CoVariance Filters and Neural Networks over Hilbert Spaces
(2509.13178v1)
Published 16 Sep 2025 in cs.LG and eess.SP
Abstract: CoVariance Neural Networks (VNNs) perform graph convolutions on the empirical covariance matrix of signals defined over finite-dimensional Hilbert spaces, motivated by robustness and transferability properties. Yet, little is known about how these arguments extend to infinite-dimensional Hilbert spaces. In this work, we take a first step by introducing a novel convolutional learning framework for signals defined over infinite-dimensional Hilbert spaces, centered on the (empirical) covariance operator. We constructively define Hilbert coVariance Filters (HVFs) and design Hilbert coVariance Networks (HVNs) as stacks of HVF filterbanks with nonlinear activations. We propose a principled discretization procedure, and we prove that empirical HVFs can recover the Functional PCA (FPCA) of the filtered signals. We then describe the versatility of our framework with examples ranging from multivariate real-valued functions to reproducing kernel Hilbert spaces. Finally, we validate HVNs on both synthetic and real-world time-series classification tasks, showing robust performance compared to MLP and FPCA-based classifiers.
Summary
The paper introduces a framework that extends covariance-based neural networks to infinite-dimensional Hilbert spaces, enabling recovery of FPCA scores.
It develops Hilbert coVariance Filters using both spectral and polynomial methods, ensuring scalability without requiring explicit eigendecomposition.
Empirical evaluations on synthetic and ECG time-series data demonstrate improved robustness and sample efficiency compared to MLP and FPCA baselines.
CoVariance Filters and Neural Networks over Hilbert Spaces: A Technical Analysis
Introduction and Motivation
This work addresses the extension of covariance-based neural architectures from finite-dimensional to infinite-dimensional Hilbert spaces. Covariance Neural Networks (VNNs) have demonstrated robust performance and transferability by leveraging the empirical covariance matrix as a graph shift operator, effectively combining the representational power of PCA with the stability of GNNs. However, their applicability has been limited to finite-dimensional settings. The paper introduces a principled framework for convolutional learning over general Hilbert spaces, centered on the covariance operator, and develops Hilbert coVariance Filters (HVFs) and Hilbert coVariance Networks (HVNs). The framework is made practical via a discretization procedure, and its theoretical properties are established, including the recovery of Functional PCA (FPCA) through empirical HVFs.
Theoretical Framework
Covariance Operator and Spectral Domain
Given a separable Hilbert space H and a square-integrable H-valued random variable X, the covariance operator C:H→H is defined as
Cv=E[(X−μ)⟨X−μ,v⟩],
where μ=E[X]. C is compact, self-adjoint, and trace-class, admitting a spectral decomposition
Cv=ℓ≥1∑λℓ⟨v,ϕℓ⟩ϕℓ,
with nonnegative eigenvalues λℓ and orthonormal eigenfunctions ϕℓ.
The Hilbert coVariance Fourier Transform (HVFT) of x∈H is defined as x[ℓ]=⟨x,ϕℓ⟩, which is equivalent to the FPCA transform up to recentering. This spectral domain provides a natural basis for defining convolutional operations and learning architectures.
Hilbert coVariance Filters (HVFs)
Two classes of HVFs are introduced:
Spectral HVFs: For a bounded Borel function h, the filter is
h(C)x=ℓ=1∑∞h(λℓ)⟨x,ϕℓ⟩ϕℓ+h(0)x⊥,
where x⊥ is the projection onto ker(C). Filtering is pointwise in the HVFT domain: g[ℓ]=h(λℓ)x[ℓ].
Spatial (Polynomial) HVFs: For order J and parameters w0,…,wJ,
h(C)=∑j=0JwjCj.
The frequency response is h(λ)=∑k=0Jwkλk. This avoids explicit eigendecomposition and is scalable.
Hilbert coVariance Networks (HVNs)
HVNs are constructed as layered architectures stacking banks of HVFs and nonlinear activations. The t-th layer propagates as
xt+1u=σ(i=1∑Fth(C)tu,ixti),
where σ is a nonlinear operator on H. The architecture generalizes VNNs and GNNs to infinite-dimensional settings.
Discretization and Implementation
Empirical Covariance Operator
Given n i.i.d. samples x1,…,xn∈H, the empirical covariance operator is
C^nv=n1i=1∑n⟨xi−xˉ,v⟩(xi−xˉ),
with xˉ=n−1∑i=1nxi. C^n is finite-rank, and its spectral decomposition enables empirical HVFs.
Discretization Operator
A bounded discretization operator Sm:H→Rm is defined via bounded linear functionals, yielding discretized samples xi(m)=Smxi. The empirical covariance matrix of discretized signals is
C^n(m)=n1i=1∑n(xi(m)−x(m))(xi(m)−x(m))⊤.
