- The paper introduces Fluid Benchmarking, a novel method that uses IRT and adaptive item selection to efficiently measure language model capabilities.
- It demonstrates reduced evaluation variance and improved validity by dynamically tailoring item difficulty to each model’s latent ability.
- The approach minimizes benchmark saturation and mislabeled items, ensuring robust evaluation even with small sample sizes.
Fluid Benchmarking: Adaptive Evaluation for LLMs
Introduction
"Fluid LLM Benchmarking" (2509.11106) addresses persistent challenges in LLM (LM) evaluation, including high computational cost, benchmark saturation, evaluation noise, and the misalignment between benchmark items and the intended capabilities being measured. The paper introduces Fluid Benchmarking, a methodology that leverages item response theory (IRT) and adaptive item selection, inspired by psychometrics and computerized adaptive testing, to dynamically tailor evaluation to the capability profile of each LM. This approach is shown to improve efficiency, validity, variance, and saturation of LM benchmarking, outperforming both random sampling and prior IRT-based static methods.
Methodological Framework
Benchmark Refinement and Evaluation Dimensions
The paper formalizes "benchmark refinement" as the joint optimization of (i) item selection and (ii) aggregation of item-level results into benchmark-level scores. Four key dimensions of evaluation quality are defined:
- Efficiency: Reducing the number of evaluation items without sacrificing informativeness.
- Validity: Ensuring benchmark scores predict LM behavior on related tasks.
- Variance: Minimizing evaluation noise, especially across training checkpoints.
- Saturation: Delaying the point at which benchmarks cease to differentiate between strong models.
Item Response Theory for LM Evaluation
Fluid Benchmarking employs a two-parameter logistic (2PL) IRT model, where each item is parameterized by difficulty (bj) and discrimination (aj), and each LM is assigned a latent ability parameter (θi). The probability of a correct response is modeled as:
p(uij=1)=logistic(aj(θi−bj))
This enables aggregation of item-level scores into a latent ability estimate, rather than simple accuracy, providing a more nuanced and robust measure of LM capability.
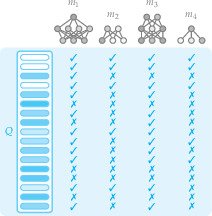
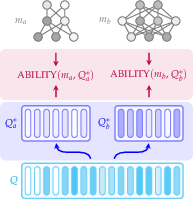
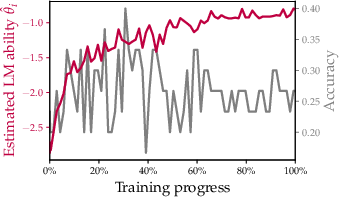
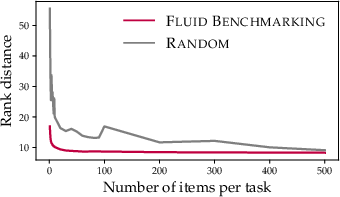
Figure 1: (a) IRT model training on LM evaluation results; (b) Fluid Benchmarking dynamically selects items and evaluates in ability space; (c) Reduced variance in training curves; (d) Improved validity via lower rank distance.
The informativeness of each item is quantified by its Fisher information with respect to the current ability estimate. At each evaluation step, the item with maximal Fisher information is selected, dynamically adapting the evaluation set to the LM's evolving capability. This process is formalized as:
Qi∗(t)=Qi∗(t−1)∪{argqj∈Q∖Qi∗(t−1)maxI(θ^i,aj,bj)}
where I(θ,aj,bj) is the Fisher information for item j at ability θ.
Experimental Evaluation
Setup
Experiments are conducted on six LMs (Amber-6.7B, OLMo1-7B, OLMo2-7B, Pythia-6.9B, Pythia-2.8B, K2-65B) across six benchmarks (ARC Challenge, GSM8K, HellaSwag, MMLU, TruthfulQA, WinoGrande), using 2,802 checkpoint-benchmark combinations and over 13 million item-level evaluations. IRT models are trained on 102 LMs from the Open LLM Leaderboard, excluding the test LMs.
Results: Efficiency, Validity, Variance, Saturation
Fluid Benchmarking consistently outperforms random sampling and prior IRT-based static methods across all evaluation dimensions:
- Validity: Fluid Benchmarking achieves lower mean rank distance between predicted and true ranks, nearly halving the error of strong baselines.
- Variance: Step-to-step variance in training curves is substantially reduced, especially for small evaluation sets.
- Saturation: Training curves in ability space remain monotonic and informative even as accuracy saturates, indicating delayed benchmark saturation.
- Efficiency: Superior performance is maintained even with as few as 10 evaluation items, with the largest gains at small sample sizes.
