- The paper introduces a novel ELO-inspired training method that overcomes hard negative mining limitations by leveraging pairwise ensemble annotations.
- It details a multi-stage pipeline using graph-theoretic heuristics to efficiently estimate Elo scores and optimize reranker performance.
- Empirical results show state-of-the-art accuracy across diverse IR tasks with improved efficiency and robust cross-domain generalization.
zELO: ELO-inspired Training Method for Rerankers and Embedding Models
Introduction
The zELO methodology presents a significant advancement in the training of rerankers and embedding models for information retrieval (IR). By leveraging the statistical equivalence between ranking tasks and the Thurstone model, zELO introduces a multi-stage pipeline that utilizes unsupervised data and pairwise preferences, ultimately producing state-of-the-art open-weight rerankers—zerank-1 and zerank-1-small. This approach systematically addresses the limitations of traditional hard negative mining and human annotation, offering robust generalization across domains and retrieval methods.
Motivation and Limitations of Hard Negative Mining
Traditional reranker training relies heavily on InfoNCE triplet loss and hard negative mining, where negatives are selected to be as relevant as possible. However, the paper demonstrates that increasing the intelligence of the hard negative miner eventually degrades student model performance. This is attributed to the fact that highly intelligent miners can select negatives that are genuinely more relevant than the human-annotated positives, leading to a fundamental limitation in the methodology.
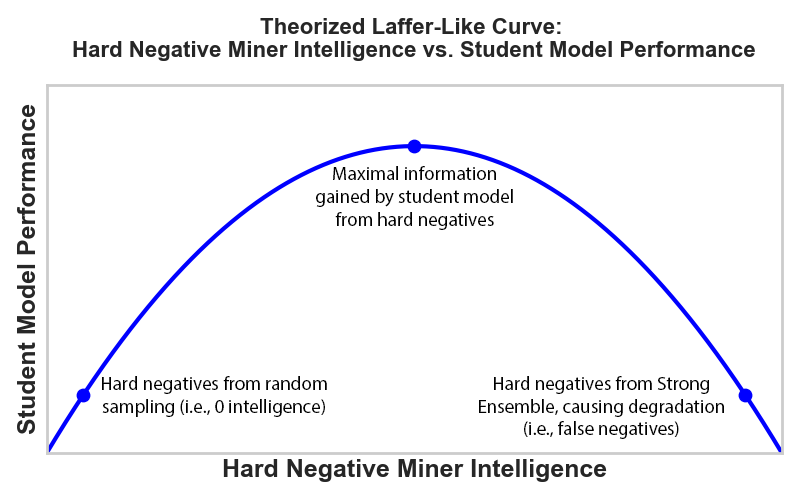
Figure 1: The proposed Laffer curve between hard negative miner intelligence and student model performance, illustrating diminishing returns and eventual degradation.
The observed Laffer curve indicates that the marginal benefit of hard negative mining diminishes and becomes negative as miner intelligence increases. This motivates the shift towards pairwise annotation and Elo-based scoring, which do not suffer from the same theoretical constraints.
The zELO Methodology
zELO formalizes reranking as a mapping from queries and documents to relevance scores, distinguishing between pointwise and pairwise rerankers. Pairwise preferences are collected from an ensemble of LLMs, and these are converted into absolute relevance scores using the Thurstone model, which assumes a normal distribution of noise in document comparison.
Sparse Matrix Subsampling and Graph Construction
To efficiently estimate Elo scores from sparse pairwise comparisons, zELO employs graph-theoretic heuristics:
- Connectedness: Ensures global Elo ranking.
- Uniform Degree: Stabilizes Elo estimates.
- Low Diameter: Reduces ranking uncertainty.
The optimal graph structure is achieved by overlaying multiple random cycles, resulting in a k-regular graph with desirable properties for Elo estimation.