It is shown that C^n(m)=SmC^nSm∗, ensuring commutativity between filtering and discretization under orthonormal sampling.
Discrete HVFs and HVNs
Discrete HVFs and HVNs are implemented by replacing C with C^n(m) and signals with their discretized versions. The layerwise propagation in matrix form is
Xt+1(m)=σ(j=0∑J(C^n(m))jXt(m)Wt,j),
where Wt,j are learnable parameters.
Theoretical Guarantees
A key result is that empirical polynomial HVFs can recover the empirical FPCA scores. For each distinct eigenvalue α of C^n, there exists a polynomial HVF hα such that
hα(C^n)x=Pαx,
where Pα is the orthogonal projector onto the eigenspace of α. This establishes a direct connection between HVFs and FPCA, generalizing the classical result that PCA scores are outputs of a bank of narrowband spectral filters.
Practical Use-Cases
The framework is applicable to a variety of settings:
Functional Data (e.g., time series):H=L2([0,1],Rd), with discretization via bin-averaging.
Infinite Sequences:H=ℓ2(N), with canonical projection.
Nonlinearities are typically pointwise Lipschitz functions, ensuring stability and well-posedness.
Empirical Evaluation
The paper presents experiments on both synthetic and real-world time-series classification tasks.
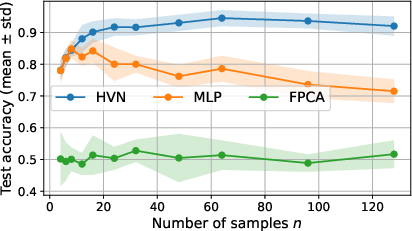
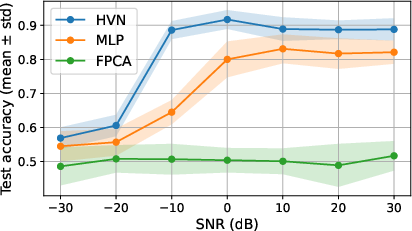
Synthetic Task: Binary classification of multivariate time-series bags, where class information is encoded in cross-channel covariance. HVNs outperform MLPs (which only access first-order information) and FPCA-based classifiers (which suffer from coordinate drift and instability).
Figure 1: Test accuracy versus number of samples, demonstrating the superior sample efficiency and robustness of HVNs compared to MLP and FPCA baselines.
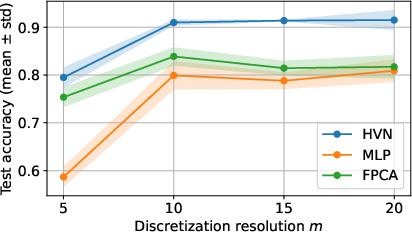
ECG5000 Dataset: Classification of ECG time-series with varying discretization resolution. HVNs consistently outperform both MLP and FPCA, especially as the discretization becomes finer, highlighting the benefit of robust covariance-aware learning.
Implementation Considerations
Computational Complexity: Spatial HVFs avoid eigendecomposition, making them scalable to high-dimensional discretizations.
Stability: The use of the covariance operator as a shift ensures transferability and robustness to stochastic perturbations in the empirical covariance, especially in high-dimension/low-sample regimes.
Nonlinearity Choice: Pointwise Lipschitz activations are recommended for L2 spaces to preserve integrability and stability.
Discretization: The choice of discretization operator (e.g., bin-averaging, canonical projection, point evaluation) should be tailored to the underlying Hilbert space and application domain.
Implications and Future Directions
The proposed framework generalizes covariance-based neural architectures to infinite-dimensional settings, enabling principled learning from functional, sequential, or kernelized data. The theoretical connection to FPCA provides interpretability and guarantees on representational power. The empirical results demonstrate robust performance and transferability, particularly in scenarios where discriminative information is encoded in second-order statistics.
Future work should address:
Convergence Analysis: Studying the convergence of discrete HVFs/HVNs to their infinite-dimensional counterparts as discretization resolution increases.
Transferability: Formal analysis of the transferability properties of HVNs across domains and tasks.
Extension to Other Operators: Generalization to other classes of operators (e.g., covariance density operators) for enhanced robustness and control over stability-discriminability trade-offs.
Conclusion
This paper establishes a rigorous and practical framework for convolutional learning over Hilbert spaces via covariance operators, unifying and extending covariance-based neural architectures to infinite-dimensional domains. The approach is theoretically grounded, computationally tractable, and empirically validated, with broad applicability to functional data analysis, time-series modeling, and kernel methods. The results open new avenues for robust, interpretable, and transferable learning in high- and infinite-dimensional settings.