- The paper presents a contrastive RL approach that derives complex skills through single-goal exploration without relying on dense rewards or demonstrations.
- It employs temporal contrastive learning and an entropy-augmented actor loss to progressively develop navigational and manipulative abilities.
- Empirical results demonstrate robust performance in tasks like robotic manipulation and maze navigation, even under environmental perturbations.
A Single Goal is All You Need: Skills and Exploration Emerge from Contrastive RL without Rewards, Demonstrations, or Subgoals
Introduction
The paper presents an intriguing approach to reinforcement learning (RL) with a focus on the challenges of effective exploration in sparse reward settings. Traditional exploration methods often require dense reward functions, demonstrations, or hierarchical RL techniques, which pose additional overhead for both human users and computational resources. This work targets a simplified problem setting where an RL agent is provided with a single goal observation without any auxiliary feedback mechanisms. The method proposed introduces a novel application of contrastive reinforcement learning (CRL), which facilitates the learning of complex skills through directed exploration, even in the absence of traditional reward structures.
Emergent Skills and Exploration
The study's most notable contribution is the empirical evidence that an RL agent can develop a sequence of increasingly complex skills using a simple goal-directed exploration strategy. The agent starts by learning basic movements and gradually progresses towards intricate manipulative tasks without ever receiving successful trial feedback.
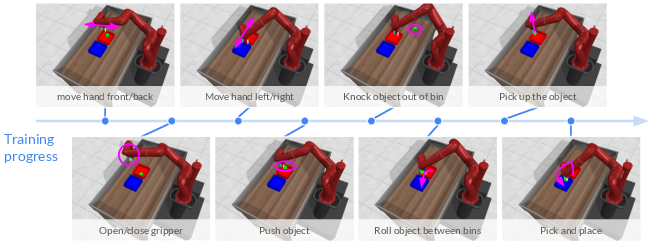
Figure 1: Skills and Directed Exploration Emerge. In this bin picking task, skills progress from basic movements to placing a block at the desired location.
Methodology
The proposed method builds upon contrastive RL, which employs temporal contrastive learning to derive goal-conditioned policies. In practice, this CRL variant adapts its action policy continuously based on the single available goal. The policy leverages learned representations in state-action space, coupled with an entropy-augmented actor loss, allowing the agent to derive navigational and manipulative strategies that increase in complexity over time.
Implementation requires minimal modifications to existing CRL frameworks and circumvents the need for density estimations or complex hyperparameter tuning. The simplicity of the approach allows the agent to explore effectively, despite the absence of intermediate guidance or reward signals.
Comparative Analysis
When assessed against state-of-the-art exploration strategies that rely on a variety of goals or reward enhancements, the proposed single-goal CRL approach consistently outperformed in environments requiring complex manipulation and navigation.
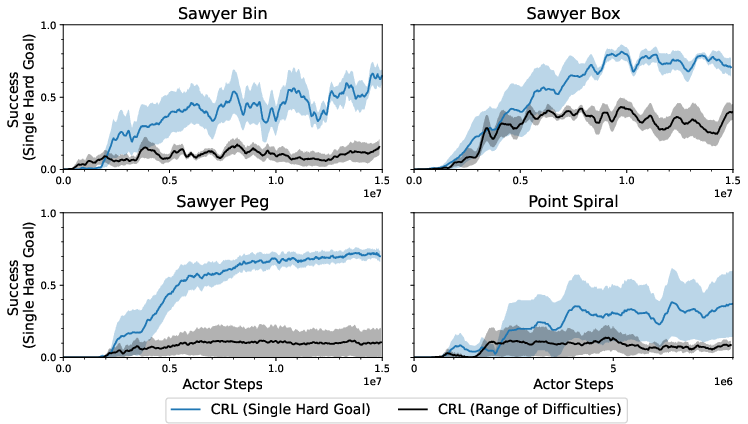
Figure 2: Single goal Exploration is Highly Effective across multiple environments compared to traditional mixed difficulty exploration.
Empirical Results
The research showcases the ability of single-goal CRL to solve challenging tasks efficiently, achieving rapid success within a relatively small number of trials in complex environments. The simplicity and effectiveness are demonstrated across multiple environments, from robotic manipulation tasks requiring delicate object handling to intricate maze navigation scenarios.
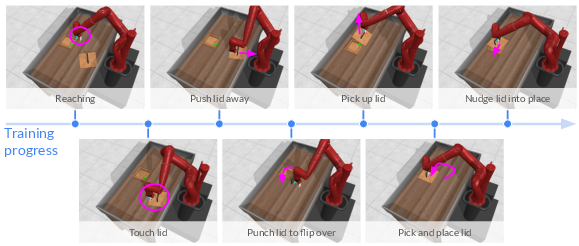
Figure 3: Skills and Directed Exploration for Putting a Lid on a Box: Progression from reaching to placing skills.
Robustness and Generalization
Further experiments highlight the robustness of the learned policies to environmental perturbations. Even in dynamic settings where object positions are perturbed mid-episode, the agent demonstrates significant resilience, achieving high success rates despite these variations.
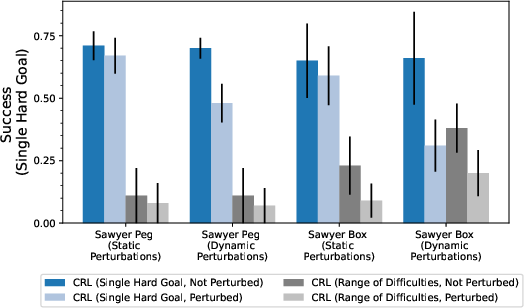
Figure 4: Robustness to perturbations underscores the adaptability of single-point CRL policies.
Conclusion
The study provides compelling insights into the potential of single-goal exploration strategies within CRL frameworks. This approach not only simplifies the setup for goal-conditioned tasks by removing the need for extrinsic rewards or subgoals but also exposes the unexpected efficiencies and capabilities of learned representations in autonomous skill acquisition. Future investigations may explore the theoretical underpinnings of this phenomenon and adapt the technique to scenarios lacking fixed goals. The work opens pathways for further research into minimal-intervention RL systems, potentially reducing the human and computational resources required in RL applications.
Limitations and Future Work
The current analysis lacks a thorough theoretical explanation for why contrastive representations effectively drive exploration in this manner. Future work should explore the theoretical mechanisms underpinning these empirical observations. Expanding the framework to other RL problems beyond fixed-goal settings could also yield valuable insights.
Acknowledgments paraphrased for brevity.