- The paper introduces EvolKV, an evolutionary algorithm that reformulates KV cache allocation as a multi-objective optimization problem to enhance task performance.
- The method applies CMA-ES in a group-wise setup, yielding non-uniform, task-aligned cache budgets that outperform static, rule-based baselines on benchmarks like LongBench and GSM8K.
- Experimental results demonstrate significant gains, including a 7.58 percentage point improvement on GSM8K and achieving competitive performance with only 1.5% of the original cache budget for specific tasks.
EvolKV: Evolutionary KV Cache Compression for LLM Inference
The memory and computational cost of KV cache retention in transformer-based LLMs scales linearly with input sequence length and quadratically with self-attention complexity, posing a significant bottleneck for long-context inference. Existing KV cache compression methods predominantly rely on static, rule-based heuristics—such as uniform cache allocation, fixed-position retention, or pyramidal attenuation—without accounting for the heterogeneous functional roles of transformer layers or the dynamic relationship between cache allocation and downstream task performance. This results in suboptimal retention of task-relevant information and degraded generalization.
EvolKV addresses these limitations by reformulating layer-wise KV cache budget allocation as a multi-objective black-box optimization problem, leveraging evolutionary algorithms to dynamically configure per-layer budgets in a task-driven manner. The framework operates on frozen LLMs, requires no fine-tuning or architectural modifications, and supports arbitrary evaluation metrics.
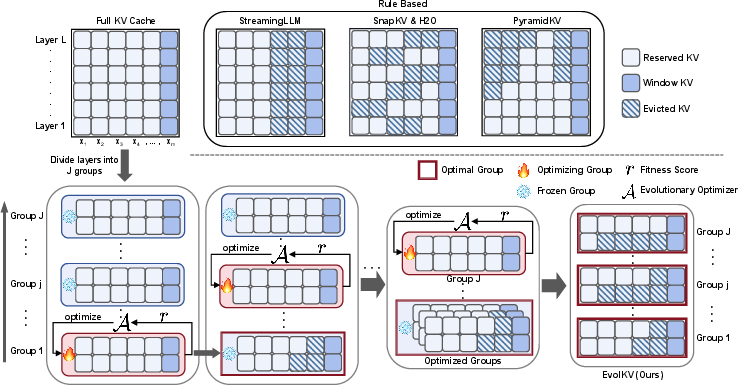
Figure 1: Illustration of the EvolKV framework. Compared to rule-based strategies (top row), EvolKV performs bottom-up, group-wise KV cache budget optimization using evolutionary search, progressively refining each layer group based on task-specific fitness feedback.
Methodology: Evolutionary Search for Layer-wise Cache Allocation
EvolKV models the per-layer KV cache budgets as optimization variables and partitions them into groups to reduce the search space. The evolutionary search (CMA-ES) iteratively refines group-wise configurations, directly maximizing downstream task fitness (e.g., accuracy, F1, ROUGE) while penalizing deviation from a target average cache budget. The objective function is:
$S^* = \arg\max_{S \in \mathbb{S}} f(S) \left(1 + \lambda\,\textproc{CacheScore}(S, c)\right)$
where f(S) is the downstream task performance, λ is a trade-off hyperparameter, and $\textproc{CacheScore}(S, c)$ penalizes budget overshoot or undershoot. The group-wise optimization proceeds sequentially, fixing previously optimized groups and updating the current group if a candidate scheme yields higher fitness.
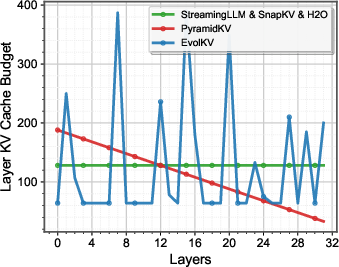
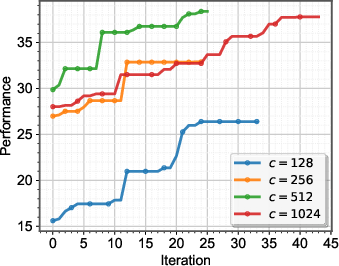
Figure 2: Comparison of EvolKV’s layer-wise KV cache budgets with existing KV cache compression methods.
EvolKV’s optimization trajectory reveals non-uniform, task-aligned cache allocation patterns that diverge from fixed or pyramidal heuristics. Notably, budget peaks often occur in middle layers, indicating computation bottlenecks for contextual inference, and the allocation varies substantially with the target budget.
