- The paper reveals significant performance disparities between smaller and larger LLMs in probabilistic reasoning.
- It employs a standardized prompt framework to assess tasks such as mode identification, MLE, and sample generation.
- Experimental results indicate superior sample generation by larger models, yet persistent issues with label sensitivity and context length.
"Reasoning Under Uncertainty: Exploring Probabilistic Reasoning Capabilities of LLMs" (2509.10739)
Introduction
The paper presents a comprehensive study of the probabilistic reasoning capabilities of LLMs. Despite their success in various NLP tasks, LLMs demonstrate inconsistent performance when required to perform probabilistic reasoning over explicit discrete probability distributions. This research investigates the capabilities of LLMs through tasks such as mode identification, maximum likelihood estimation (MLE), and sample generation. The findings reveal significant performance disparities between smaller and larger models and expose persistent limitations such as sensitivity to notation variations and context length increases.
Evaluation Framework
Probabilistic Model
The study considers a probabilistic setup where categorical random variables are defined as X=(X1,X2,…,XN) with joint outcomes. Observations drawn from a distribution are provided either as empirical frequencies or raw samples. The LLMs are tasked with performing reasoning over these structured distributions.
Prompt Structure
A standardized prompt format is employed, as shown in (Figure 1). Each prompt consists of random variable definitions, observed samples or frequencies, and specific task queries with formatting instructions. This framework enables consistent assessment across diverse probabilistic tasks.
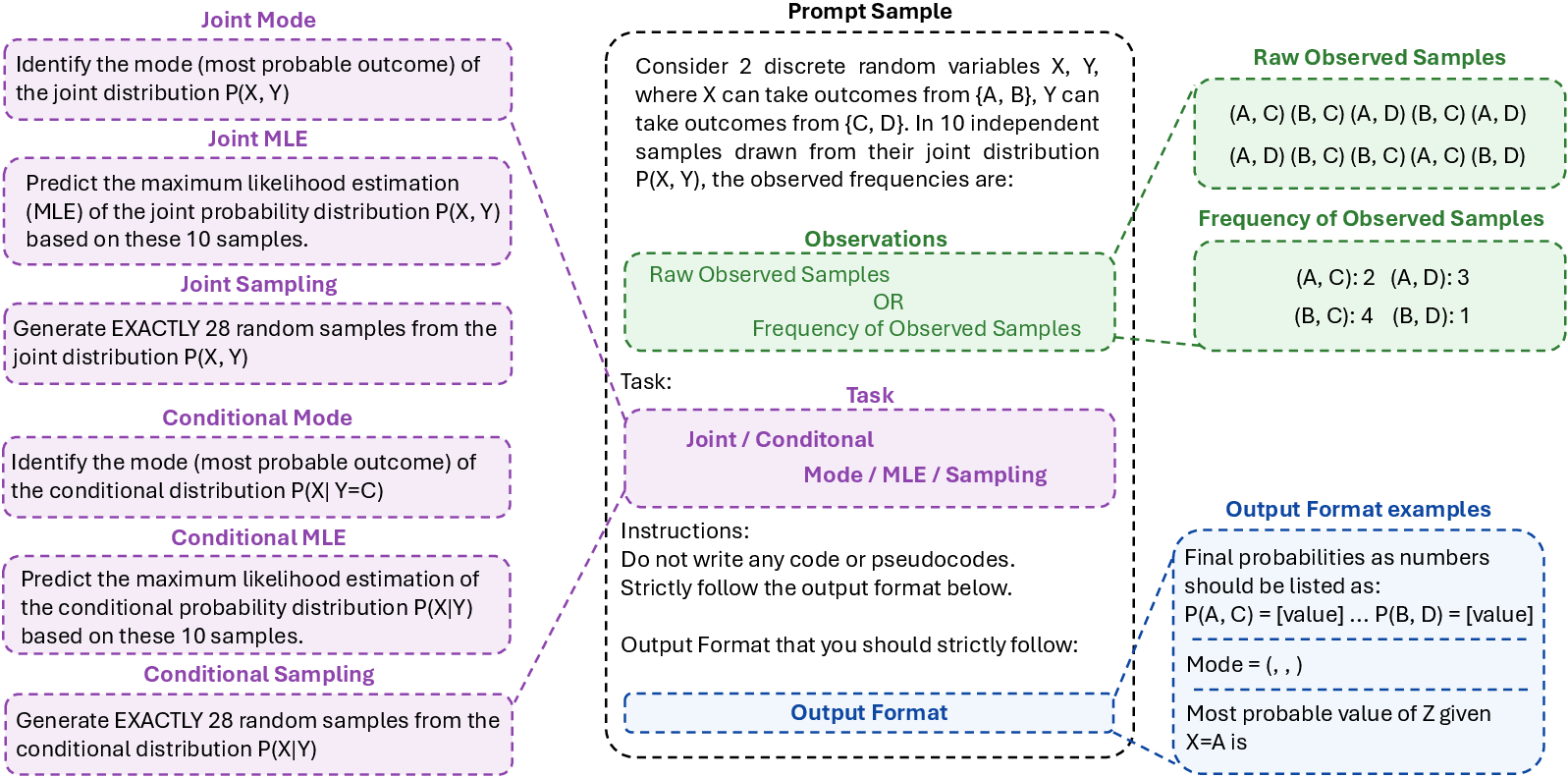
Figure 1: Prompt structure for evaluating LLMs on probabilistic reasoning tasks. Each prompt includes definitions of the random variables, observed samples or frequencies, a task specification (e.g., mode, MLE, sample generation), and output formatting instructions.
Mode Identification
The mode identification task assesses whether LLMs can identify the mode of empirical distributions. The evaluation distinguishes between joint-mode tasks, where the entire distribution is considered, and conditional-mode tasks, which require reasoning over conditional distributions.
Maximum Likelihood Estimation
For MLE tasks, models estimate probabilities of outcomes using the empirical distribution. Models are evaluated based on the Total Variation Distance (TVD) between predicted and true distributions.
Sample Generation
The sample generation task prompts models to produce samples from specified distributions, measuring generative abilities. Performance is quantified by comparing the TVD of model-generated samples against baseline distributions.
Experimental Evaluations
Model Selection
A range of instruction-finetuned models, varying in size from 7B to 70B parameters, were evaluated to assess diverse capabilities. Models included Llama3.1-8B, Llama3.3-70B, Qwen2.5-7B, DeepSeek-R1-Distill-Qwen-7B, GPT-4o-mini, and GPT-4.1-mini.
Results Summary
Results reveal that larger models like Llama3.3-70B and GPT-4.1-mini perform superiorly across tasks, notably in sample generation where they outperform traditional random sampling. Smaller models display marked performance degradation as distribution complexity increases and when tasked with counting raw samples in long contexts.
Robustness Analysis
The analysis highlights label sensitivity and performance deterioration when raw samples are provided. Smaller models exhibit heightened sensitivity to label variations, affirming biases potentially rooted in training data.
Conclusion
The study underscores progress in LLMs' probabilistic abilities, yet identifies critical limitations in handling conditional reasoning and large context inferences. It encourages addressing these challenges for advancing LLM robustness in uncertainty reasoning. Future directions include extending evaluation to more complex distributions and improving model designs to inherently resolve counting and context-length issues.