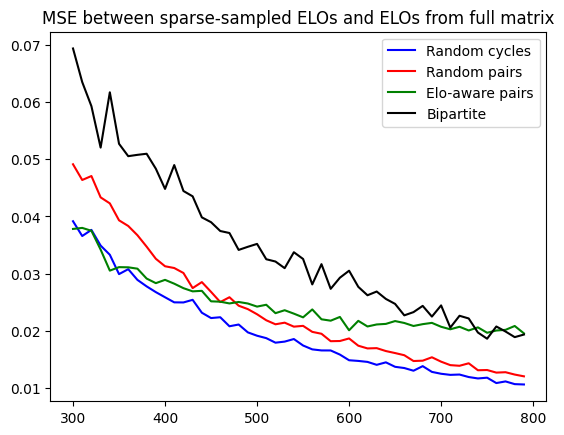
Figure 2: MSE between predicted Elos and actual Elos for various sampling methods, demonstrating rapid convergence with random cycles and bipartite graphs.
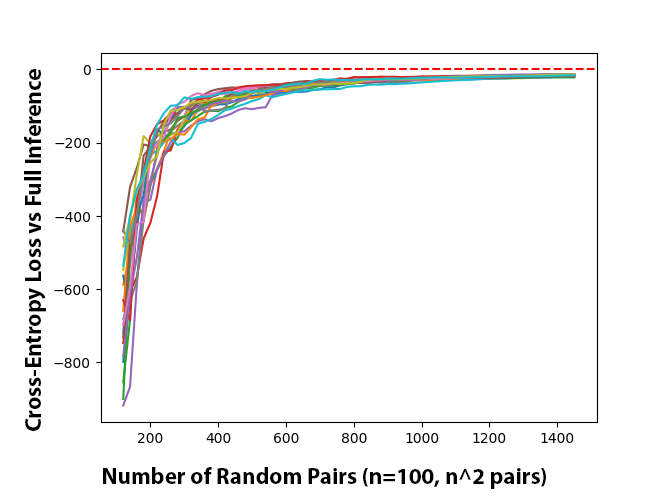
Figure 3: Convergence plots for random sampling, showing that Elo estimates stabilize with only ~1.2k/10k pairs sampled.
Ensemble Annotation and Synthetic Data Generation
Pairwise preferences are generated by prompting an ensemble of frontier LLMs, each providing a chain-of-thought justification and a final judgment. Scores are averaged and mapped to the [0,1] range. The ensemble annotation is shown to produce higher quality data than human annotators, with strong convergence properties.
Figure 4: Frequency of pairwise comparison models favoring documents on which the ensemble reaches consensus, indicating annotation reliability.
Supervised Fine-Tuning and RLHF Augmentation
The pointwise reranker is trained via supervised fine-tuning on the Elo scores derived from the pairwise matrix. To further improve performance, RLHF-style augmentation is performed by adding additional pairwise comparisons where the reranker fails to rank human-annotated top documents correctly, thus recapturing high-signal human annotation without relying on it as ground truth.
Empirical Results
Cross-Domain and Retrieval Method Performance
zerank-1 and zerank-1-small consistently outperform commercial rerankers and larger LLM-based rerankers across multiple domains (finance, legal, code, STEM, medicine) and retrieval methods (BM25, embedding, hybrid). Notably, zerank-1-small maintains much of the performance of zerank-1 despite being less than half the size.