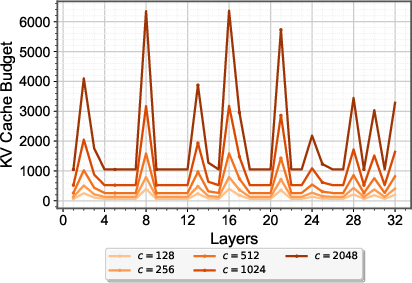
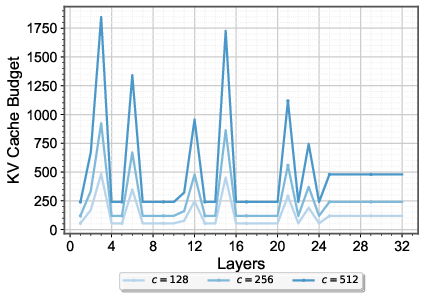
Figure 3: Mistral-7B-Instruct’s layer KV cache budgets optimized in 30 instances of NarrativeQA dataset.
Experimental Results: LongBench, GSM8K, NIAH, RULER
LongBench
EvolKV was evaluated on Mistral-7B-Instruct and Llama-3-8B-Instruct across 16 LongBench sub-datasets spanning six major task categories. At all KV cache budgets (128–2048), EvolKV consistently achieved the highest average performance, outperforming all rule-based baselines. On several sub-datasets (MultiFieldQA-en, 2WikiMultihopQA, MuSiQue, TriviaQA, PassageRetrieval-en), EvolKV even surpassed the full model’s performance at certain budgets, notably achieving superior code completion with only 1.5% of the original cache budget.
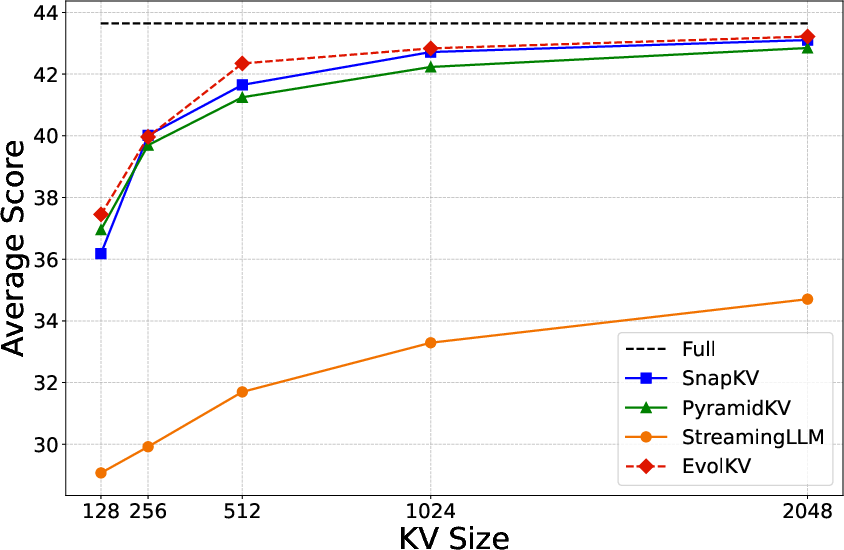
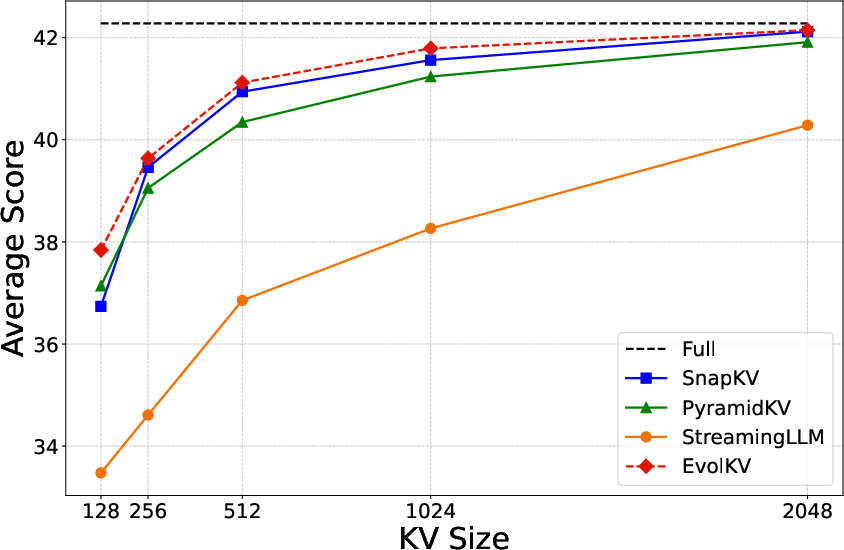
Figure 4: Average performance comparison across six major task categories in LongBench between baseline methods and EvolKV on Mistral-7B-Instruct.
