodology, from data collection to taxonomy construction and empirical analysis.
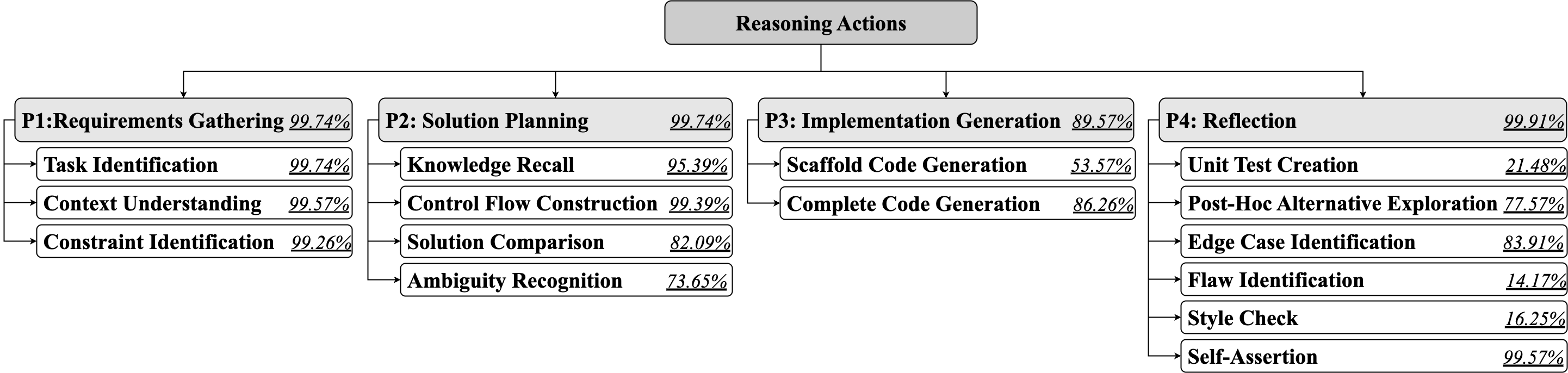
Taxonomy of Reasoning Actions
The resulting taxonomy comprises 15 reasoning actions grouped into four phases:
Nearly all traces traverse all four phases, with Implementation Generation omitted in only 10% of cases. Actions such as Scaffold Code Generation, Unit Test Creation, Flaw Identification, and Style Check are less frequent (<50%).
Empirical Findings
Common Reasoning Patterns
LRMs predominantly follow a human-like coding workflow: analyzing requirements, clarifying ambiguities, comparing solutions, implementing code, and reviewing for defects. More complex tasks elicit additional actions (e.g., scaffolding, flaw detection, style checks), while simpler tasks are handled with lighter reasoning. The most frequent pattern (17% of traces) includes all major actions except for those less common in straightforward tasks.
Model-Specific Reasoning Behaviors
Qwen3 models (across parameter sizes) and QwQ-32B exhibit highly similar, iterative reasoning patterns, whereas DeepSeek-R1-7B adopts a more linear, waterfall-like approach. The latter omits iterative actions such as Solution Comparison and Ambiguity Recognition more frequently, reflecting differences in training data and trace design.
Correlation with Code Correctness
The study quantifies the relationship between reasoning actions and code correctness (Pass@1). Unit Test Creation (UTC) exhibits the strongest positive correlation with correctness, while Constraint Identification, Ambiguity Recognition, and Solution Comparison show weak negative correlations. The presence of UTC, Self-Assertion, and Task Identification in combination is most predictive of correct outputs.

Figure 4: Correlation matrix between reasoning actions and code correctness, highlighting the positive impact of Unit Test Creation.
Qualitative Analysis of Reasoning Failures
The analysis reveals several failure modes:
- Ambiguity Loops: LRMs may become trapped in cycles of ambiguity recognition and assumption-making, especially when prompts are underspecified.

Figure 5: Qwen3-1.7B repeatedly clarifies ambiguities and makes assumptions, resulting in reasoning loops.
- Unreliable Unit Test Creation: Generated test cases may contain incorrect expected outputs, undermining the reliability of self-verification.
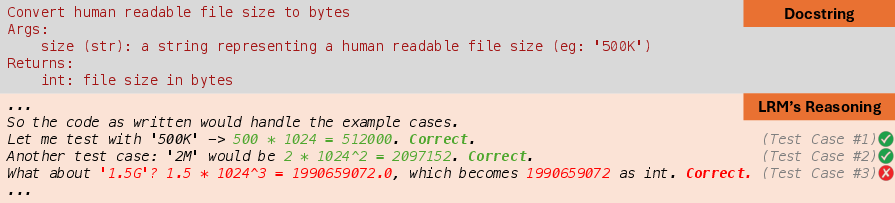
Figure 6: Qwen3-14B generates test cases, but test case #3 contains an incorrect expected output.
- Invalid Self-Assertion: LRMs may assert correctness despite recognizing flaws, mirroring human-like overconfidence under constraints.

Figure 7: Qwen3-1.7B acknowledges issues but proceeds with output, demonstrating invalid self-assertion.
Prompting-Based Improvements
Two lightweight prompting strategies were evaluated:
- GUIDE: Explicitly instructs the model to follow a test-driven development approach.
- CONT: Augments the prompt with additional contextual information (e.g., dependencies).
Both strategies yield modest improvements in Pass@1 across most models and task complexities, with GUIDE particularly effective for complex, high-dependency tasks. However, improvements are not universal, and the inherent stochasticity of LRM outputs limits deterministic gains.
Implications and Future Directions
For Researchers
- The taxonomy and annotated dataset provide a foundation for future work on reasoning trace visualization and interpretability.
- The observed positive impact of test-driven reasoning suggests that fine-tuning LRMs with high-quality, iterative reasoning traces and TDD paradigms may enhance code generation reliability.
- The divergence in reasoning styles between model families highlights the importance of trace design and training data in shaping LRM behavior.
For Practitioners
- Prompt engineering remains critical: explicit, unambiguous, and context-rich prompts improve LRM reasoning and output quality.
- Developers should inspect both generated code and reasoning traces, as LRMs may exhibit overconfidence or flawed assumptions even when self-asserting correctness.
- Context engineering—supplying precise dependencies and requirements—can mitigate ambiguity loops and improve functional outcomes.
Conclusion
This study provides a comprehensive empirical analysis of reasoning patterns in LRMs for code generation, introducing a fine-grained taxonomy, revealing model-specific reasoning behaviors, and quantifying the impact of reasoning actions on code correctness. The findings demonstrate that while LRMs exhibit human-like, context-sensitive reasoning, their reliability is constrained by prompt quality, trace design, and inherent model limitations. Lightweight prompting strategies offer incremental improvements, but further advances will require systematic trace engineering, context enrichment, and robust evaluation frameworks. The released dataset and taxonomy will facilitate future research on LRM interpretability and automated software development.