- The paper introduces a two-stage framework that employs a Python reference model to guide the correction of LLM-generated Verilog code.
- It leverages iterative testbench refinement and coverage-driven feedback to achieve high functional test coverage and reduce false positives.
- Empirical results on key benchmarks show that the framework, especially with GPT-4, significantly improves reliability over existing methods.
AutoVeriFix: Enhancing Functional Correctness in LLM-Generated Verilog Code
Introduction
AutoVeriFix introduces a two-stage, Python-assisted framework for improving the functional correctness of Verilog code generated by LLMs. The approach leverages the superior performance of LLMs in Python code generation to create a reference model, which is then used to guide and validate the generation of Verilog register-transfer level (RTL) implementations. This framework addresses the persistent challenge of functional errors in LLM-generated hardware description language (HDL) code, which are not adequately handled by existing syntactic correction methods. The methodology integrates automated testbench generation, coverage-driven feedback, and iterative error correction, resulting in substantial improvements in the reliability and correctness of generated Verilog code.
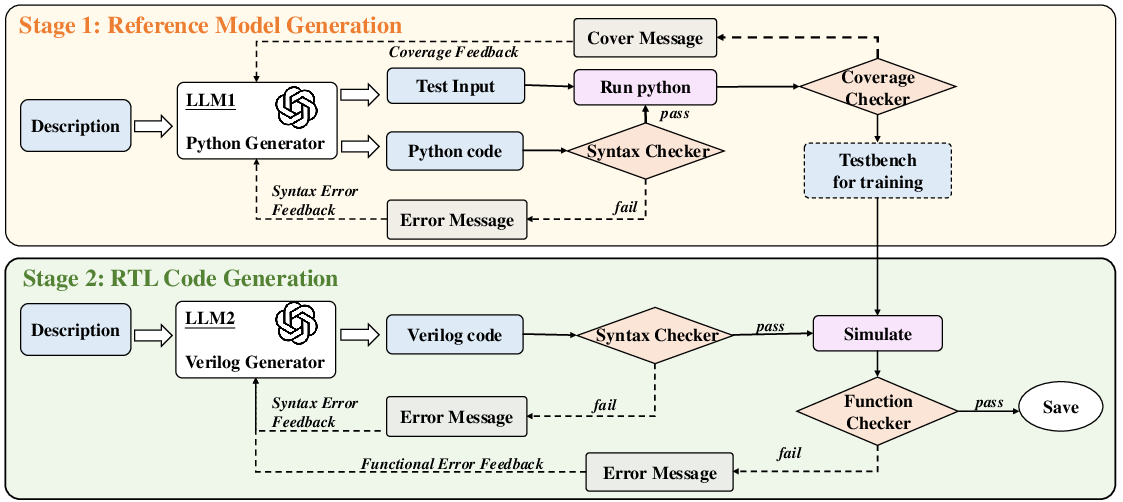
Figure 1: The two-stage framework of AutoVeriFix, illustrating Python reference model and testbench generation followed by iterative Verilog synthesis and correction.
Framework Overview
AutoVeriFix operates in two distinct stages. In the first stage, an LLM is prompted with a structured functional description of the hardware design and tasked with generating a Python reference model and an initial testbench comprising input-output pairs. The Python model serves as a functional oracle, exploiting the high accuracy of LLMs in Python code synthesis. The testbench is iteratively refined using coverage analysis, with feedback on uncovered branches provided to the LLM to enhance test input diversity and coverage.

Figure 2: Structured hardware description is used to prompt the LLM, which generates a Python class and initial test sequence.
Figure 3: Coverage feedback is used to iteratively refine test inputs, improving testbench thoroughness.
In the second stage, a separate LLM is used to generate Verilog code from the same hardware description. The generated Verilog is subjected to syntax checks and functional validation against the testbench. Discrepancies between the Verilog simulation outputs and the reference model are fed back to the LLM, enabling targeted correction of both syntactic and functional errors. This iterative process continues until the Verilog implementation aligns with the reference model's behavior.
Reference Model and Testbench Generation
The reference model generation leverages the LLM's proficiency in Python to produce a high-fidelity functional specification of the hardware. The initial testbench, derived from the reference model, typically exhibits suboptimal coverage. AutoVeriFix employs line and branch coverage metrics to identify inadequately tested functional paths. Feedback on uncovered code regions is provided to the LLM, which then generates additional test inputs to improve coverage. This process is repeated until a predefined coverage threshold (e.g., 85%) is achieved, ensuring that the testbench exercises a comprehensive set of functional scenarios.
Verilog Synthesis and Iterative Correction
Verilog code generation is initiated using the same hardware description. The LLM is prompted to produce a complete Verilog module, including combinational and sequential logic as well as state machine behavior.

Figure 4: Verilog code is synthesized from the hardware description using an LLM.
Syntax errors detected during compilation are reported to the LLM, which iteratively corrects the code until it passes all syntactic checks. Functional validation is performed by simulating the Verilog code with the testbench inputs and comparing the outputs to those of the Python reference model. Any mismatches are fed back to the LLM, which refines the Verilog implementation accordingly.