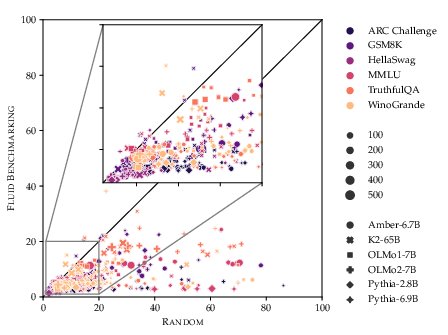
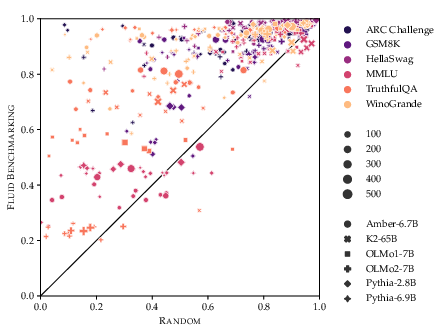
Figure 2: (a) Fluid Benchmarking yields lower variance in training curves; (b) Higher monotonicity (saturation) compared to random sampling across benchmarks and LMs.
Dynamic Adaptation and Avoidance of Mislabeled Items
Fluid Benchmarking dynamically shifts the difficulty of selected items as the LM improves during pretraining, as visualized in the selection trajectory for OLMo1-7B on HellaSwag.
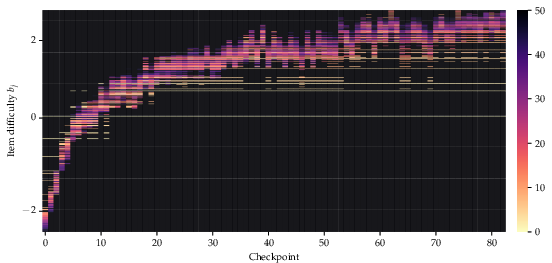
Figure 3: Adaptive item selection in Fluid Benchmarking for OLMo1-7B on HellaSwag; item difficulty increases as the LM improves.
The method also avoids problematic items: the average number of mislabeled items in a 100-item evaluation is reduced from 0.75 (random) to 0.01 (Fluid Benchmarking), nearly two orders of magnitude lower.
Mitigating Benchmark Saturation
Fluid Benchmarking maintains a learning signal in ability space even after accuracy saturates, as shown in the final stages of OLMo2-7B training on HellaSwag.
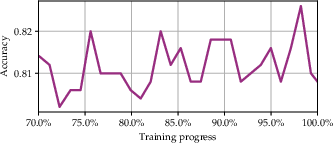
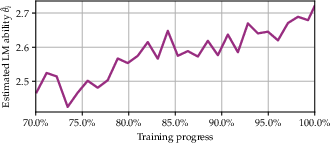
Figure 4: (a) Random sampling shows saturated accuracy; (b) Fluid Benchmarking in ability space continues to reflect learning progress.
Dynamic Stopping
The adaptive framework supports dynamic stopping based on the standard error of the ability estimate, allowing the number of evaluation items to be tailored to the required precision at each checkpoint, further improving efficiency.
Theoretical and Practical Implications
Disentangling IRT and Adaptive Selection
The analysis demonstrates that IRT-based aggregation primarily improves validity, while dynamic item selection is critical for reducing variance. Prior IRT-based static methods have been shown to increase variance, but this is not intrinsic to IRT; rather, it is a consequence of failing to adaptively select items. Fluid Benchmarking resolves this by fully leveraging the adaptive potential of IRT.
Generalization and Extensibility
The methodology is not limited to pretraining or English-language LMs. It is applicable to posttraining evaluation, multilingual settings, and other modalities (e.g., vision-LLMs), provided sufficient evaluation data for IRT model fitting. However, the utility of the approach depends on maintaining up-to-date IRT models as LM capabilities advance.
Limitations and Future Directions
- IRT Model Updating: As LMs surpass the capabilities of the models used to fit IRT parameters, the difficulty spectrum may become compressed at the upper end, necessitating regular retraining of IRT models with new evaluation data.
- Dynamic Benchmarks: The results support a shift from static to adaptive benchmarks as the standard for LM evaluation, with implications for leaderboard design and model selection in both research and deployment contexts.
- Integration with Other Evaluation Paradigms: Fluid Benchmarking can be combined with adversarial data collection, error analysis, and other forms of benchmark refinement to further enhance robustness and interpretability.
Conclusion
Fluid Benchmarking provides a principled, adaptive framework for LM evaluation, integrating IRT-based latent ability estimation with dynamic item selection. The approach yields improvements in efficiency, validity, variance, and saturation, and is robust to mislabeled items and benchmark saturation. The results support the adoption of adaptive, psychometric-inspired evaluation methodologies as a new standard in AI benchmarking, with broad applicability across tasks, languages, and modalities. Future work should focus on maintaining extensible, up-to-date IRT models and exploring integration with other evaluation paradigms to further advance the reliability and interpretability of LM assessment.