- The paper introduces FLUX-Reason-6M, a 6-million image text-to-image reasoning dataset with explicit chain-of-thought annotations.
- It details a robust data curation pipeline leveraging advanced generative models and VLMs over 15,000 A100 GPU days.
- The comprehensive PRISM-Bench evaluates T2I models across seven tracks, revealing challenges in text rendering and long instruction adherence.
FLUX-Reason-6M & PRISM-Bench: A Million-Scale Text-to-Image Reasoning Dataset and Comprehensive Benchmark
Introduction
The paper introduces FLUX-Reason-6M, a 6-million-scale text-to-image (T2I) reasoning dataset, and PRISM-Bench, a comprehensive benchmark for evaluating T2I models across seven distinct tracks. The motivation stems from the lack of large-scale, reasoning-focused datasets and robust evaluation protocols in the open-source community, which has led to a persistent performance gap between open-source and closed-source T2I models. FLUX-Reason-6M is constructed to address reasoning capabilities in T2I generation, while PRISM-Bench provides fine-grained, human-aligned evaluation using advanced vision-LLMs (VLMs).
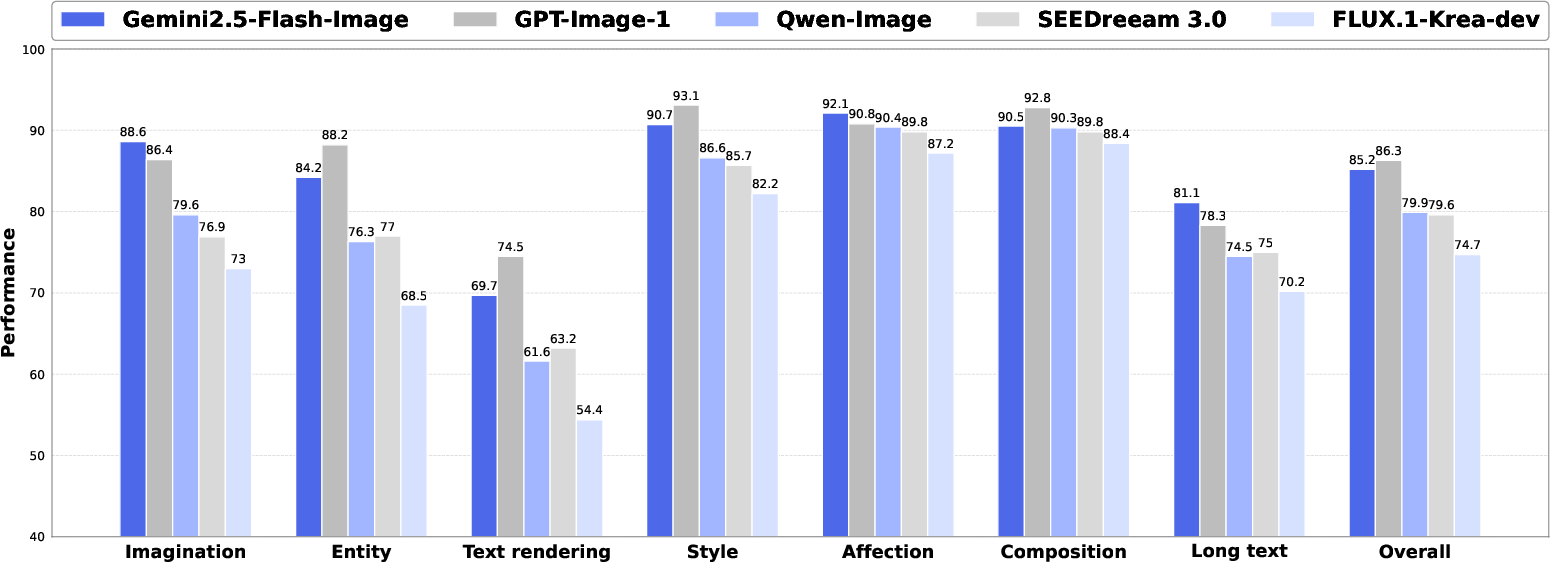
Figure 1: Evaluation of state-of-the-art text-to-image models with the proposed PRISM-Bench.
FLUX-Reason-6M Dataset
Architectural Design: Six Characteristics and Generation Chain-of-Thought
FLUX-Reason-6M is architected around six key characteristics: Imagination, Entity, Text rendering, Style, Affection, and Composition. Each image is annotated with multi-labels, reflecting the multifaceted nature of complex scene synthesis. The dataset's core innovation is the Generation Chain-of-Thought (GCoT), which provides stepwise reasoning for image construction, moving beyond simple descriptive captions to explicit breakdowns of compositional and semantic logic.