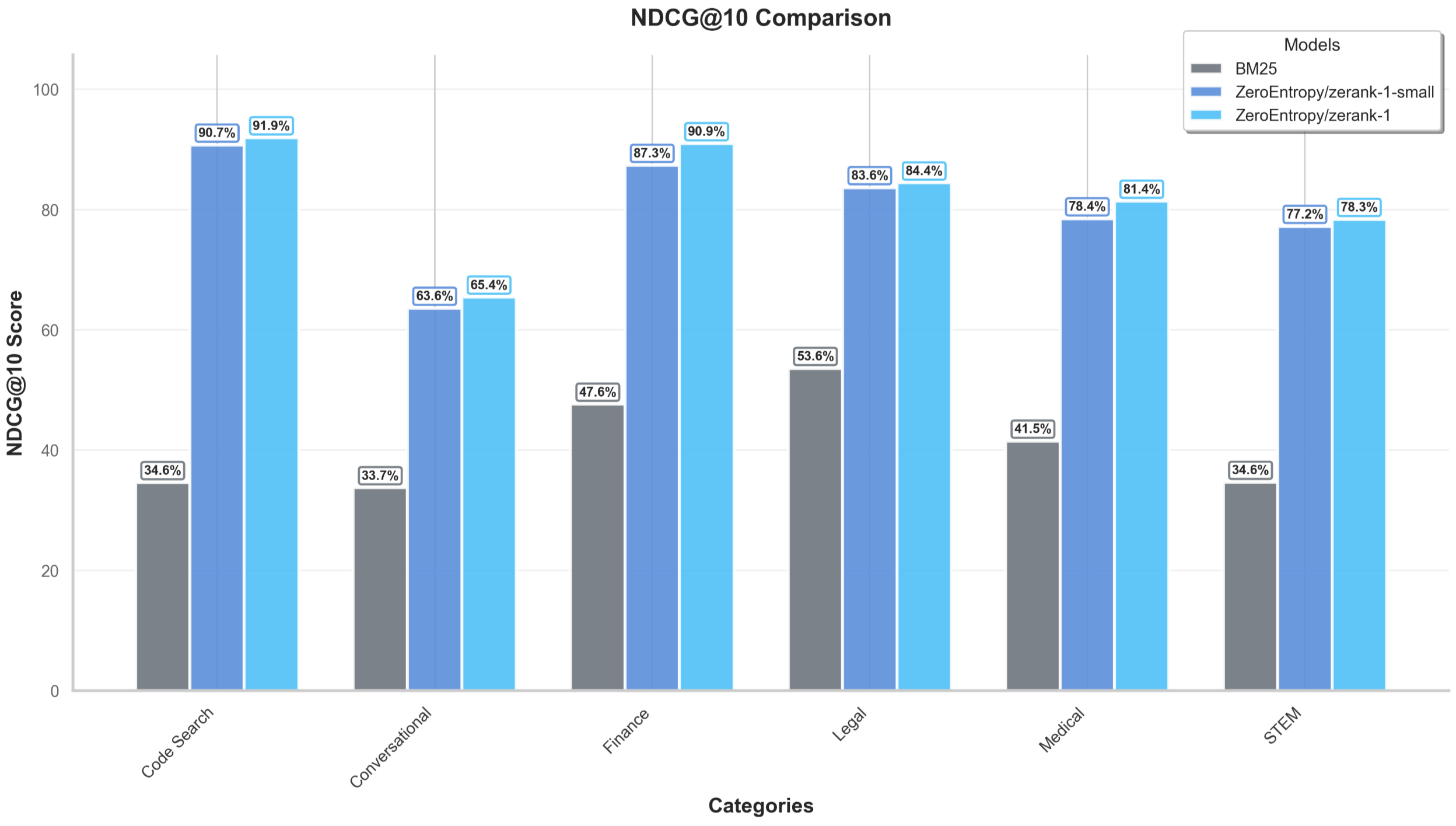
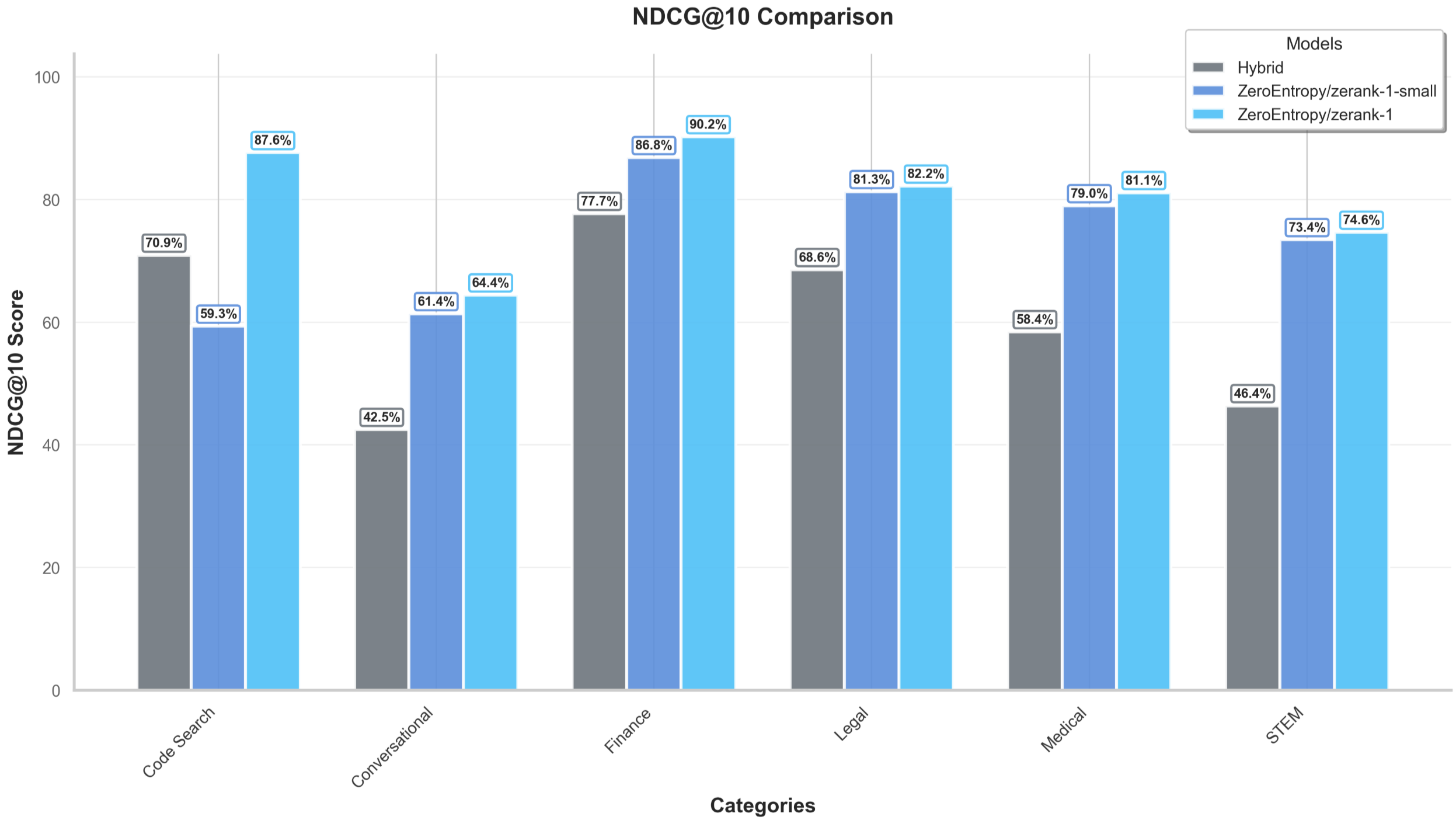
Figure 5: NDCG@10 comparison of BM25 alone versus zerank-1 and zerank-1-small, for both BM25 and hybrid search pipelines.
Latency and Efficiency
The rerankers achieve superior NDCG@10 while maintaining competitive or superior latency compared to existing models, making them suitable for production deployment.
Generalization and Robustness
Both models generalize well to private customer datasets, indicating resistance to overfitting and wide applicability. The zELO method does not use any human annotations for training, yet achieves strong zero-shot performance on out-of-domain data.
Comparison with LLM-as-a-Reranker
Direct comparison with Gemini-v2.5-flash, using the same pairwise prompt, shows that the trained reranker dramatically outperforms the LLM-as-a-reranker approach.
