- The paper introduces InfGen, a novel framework that reimagines the VAE decoder into a transformer-based generator for any resolution output.
- The paper leverages cross-attention and implicit neural positional embeddings to convert fixed-size latents into high-quality images with up to 10× faster 4K synthesis.
- The paper demonstrates plug-and-play integration with latent diffusion models, achieving state-of-the-art metrics such as improved FID and recall across diverse resolutions.
InfGen: A Resolution-Agnostic Paradigm for Scalable Image Synthesis
Introduction and Motivation
The paper introduces InfGen, a novel framework for arbitrary-resolution image synthesis that fundamentally rethinks the decoder stage in latent diffusion models (LDMs). While prior work has focused on improving the generative modeling and sampling efficiency of the first stage (e.g., LDMs, DiT), the decoder—typically a VAE—has remained a bottleneck for high-resolution image generation due to its fixed output size and limited generative capacity. InfGen replaces the VAE decoder with a transformer-based generator capable of reconstructing images at any resolution from a fixed-size latent, enabling rapid, high-quality synthesis without retraining the underlying diffusion model.
Methodology
Two-Stage Generation Paradigm
InfGen operates within the standard two-stage paradigm of LDMs: (1) a generative model produces a compact latent representation, and (2) a decoder reconstructs the image from this latent. The key innovation is in the second stage, where InfGen decodes the fixed-size latent into images of arbitrary resolution via a single forward pass, leveraging a transformer-based architecture with cross-attention mechanisms.
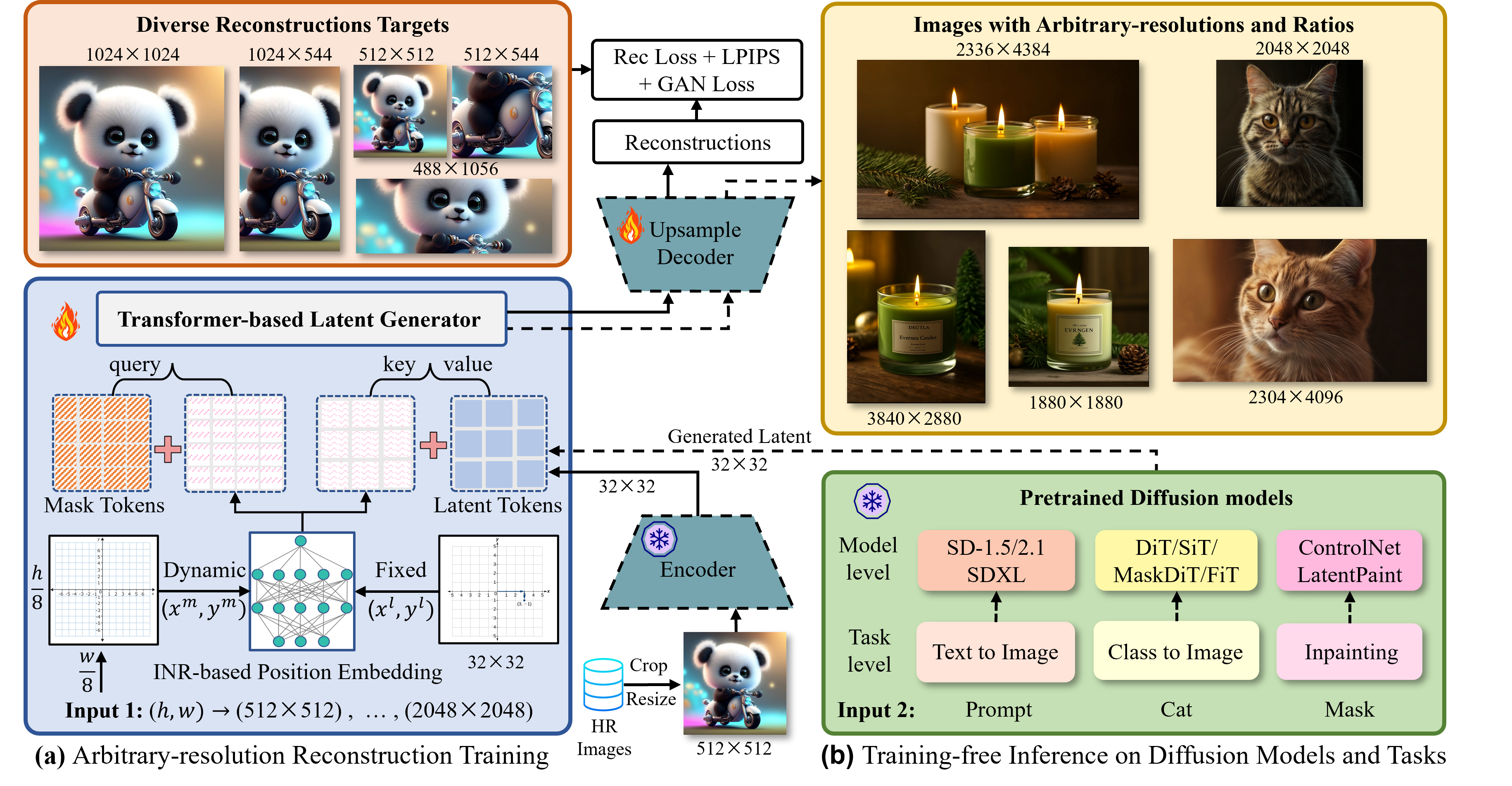
Figure 1: The InfGen generator is trained in latent space to reconstruct images at any resolution and aspect ratio, and can be applied to various diffusion models during inference.
