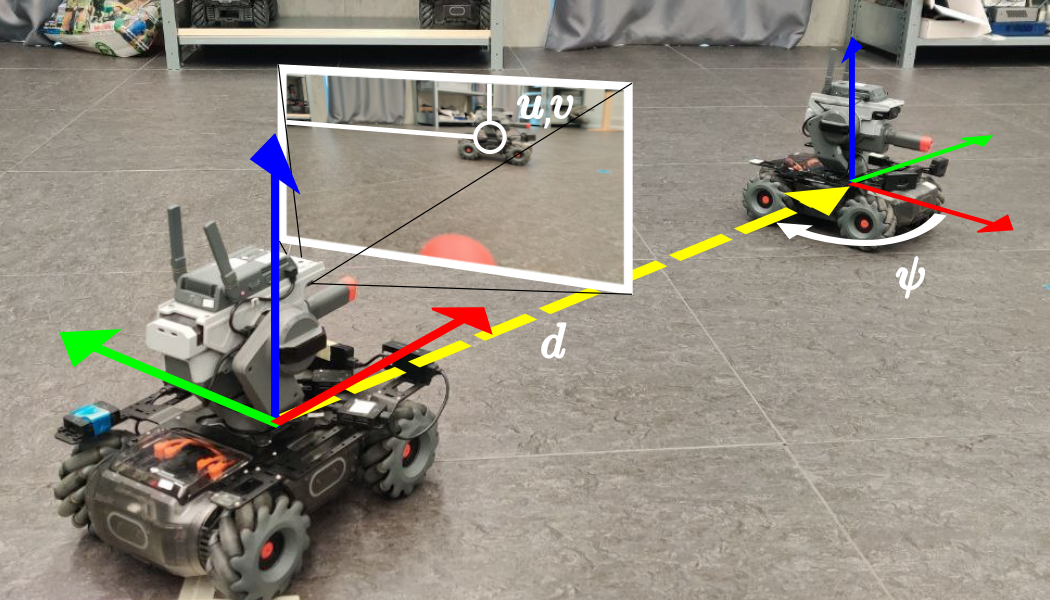
Self-supervised Learning Of Visual Pose Estimation Without Pose Labels By Classifying LED States
Abstract: We introduce a model for monocular RGB relative pose estimation of a ground robot that trains from scratch without pose labels nor prior knowledge about the robot's shape or appearance. At training time, we assume: (i) a robot fitted with multiple LEDs, whose states are independent and known at each frame; (ii) knowledge of the approximate viewing direction of each LED; and (iii) availability of a calibration image with a known target distance, to address the ambiguity of monocular depth estimation. Training data is collected by a pair of robots moving randomly without needing external infrastructure or human supervision. Our model trains on the task of predicting from an image the state of each LED on the robot. In doing so, it learns to predict the position of the robot in the image, its distance, and its relative bearing. At inference time, the state of the LEDs is unknown, can be arbitrary, and does not affect the pose estimation performance. Quantitative experiments indicate that our approach: is competitive with SoA approaches that require supervision from pose labels or a CAD model of the robot; generalizes to different domains; and handles multi-robot pose estimation.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way for a robot to figure out where another robot is and which way it’s facing (its “pose”) by looking at a single color photo. The clever part: during training, the robot doesn’t need any pose labels or a 3D model of the other robot. Instead, it learns by trying to guess which of the other robot’s little lights (LEDs) are on or off. While learning to solve that simpler “lights” problem, the robot naturally picks up how to find the other robot in the picture, how far away it is, and which way it’s turned.
What questions did the researchers ask?
In simple terms:
- Can a robot learn to estimate another robot’s pose using only camera images and LED on/off information, without human-provided pose labels or a detailed 3D model?
- Can this learning happen automatically while robots move around, without special lab equipment?
- Will the learned system work in new places and even when there are multiple robots in view?
How did they do it?
Think of it like this: if you can look at a robot and accurately tell whether the “front” light or the “back” light is on, you must already know where the robot is in the image and which side you’re seeing. The paper turns that idea into a training strategy.
Collecting training data (fully automatic)
- Two robots wander around randomly.
- Every few seconds, each robot switches some of its LEDs on or off at random and sends its current LED states over radio.
- Each robot also takes pictures. The paired LED on/off list is used as the label for each picture.
- No one tells the system where the robots are. In fact, most images (about 77%) don’t even contain the other robot, and that’s okay.
