- The paper provides a comprehensive survey of visual grounding in VLMs, reviewing its evolution, architectural paradigms, and evaluation protocols.
- It details various training regimes including pretraining, instruction tuning, and reinforcement learning to enhance model alignment and factuality.
- The survey identifies challenges such as data quality, catastrophic forgetting, and benchmark limitations that impact the development of interpretable multimodal models.
Visual Grounding in Vision-LLMs: Foundations, Architectures, and Challenges
Introduction
Visual grounding in Vision-LLMs (VLMs) is the process by which a model identifies and localizes regions within visual input that correspond to natural language descriptions. This capability is central to a wide spectrum of multimodal tasks, including referring expression comprehension (REC), grounded visual question answering (GVQA), grounded captioning, and control in interactive environments. The paper "Towards Understanding Visual Grounding in Vision-LLMs" (2509.10345) provides a comprehensive survey of the evolution, architectural paradigms, evaluation protocols, and open challenges in visual grounding for VLMs, with a particular focus on developments since 2022.
Expanding the Definition and Scope of Visual Grounding
The paper argues for a broad definition of visual grounding, extending beyond traditional REC and phrase localization to encompass tasks such as grounded captioning, GVQA, and agent-based interaction with GUIs. The authors emphasize that grounding is not only about spatial localization but also about establishing interpretable, verifiable links between linguistic expressions and visual evidence. This explicit connection is critical for transparency and reliability, especially in high-stakes applications.

Figure 1: Representative input-output pairs from datasets across visual grounding domains, including REC, GVQA, grounded captioning, and GUI grounding.
Architectural Paradigms for Grounded VLMs
The survey delineates the architectural evolution from early CNN-RNN hybrids to transformer-based models and, more recently, to general-purpose VLMs that treat visual patch embeddings as token sequences for LLMs. The standard VLM architecture comprises a visual encoder (typically ViT or CLIP-based), a connector module (linear or MLP-based), and a transformer language backbone. The connector aligns visual and textual embedding spaces and may compress the visual sequence for efficiency.
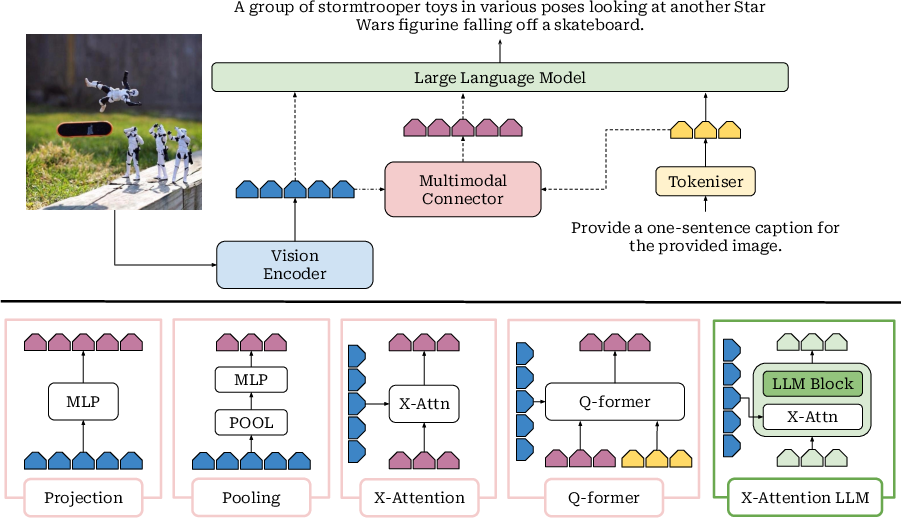
Figure 2: Architectural design choices in modern VLMs, highlighting early fusion strategies and multimodal connectors for integrating image and text modalities.
The paper provides a detailed taxonomy of region representation strategies:
- Object-centric: Region proposals with sentinel tokens, interpretable but limited by predefined categories and coarse spatial granularity.