Architecture
- Latent Conditioning: The fixed-size latent z from the VAE encoder serves as the content prompt. Mask tokens, shaped according to the target resolution, act as queries in the transformer decoder.
- Cross-Attention: The mask tokens interact with the latent via multi-head cross-attention, enabling the generator to synthesize images at arbitrary resolutions.
- Implicit Neural Positional Embedding (INPE): To align spatial information between mask and latent tokens, INPE maps coordinates to high-frequency Fourier features and then to dynamic positional encodings via an implicit neural network. This enables seamless interaction between fixed-size latents and variable-size outputs.
Training and Optimization
- Loss Functions: The training objective combines L1 reconstruction loss, LPIPS perceptual loss, and PatchGAN adversarial loss.
- Data: Training utilizes 10M high-resolution images from LAION-Aesthetic, with dynamic cropping and resizing to support arbitrary output sizes.
- Frozen Encoder: The VAE encoder is kept frozen, ensuring compatibility with existing LDMs and minimizing retraining costs.
InfGen supports iterative extrapolation for ultra-high-resolution synthesis. Starting from a low-resolution latent, the output image is re-encoded and further upscaled in subsequent iterations, enabling robust generation at resolutions far beyond the training regime.
Experimental Results
Efficiency and Latency
InfGen dramatically reduces inference time for high-resolution synthesis. For 4K images, generation time drops from over 100 seconds (standard diffusion) to under 10 seconds, representing a 10× speedup over the previous fastest method, UltraPixel.
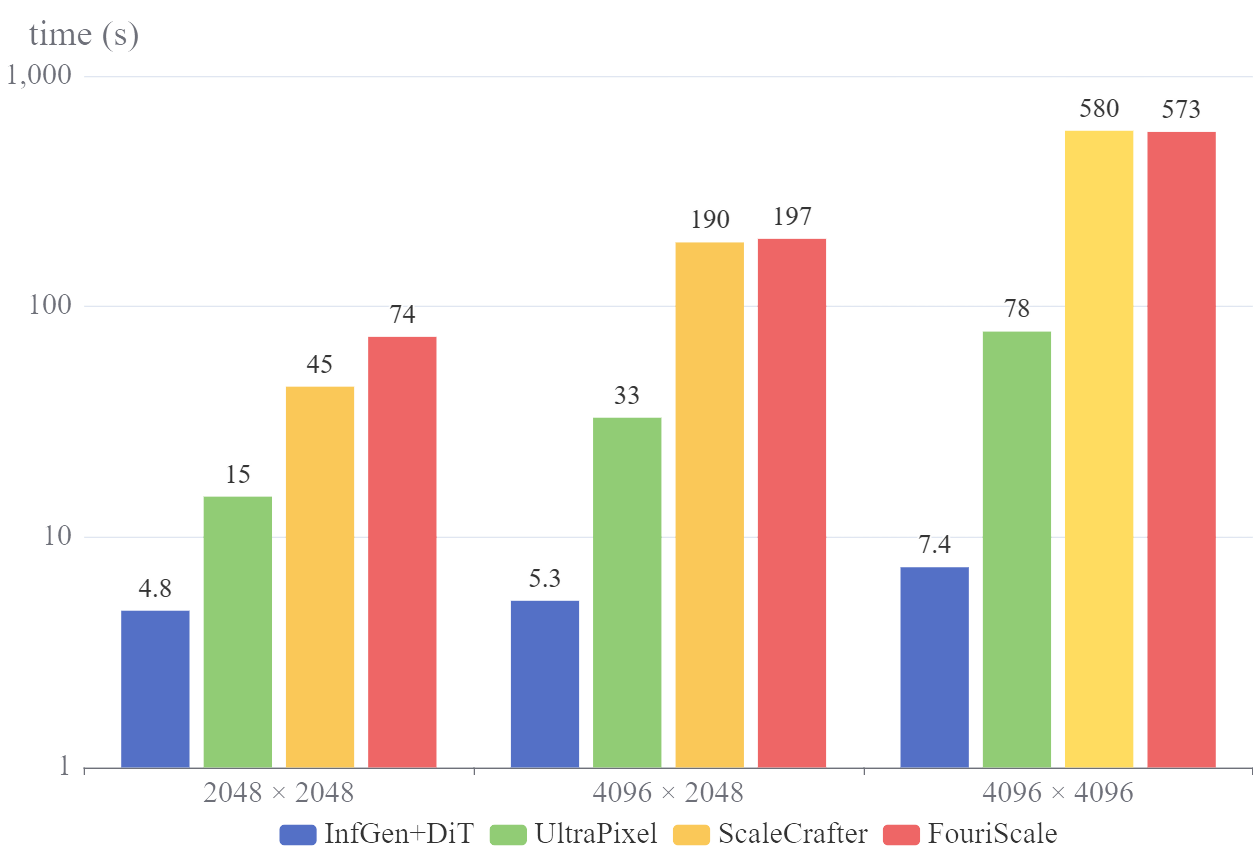
Figure 2: Inference time (seconds per image) for high-resolution image generation methods. The vertical axis is a logarithmic scale.
- Tokenization Quality: InfGen achieves competitive reconstruction metrics (FID, PSNR, SSIM) compared to VQGAN, SD-VAE, and SDXL-VAE, despite handling more complex tasks.
- Resolution Scaling: Across multiple LDMs (DiT, SiT, FiT, SD1.5), replacing the VAE decoder with InfGen yields consistent improvements in FID, sFID, precision, and recall at all tested resolutions, with especially pronounced gains at ultra-high resolutions (e.g., 44% FID improvement at 3072×3072).