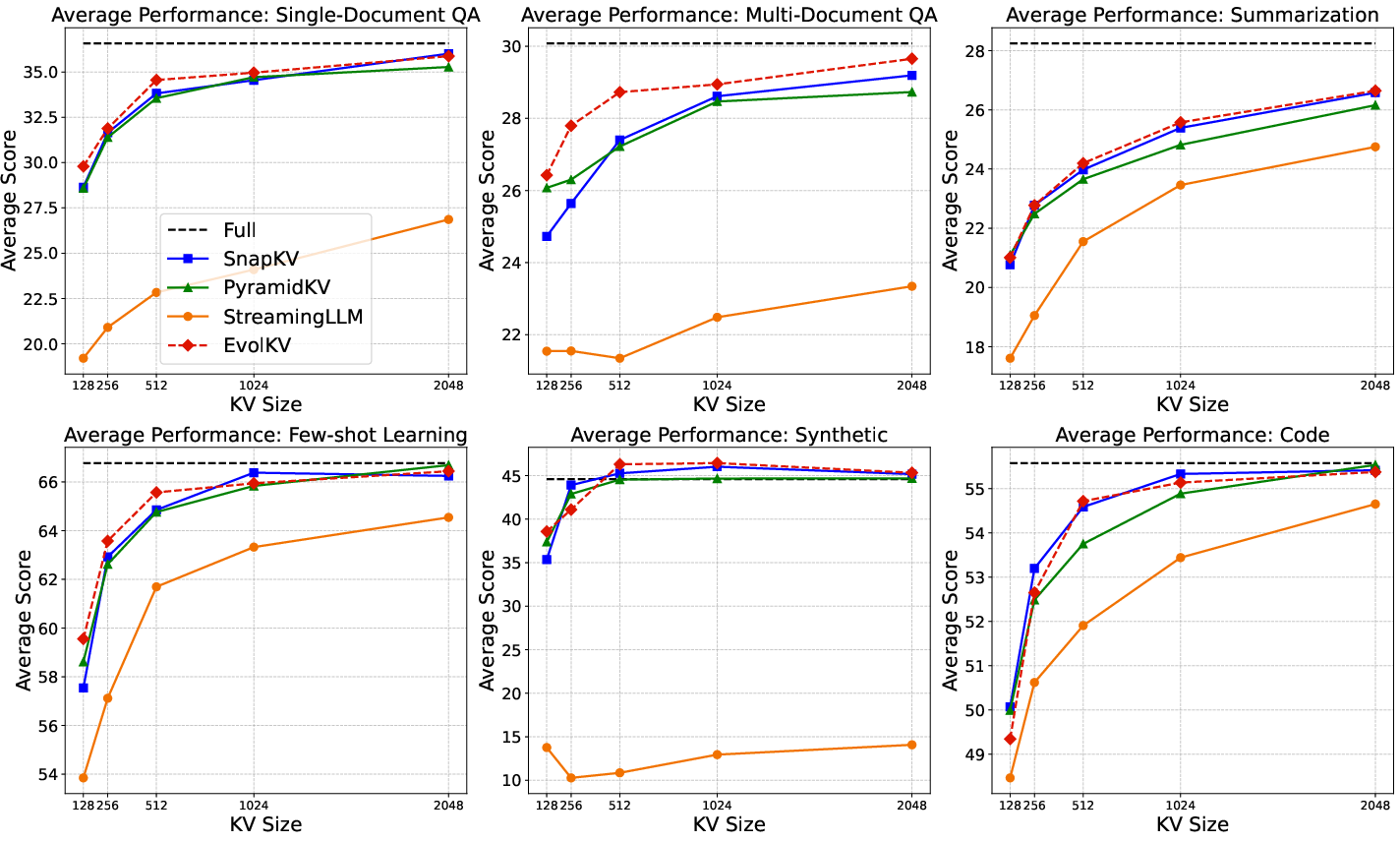
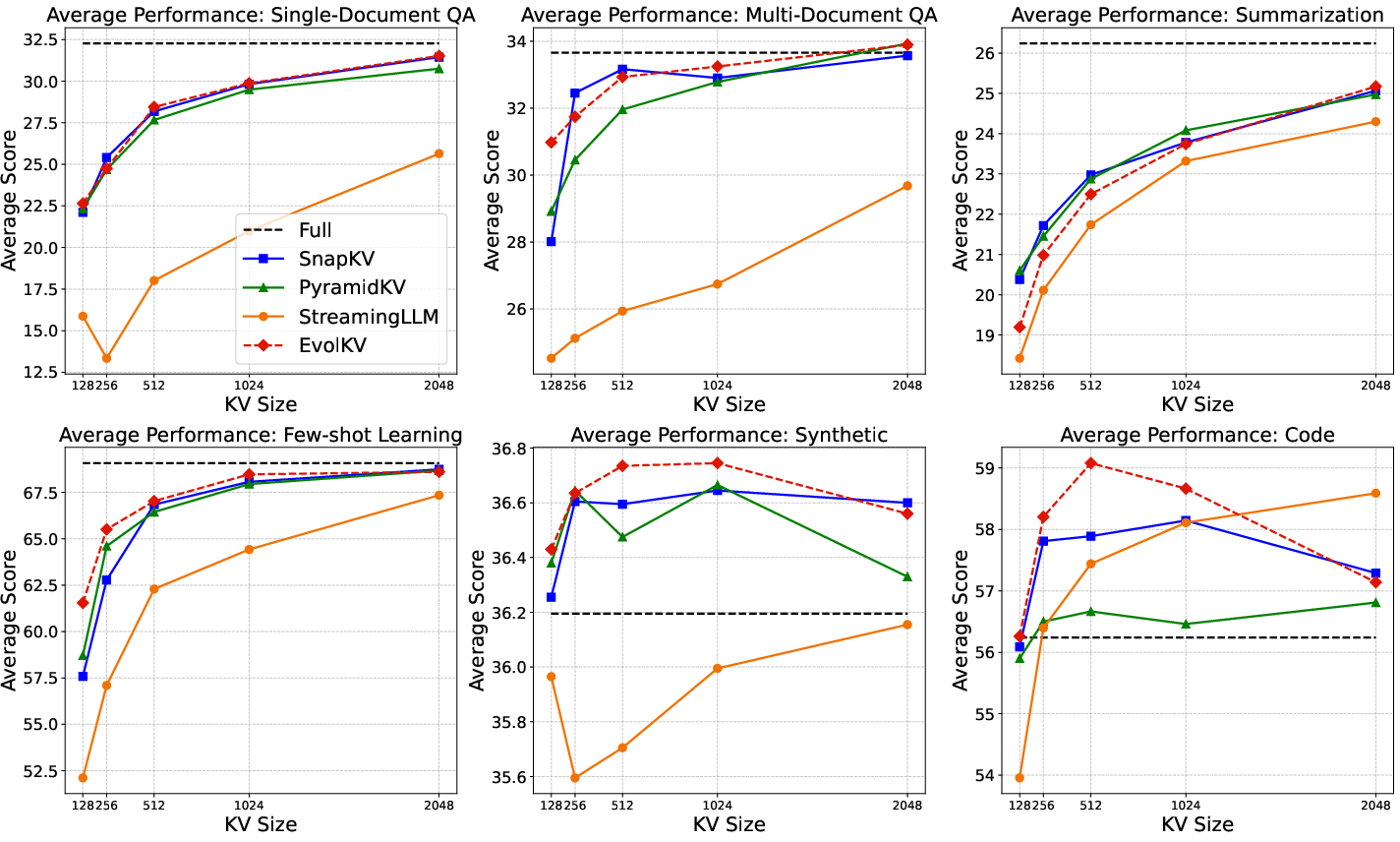
Figure 5: Comparison between baseline methods and EvolKV on Mistral-7B-Instruct across six major task categories in LongBench.
GSM8K
On GSM8K, EvolKV demonstrated strong logical reasoning under constrained budgets. For Llama-3-8B-Instruct, EvolKV achieved up to 7.28, 2.05, and 7.58 percentage point improvements over the strongest baseline at budgets of 128, 256, and 512, respectively, retaining 95.7% of full-model performance at c=512 (versus 84.5% for the best baseline).
NIAH and RULER
On NIAH, EvolKV outperformed baselines by over 13 percentage points on Mistral-7B-Instruct and 4 points on Llama-3-8B-Instruct at c=128. The optimized budgets generalized effectively to RULER, yielding up to 3.6 point gains over the strongest baseline, demonstrating robust long-context retrieval and reasoning.