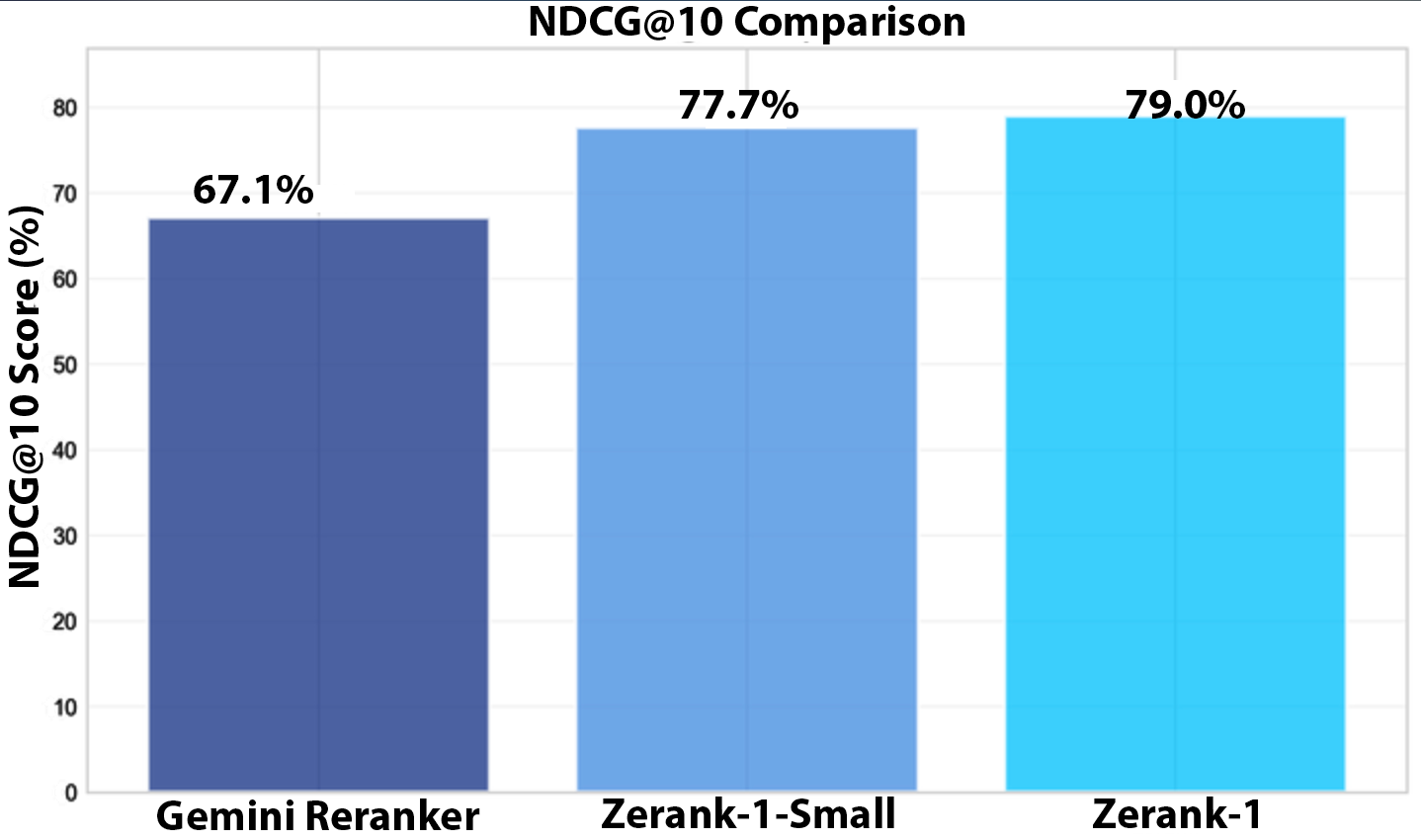
Figure 6: Performance comparison between zerank-1 and Gemini-v2.5-flash as rerankers, demonstrating the superiority of the trained model.
Theoretical and Practical Implications
The zELO pipeline demonstrates that reranker performance is fundamentally limited by the annotation and training methodology, not by model capacity. By shifting to pairwise ensemble annotation and Elo-based scoring, zELO removes the theoretical cap imposed by hard negative mining and InfoNCE, allowing student models to approach the accuracy of the teacher ensemble. The method is fully automated, scalable, and suitable for live production evaluation and personalized recommendation systems.
Future Directions
Potential future developments include:
- Systematic exploration of the Laffer curve with miner intelligence as the sole independent variable.
- Extension of the zELO pipeline to other ranking tasks beyond IR, such as recommendation and multi-modal retrieval.
- Further optimization of graph sampling strategies for even greater efficiency in Elo estimation.
- Integration with online learning and continual adaptation in production environments.
Conclusion
zELO introduces a mathematically principled, scalable, and empirically validated pipeline for training rerankers and embedding models. By leveraging pairwise ensemble annotation and Elo-inspired scoring, it overcomes the limitations of hard negative mining and human annotation, achieving state-of-the-art performance across domains and retrieval methods. The open-weight models zerank-1 and zerank-1-small set new benchmarks for reranking accuracy, efficiency, and generalization, with broad implications for the future of information retrieval and ranking systems.