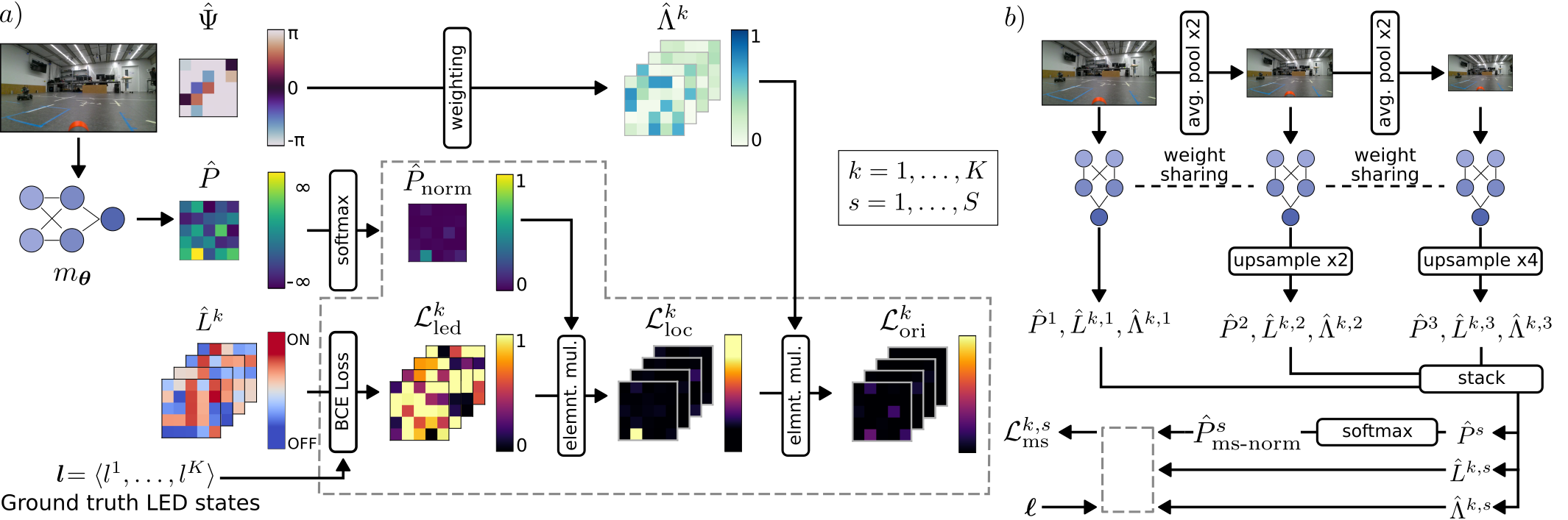
The trick: learn from LED on/off to get pose “for free”
- The neural network looks at an image and tries to predict the state (on/off) of each LED on the other robot.
- To get LED states right, the network must first:
- Find the robot in the image (its 2D location).
- Figure out which way the robot is facing (its bearing/heading).
- Judge how big it looks in the image (related to distance).
So, by solving the “Which lights are on?” puzzle, the network is forced to learn pose.
How the network figures out where the robot is and which way it’s facing
- Finding the robot: The network produces a “presence map” that highlights the parts of the image that probably contain the robot. You can imagine it as a heat map that glows where the robot is likely to be.
- Figuring out the visible side (bearing): If the robot is facing toward you, the “front” LED is probably visible; if it’s facing away, the “back” LED is more likely visible. The network learns a simple, smooth rule that links the robot’s facing direction to which LEDs should be visible. It uses this to avoid penalizing itself for LEDs that are on but hidden from view.
- Estimating distance by zooming: The same picture is fed to the network at several zoom levels (scales). The robot’s apparent size depends on distance—the farther it is, the smaller it looks. The network learns which zoom level fits the robot best, and uses that to estimate distance.
- One-photo calibration: To turn “apparent size” into a real distance in meters, they do a simple calibration with a single photo where the true distance is known. After that, the system can estimate metric distance from any new photo.
- No LEDs needed at test time: Once trained, the model no longer needs the LEDs to be on. It directly outputs the robot’s image position, distance, and heading from any single camera frame.
What did they find?
Here are the main results:
- Competitive performance without labels or 3D models: Their method performs close to strong baselines that use full pose labels or detailed CAD models of the robot. That’s impressive because this method trains from scratch using only LED on/off info.
- Works even with lots of “empty” images: Training still succeeds even though most training pictures don’t contain a robot.
- Generalizes to new places: The model trained in one room worked in different rooms (classroom, gym, break room) without extra tuning. It could also be fine-tuned for even better results.
- Multiple robots: Even though it was trained with at most one visible robot, at test time it can handle images with more than one by finding multiple peaks in its “presence map.”
- LED state doesn’t matter at deployment: The robot can estimate pose even if all LEDs are off when it’s being used. The LEDs are only needed during training to provide the “self-supervision.”
A small gap remains in distance accuracy compared to a fully supervised model, mostly because distance is estimated using a few discrete zoom levels. Using more zoom levels can reduce that gap, at the cost of a bit more computation.
Why does this matter?
- Lower cost, less setup: No need for motion-capture systems, hand-made labels, or accurate CAD models. Robots can teach themselves by moving around together and flipping LEDs.
- Robust and flexible: Because it learns from the real world, it avoids “simulation-to-reality” problems and adapts more easily to new environments.
- A general self-supervision idea: The approach shows how a simple, controllable signal (like LED states) can guide a model to learn much more complex skills (pose estimation).
Limits and next steps
- Mostly 2D pose: The paper focuses on ground robots (position in the plane and heading). Extending to full 3D orientation would need more careful LED placement and modeling.