Figure 2: Showcase of FLUX-Reason-6M in six different characteristics and generation chain of thought.
Data Curation Pipeline
The data curation pipeline leverages advanced generative models (FLUX.1-dev) and VLMs for large-scale synthesis, mining, annotation, filtering, and translation. The process, executed over 15,000 A100 GPU days, ensures high-quality, balanced coverage across all six characteristics. Augmentation strategies are employed to address category imbalance, notably for Imagination and Text rendering, using progressive prompt generation and mining-generation-synthesis pipelines.
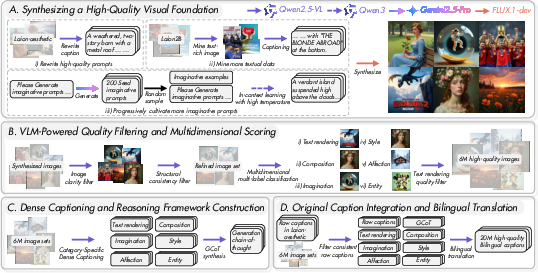
Figure 3: An overview of FLUX-Reason-6M data curation pipeline. The entire process was completed using 128 A100 GPUs over a period of 4 months.
Quality Filtering and Annotation
A multi-stage VLM-powered pipeline filters and scores images for visual integrity and categorical relevance. Qwen-VL is used for foundational quality filtering, robust multidimensional classification, and typographic quality assurance. Dense, category-specific captions and GCoT annotations are generated for each image, resulting in a dataset with 20 million bilingual (English/Chinese) captions.
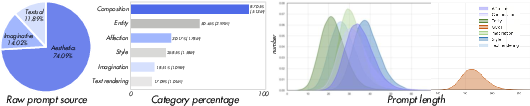
Figure 4: Left: Three subsets of raw prompt sources. Middle: Image category ratio. Right: Prompt Suite Statistics.
PRISM-Bench: Benchmark Design and Evaluation Protocol
Benchmark Structure
PRISM-Bench comprises seven tracks: the six characteristics from FLUX-Reason-6M plus a Long Text track leveraging GCoT prompts. Each track contains 100 prompts, split between representative samples and curated challenges. Prompts are selected via semantic clustering and stratified sampling to ensure diversity and coverage.
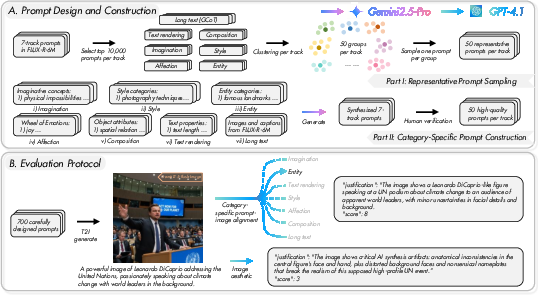
Figure 5: An overview of the prompt design and evaluation protocol of PRISM-Bench.
Evaluation Protocol
Evaluation is performed using GPT-4.1 and Qwen2.5-VL-72B, focusing on two axes: prompt-image alignment and image aesthetics. Track-specific instructions guide VLMs to assess alignment, while a unified protocol evaluates aesthetics. Scores are reported as averages across prompts, providing composite and per-track metrics.

Figure 6: Showcase of Long text track in the PRISM-Bench. GPT4.1 is not only required to score based on image-text alignment and image aesthetics, but also to provide a brief justification.

Figure 7: Showcase of Text rendering track in the PRISM-Bench-ZH.
Experimental Results
Nineteen models are evaluated on PRISM-Bench, including leading closed-source (Gemini2.5-Flash-Image, GPT-Image-1) and open-source (Qwen-Image, FLUX series, HiDream series, SDXL, SEEDream 3.0) systems. Closed-source models consistently outperform open-source counterparts, with GPT-Image-1 and Gemini2.5-Flash-Image achieving the highest overall scores. However, even top models exhibit weaknesses in Text rendering and Long Text tracks, indicating persistent challenges in typographic control and complex instruction following.
Track-Specific Insights
- Imagination: Closed-source models demonstrate superior creative synthesis, with open-source models lagging in surreal and abstract concept generation.
- Entity: High-fidelity rendering of real-world entities is dominated by models with robust knowledge bases.
- Text Rendering: All models struggle, with autoregressive architectures particularly weak, highlighting the need for specialized training and architectural innovations.
- Style: Most models achieve high fidelity to requested styles, indicating maturity in stylistic transfer.
- Affection: Top models effectively convey mood and emotion, with FLUX.1-dev excelling in aesthetic quality.
- Composition: Spatial arrangement and object interaction are well-handled by leading models, with open-source systems narrowing the gap.
- Long Text: Performance is universally lower, underscoring the difficulty of multi-layered reasoning and instruction following.
Bilingual Evaluation
PRISM-Bench-ZH reveals similar trends, with GPT-Image-1 leading across most tracks. SEEDream 3.0 and Qwen-Image show strong performance in Chinese text rendering, outperforming their English counterparts. The Long Text track remains the most challenging, especially for Chinese prompts, emphasizing the need for reasoning-focused datasets.
Implications and Future Directions
The release of FLUX-Reason-6M and PRISM-Bench democratizes access to high-quality, reasoning-oriented T2I data and evaluation tools. The explicit GCoT supervision and multidimensional annotation framework provide a foundation for training models with advanced reasoning capabilities. The benchmark's fine-grained, human-aligned evaluation protocol sets a new standard for assessing T2I models, revealing critical gaps and guiding future research.
Practically, the dataset enables the development of models capable of complex scene synthesis, creative interpretation, and robust instruction following. The persistent challenges in text rendering and long instruction adherence suggest avenues for architectural innovation, data augmentation, and targeted training. The bilingual nature of the dataset and benchmark facilitates cross-lingual research and model development.
Theoretically, the work advances the understanding of reasoning in generative models, highlighting the importance of structured supervision and multidimensional evaluation. Future developments may include expanding the GCoT framework, integrating reinforcement learning for reasoning, and exploring multimodal chain-of-thought supervision.
Conclusion
FLUX-Reason-6M and PRISM-Bench address foundational gaps in T2I research by providing a large-scale, reasoning-focused dataset and a comprehensive, fine-grained benchmark. Extensive evaluation demonstrates that while closed-source models lead in overall performance, significant challenges remain in text rendering and complex reasoning. The public release of data, benchmark, and code equips the research community to advance the state of T2I generation, fostering the development of models with deeper reasoning and broader capabilities.