- Benchmarking: InfGen+SDXL-B-1 achieves state-of-the-art FID and recall at 1024×1024 and 2048×2048, with inference latency far below competing methods.
Qualitative Analysis
InfGen produces visually coherent, detail-rich images at arbitrary resolutions, outperforming baseline LDMs in semantic consistency and texture fidelity.

Figure 3: Visualizations of arbitrary image generation. InfGen improves the generation ability for LDMs across various resolutions.
Practical Implications
Plug-and-Play Integration
InfGen is designed as a drop-in replacement for VAE decoders in any LDM sharing the same latent space, requiring no retraining of the generative model. This enables rapid upgrades of existing diffusion pipelines to support arbitrary-resolution synthesis.
Resource Efficiency
By decoupling resolution from latent size and leveraging transformer-based decoding, InfGen achieves high-quality synthesis with minimal computational overhead, making it suitable for deployment in resource-constrained environments and real-time applications.
Generalization
The architecture supports diverse generative tasks, including class-guided, text-conditional, and inpainting, and is robust to both object-centric and scene-centric images.
Theoretical Implications and Future Directions
InfGen demonstrates that the decoder stage in LDMs can be reimagined as a generative process, not merely a reconstruction task. The use of cross-attention and INPE for arbitrary-resolution synthesis opens avenues for further research in scalable generative modeling, including:
- Continuous Latent Spaces: Extending InfGen to support continuous latent representations and variable aspect ratios.
- Multi-modal Generation: Integrating InfGen with multi-modal diffusion models for scalable video and 3D synthesis.
- Adaptive Tokenization: Investigating dynamic latent allocation strategies for even greater efficiency and fidelity.
Conclusion
InfGen establishes a new paradigm for scalable, resolution-agnostic image synthesis by transforming the decoder stage of LDMs into a generative process. It delivers substantial improvements in both quality and efficiency, enabling arbitrary-resolution generation with minimal latency and broad compatibility. The framework's plug-and-play nature and strong empirical results suggest significant potential for advancing practical and theoretical research in high-resolution generative modeling.

