- The paper introduces a novel two-stage learning strategy combining universal pre-training and domain-adaptive fine-tuning to achieve attribute-aware sound representation.
- It employs an agglomerative hierarchical clustering pseudo-labeling method to uncover latent machine attributes from limited annotated data.
- Results on the DCASE 2025 dataset demonstrate state-of-the-art performance with improved parameter efficiency and robustness.
Improving Anomalous Sound Detection with Attribute-aware Representation from Domain-adaptive Pre-training
Introduction
The paper presents an innovative approach to Anomalous Sound Detection (ASD), an essential task for machine maintenance and safety protection, where the challenge often lies in the scarcity of annotated anomalous sound data. Traditionally, ASD is tackled as a Machine Attribute Classification (MAC) problem, leveraging only normal sound data. However, the lack of labeled machine attribute data poses a significant barrier, which the paper addresses through a novel methodology involving domain-adaptive pre-training and pseudo-labeling.
Methodology
Domain-adaptive Pre-training
The essence of the proposed method lies in its two-stage learning strategy. Initially, a universal model is pre-trained on a large-scale dataset such as AudioSet, focusing on generic audio characteristics. This stage is crucial as it prepares a robust foundation by learning universal audio representations. Subsequently, to mitigate domain mismatch issues and improve fine-grained representation learning, a domain-adaptive pre-training phase is conducted using multiple machine-specific sound datasets. This step allows the model to develop rich, attribute-aware audio embeddings critical for both the clustering process and downstream ASD task.
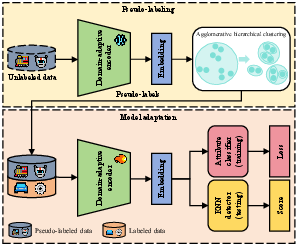
Figure 1: The overall framework of our proposed method.
Pseudo-labeling Strategy
The challenge of missing attribute labels is addressed through an agglomerative hierarchical clustering method, which assigns pseudo-attribute labels based on embeddings from the domain-adaptive model. This technique effectively discovers latent machine attributes by exploiting variances in the machine sounds that align with particular operational conditions, thus allowing the model to preserve important intra-class variations that are often lost in conventional approaches.


Figure 2: T-SNE Visualization of the embedding distribution of FT (left) and DAP (right) schemes. Different colors represent different real attributes of machine type Polisher in the source domain, such as (pow1, nA) and (pow3, nB). The pow (power) and n (noise) denote the Polisher's working power and background noise, and the characters after pow and n represent their specific attribute values.
Model Adaptation
In the final adaptation stage, the pre-trained model undergoes supervised fine-tuning on the ASD task, employing both the generated pseudo-attribute labels and any available ground-truth labels. This comprehensive fine-tuning step enables the transfer of learned representations to the specific requirements of the MAC task, culminating in a highly effective ASD system that excels in both attribute-rich and attribute-sparse settings.
Experimental Results
The proposed approach was rigorously evaluated on the DCASE 2025 ASD dataset, showcasing remarkable improvements over existing systems. By integrating domain-adaptive pre-training and pseudo-labeling, the method achieved state-of-the-art results, surpassing previous top-ranking systems in terms of both performance and parameter efficiency.
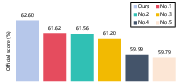
Figure 3: Comparison among our system and other SOTA models on the DCASE 2025 ASD evaluation dataset.
Conclusion
The research introduces a potent combination of domain-adaptive pre-training and hierarchical clustering for pseudo-labeling, enhancing the performance of ASD systems significantly. Through improved attribute representation and efficient model adaptation, the approach offers substantial advancements in detecting anomalous sounds under challenging conditions. As advancements in unsupervised and self-supervised learning continue, this methodology sets a strong precedent for further exploration and optimization of ASD systems, paving the way for more resilient and nuanced models in industrial applications.