- Pixel-level: ViT-based patch embeddings, supporting fine-grained localization. Pixel-level approaches further split into discretized (quantized bins) and raw coordinate formats, with the latter leveraging the LLM's numerical reasoning but introducing modality gaps.
The survey notes that most contemporary VLMs favor pixel-level representations for their flexibility and granularity.
Training Regimes and Data Pipelines
The development of grounded VLMs typically involves multi-stage training pipelines:
- Pretraining: Alignment of image-text pairs, often using large-scale web-scraped datasets. The quality of captions and region annotations is a limiting factor, with synthetic re-captioning and filtering techniques improving alignment.
- Instruction Tuning: Reformulation of tasks into instruction-response pairs, enabling generalization to unseen instructions and multimodal interaction.
- Alignment via Reinforcement Learning: Recent work explores reward-based optimization (e.g., GPRO) to improve factuality and multimodal reasoning, moving beyond chain-of-thought traces to solution-level grounding objectives.
The paper highlights the importance of incorporating grounding objectives throughout all training stages, noting that many datasets rely on pseudo-labels or proprietary models, which can compromise reproducibility and ecological validity.
Evaluation Protocols and Benchmarks
The survey provides a systematic overview of benchmarks and evaluation metrics for grounding tasks:
- REC/RES: Intersection over Union (IoU) for bounding box/mask overlap, with Precision@($F_1$=1, IoU$\ge$0.5) for generalized settings.
- GVQA: Multiple-choice accuracy, string matching for open-ended answers, and region-level IoU.
- Grounded Captioning: Standard n-gram overlap metrics (BLEU, CIDEr, METEOR, SPICE) and reference-free metrics (CLIPScore, RefCLIPScore) for semantic alignment.
- GUI Agents: Goal-oriented success rate and step-wise action accuracy, with region overlap metrics for grounding.
The paper notes that established benchmarks (e.g., RefCOCO variants) are increasingly saturated and limited in linguistic and visual diversity, motivating the development of more realistic and challenging datasets.
Key Challenges and Open Problems
The authors identify several intertwined challenges:
- Quality of Unimodal Experts: Controlled experiments show that the language backbone has a greater influence on VLM performance than the vision encoder, but both are critical for grounding.
- Self- vs. Cross-Attention: Cross-attention architectures outperform autoregressive fusion when backbones are frozen, but the advantage diminishes with LoRA adapters.
- Mapping vs. Compression: Feature-preserving connectors (MLPs, CNNs) yield better fine-grained grounding, but efficiency trade-offs arise with high-resolution inputs.
- Training Regime and Forgetting: Multi-stage training can lead to catastrophic forgetting; continual inclusion of grounding data is necessary to preserve capabilities.
- Benchmark Validity and Data Contamination: Overlap between training and evaluation data undermines generalization claims; transparent dataset creation is essential.
The paper also highlights the nascent state of GUI agent grounding, the need for more interpretable multimodal reasoning, and the lack of rigorous evaluation of architectural design choices specifically for grounding.
Implications and Future Directions
The survey underscores the centrality of visual grounding for fine-grained multimodal understanding and interpretable AI. Theoretical implications include the need for models that can bridge modality gaps and perform in-context cross-modal retrieval. Practically, advances in grounding will enable robust agents for web, desktop, and mobile environments, as well as improved transparency in multimodal reasoning.
Future research directions include:
- Development of open, transparent, and ecologically valid grounding datasets.
- Systematic evaluation of connector architectures and fusion strategies for grounding.
- Integration of grounding with multimodal chain-of-thought and solution-level reasoning.
- Addressing catastrophic forgetting and task interference in multi-stage VLM training.
- Expanding the scope of grounding to embodied agents and real-world interactive environments.
Conclusion
This paper provides a rigorous synthesis of the state of visual grounding in VLMs, mapping the evolution of architectural paradigms, training pipelines, evaluation protocols, and open challenges. The analysis demonstrates that grounding is a multifaceted capability, shaped by design choices at every stage of model development. Addressing the identified challenges will be critical for advancing both the interpretability and generalization of next-generation multimodal models.