- Distance resolution: Distance is tied to discrete zoom steps; finer steps improve accuracy but add compute time. Future models could use multi-scale architectures that estimate distance more smoothly.
- Occlusions and crowded scenes: The paper’s main tests did not include heavy occlusions by other objects. Handling many robots at once during training is a planned improvement.
In short, this research shows a neat way to turn a simple, cheap signal (on/off LEDs) into a powerful teacher. By learning to read the lights, a robot also learns to see where other robots are and which way they’re facing—no manual labels required.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Quantify how errors in the “approximate viewing direction” assumption for each LED (misalignment, mounting tolerances, drift) affect pose accuracy; determine acceptable angular error bounds per LED.
- Replace the hand-crafted cosine visibility function with a learned, calibrated visibility model; compare performance under non-equidistant and irregular LED layouts.
- Determine the minimum number and spatial arrangement of LEDs needed to guarantee identifiability of the target’s pose (2D vs 3D); provide theoretical conditions under which pose is uniquely recoverable.
- Evaluate robustness to partial LED failures (missing/broken LEDs), non-independent LED states, and inconsistent brightness/color across units; develop training-time strategies to handle these cases without retraining from scratch.
- Measure sensitivity to label noise from desynchronization, radio dropouts, or timestamp drift between LED-state broadcasts and camera frames; design label-noise–robust losses or temporal alignment modules.
- Establish detection capabilities in empty scenes: define and validate a principled threshold or uncertainty-aware criterion for “no robot present” (false-positive/false-negative rates on backgrounds).
- Characterize performance under strong external occlusions (by scene objects, other robots) beyond self-occlusion; devise occlusion-aware training or augmentations that simulate external occluders.
- Analyze failure modes in high dynamic range, strong sunlight, glare, specular backgrounds, and motion blur; test outdoors and across diverse illumination to understand LED visibility limits and camera exposure interactions.
- Generalize beyond a single robot platform: test across robots with different sizes, textures, and form factors; quantify how much retraining is needed and whether cross-robot transfer learning is feasible.
- Evaluate cross-camera generalization (different lenses, intrinsics, distortions, resolutions); test robustness to auto-focus/auto-exposure changes and camera mounting variations.
- Improve distance estimation beyond discrete multi-scale classification; explore continuous scale regression, differentiable pyramid/feature-scale heads, or metric learning that preserves scale information while avoiding heavy runtime overhead.
- Validate the single-image calibration for distance across time, cameras, and robot headings; quantify calibration drift and derive procedures for quick recalibration in the field.
- Incorporate camera extrinsics and turret/camera pitch/roll variations to move from 2D (camera-frame) to ground-plane or full 3D pose; specify what additional LEDs and calibration are minimally required for 6-DoF estimation.
- Exploit temporal cues (optical flow, ego-odometry, multi-frame consistency) during training and inference; quantify gains from temporal smoothing, trajectory priors, or recurrent architectures.
- Provide a quantitative evaluation for multi-robot scenes (not just qualitative): assess separation of local maxima, NMS strategies, data association when multiple identical robots are present, and performance under mutual occlusions.
- Investigate identity management across frames (re-identification) when multiple identical robots have different LED states; determine how to link tracks without supervised IDs.
- Examine the impact of the empty-frame ratio and data efficiency: how do performance and convergence change as the proportion of visible-robot frames decreases; what mining/weighting schemes best exploit sparse positives?
- Run controlled ablations on the loss components (localization map softmax, orientation-weighting, multi-scale normalization) to confirm each term’s necessity and measure its contribution and failure modes.
- Assess fairness of comparisons to CAD/template-based baselines (e.g., number/diversity of templates, refinement steps); broaden baselines to include modern correspondence, transformer-based, or keypoint-free methods under comparable runtime constraints.
- Benchmark on embedded hardware commonly used on robots (e.g., Jetson-class devices): report throughput, latency, memory footprint, and energy; propose model compression or distillation if needed.
- Add calibrated uncertainty estimates for position, orientation, and distance; evaluate how reliable confidence measures benefit downstream multi-robot planners or safety logic.
- Explore pretext tasks beyond LEDs (e.g., controllable displays, mechanical actuators, IR beacons, active patterns) and multimodal sensors (IR, depth, event cameras); quantify when and how alternative signals outperform LEDs.
- Study adversarial or confounding light sources (other blinking LEDs, signage, reflections); develop discriminative features or spectral filtering to reduce false cues from non-robot lights.
- Analyze symmetry-induced ambiguities (front/back or left/right confusion) and propose minimal additional signals (e.g., asymmetric LED layout or color coding) to break symmetries with proofs or empirical guarantees.
- Provide domain-adaptation strategies that do not require LEDs at adaptation time (e.g., self-training, style transfer, consistency across views) to ease deployment where LED control is unavailable.
- Report learning dynamics and robustness: convergence profiles, sensitivity to hyperparameters, initialization, and scale choice; identify conditions that lead to degenerate attention maps or collapsed solutions.
Collections
Sign up for free to add this paper to one or more collections.