Figure 5: Syntax and functional error feedback are used to guide iterative correction of the Verilog code.
This feedback-driven loop continues until the Verilog code passes both syntactic and functional validation, substantially reducing the incidence of functional errors in the final implementation.
Experimental Results
AutoVeriFix was evaluated on the VerilogEval and RTLLM benchmarks, which include both human-crafted and LLM-generated hardware design tasks. The framework was implemented using GPT-3.5 and GPT-4 as the underlying LLMs. The Python reference models generated in Stage 1 exhibited near-perfect syntactic correctness and over 90% functional correctness across all benchmarks. Testbench coverage consistently exceeded 90%, indicating effective exercise of diverse functional scenarios.
In terms of Verilog code generation, AutoVeriFix achieved pass@10 scores of 84.6% (VerilogEval-human), 90.2% (VerilogEval-machine), and 83.5% (RTLLM v2.0) with GPT-4, outperforming both general-purpose commercial LLMs and domain-specific models such as OriGen and RTLCoder. Notably, AutoVeriFix with GPT-3.5 also surpassed most baselines, demonstrating the robustness of the framework even with less capable LLMs.
A critical metric, the false positive rate (FPR)—the proportion of designs passing testbench validation but failing functional correctness—was reduced to below 9% with GPT-4 and below 12% with GPT-3.5 when coverage feedback was employed. In contrast, omitting coverage feedback resulted in FPRs of 22–30%, underscoring the importance of iterative testbench refinement.
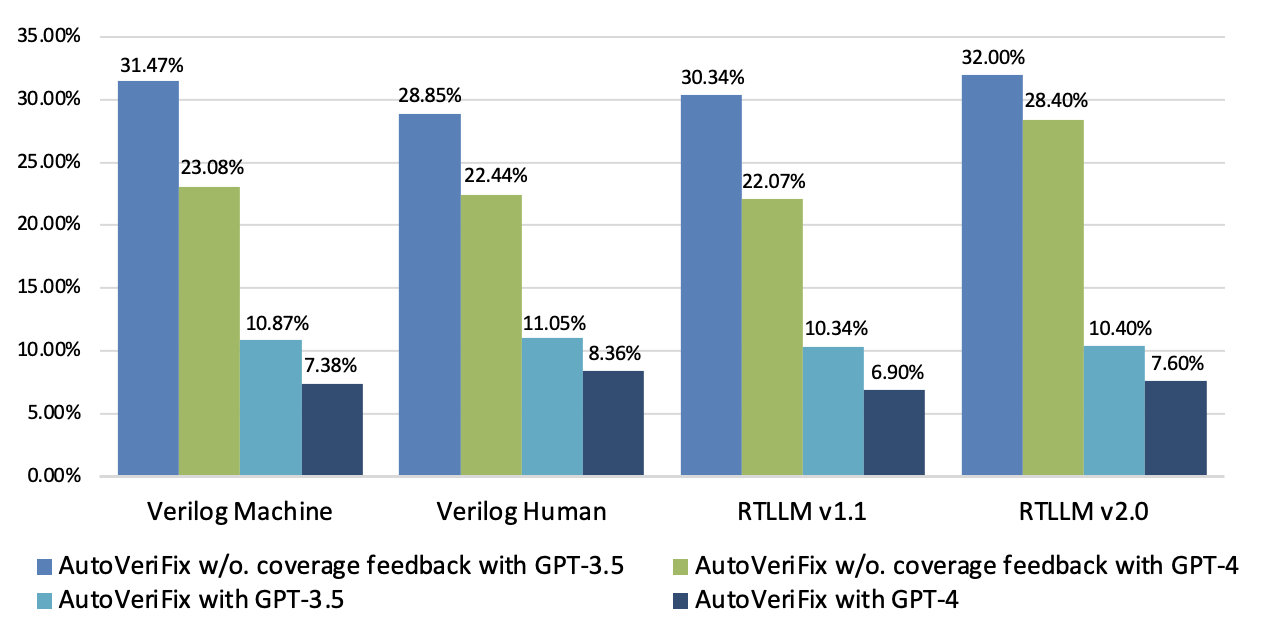
Figure 6: The percentage of designs passing testbench validation but failing functional correctness (FPR), highlighting the impact of coverage feedback.
Implications and Future Directions
AutoVeriFix demonstrates that leveraging LLMs for high-level reference model generation and coverage-driven testbench refinement can substantially improve the functional correctness of LLM-generated Verilog code. The framework's modularity allows for integration with various LLMs and hardware design flows. The approach mitigates the limitations of current syntactic correction methods, which fail to address deeper functional errors inherent in hardware code synthesis.
Practically, AutoVeriFix reduces the risk of undetected hardware logic bugs, lowering the cost and effort associated with post-silicon validation and rework. The methodology is extensible to other HDLs and could be adapted for more complex hardware verification tasks, including formal equivalence checking and property-based testing.
Theoretically, the results suggest that LLMs, when guided by high-level functional oracles and coverage-driven feedback, can approach the reliability required for automated hardware design. Future research may focus on integrating formal verification techniques, expanding the framework to support multi-language hardware flows, and developing specialized LLMs trained on curated HDL datasets to further enhance synthesis quality.
Conclusion
AutoVeriFix presents a robust two-stage framework for improving the functional correctness of LLM-generated Verilog code. By combining Python-based reference modeling, coverage-driven testbench refinement, and iterative feedback for both syntactic and functional errors, the approach achieves superior performance over existing methods. The framework's empirical results highlight its effectiveness in producing reliable hardware code, with significant reductions in functional errors and false positives. AutoVeriFix sets a new standard for LLM-assisted hardware code generation and provides a foundation for future advancements in automated electronic design automation.