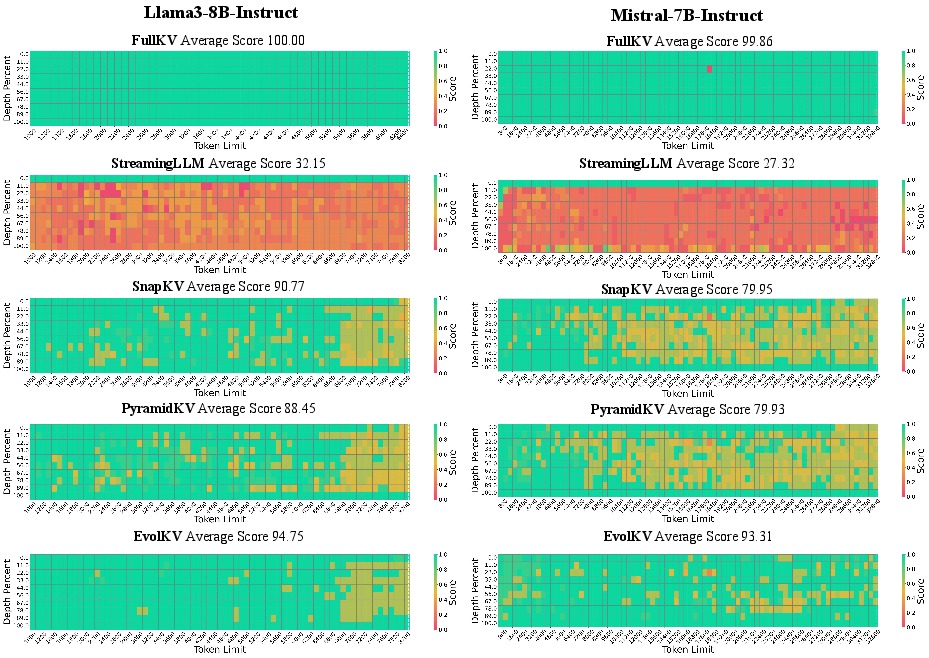
Figure 6: Evaluation of Llama-3-8B-Instruct and Mistral-7B-Instruct on NIAH at a KV cache budget of 128.
Ablation and Analysis
Group Size and Optimization Dynamics
Performance peaks at a group size of ng=8, balancing optimization efficiency and granularity. Smaller groups risk overfitting to limited data, while larger groups hinder fine-grained allocation.
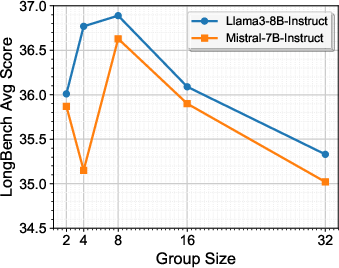
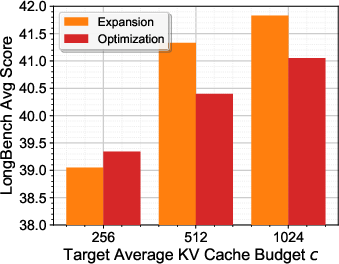
Figure 7: Comparison results of different group sizes.
Generalization and Robustness
KV cache budgets optimized under strict constraints generalize smoothly to larger budgets and across datasets, outperforming direct optimization at higher budgets. EvolKV exhibits stable optimization dynamics and strong adaptability to diverse downstream tasks and model series (e.g., Qwen).
Inference Time and Memory
EvolKV incurs negligible overhead in inference time and peak memory usage compared to other compression methods, while significantly reducing memory consumption relative to full cache retention.
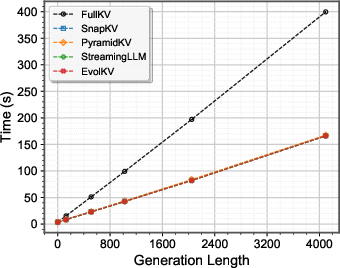
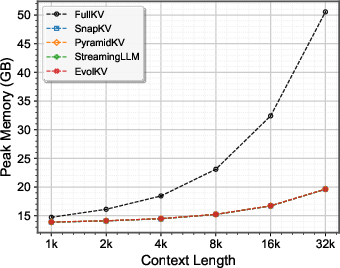
Figure 8: Comparison results of inference time.
Implications and Future Directions
EvolKV demonstrates that evolutionary, task-aware cache budget allocation uncovers latent layer-importance patterns overlooked by heuristic methods, enabling efficient inference in LLMs under stringent memory constraints. The plug-and-play nature of the framework, requiring only a handful of labeled examples and no model modification, makes it practical for real-world deployment.
The results challenge the prevailing assumption that fixed or pyramidal cache allocation is optimal, showing that non-uniform, task-driven strategies can yield superior performance—even surpassing the full model under extreme compression. This has implications for scalable LLM deployment in resource-constrained environments and motivates further research into fine-grained cache allocation, such as attention-head-level budgets and tokenization-free approaches.
Conclusion
EvolKV provides a principled, adaptive solution for layer-wise KV cache compression in LLM inference, consistently outperforming rule-based baselines and achieving state-of-the-art results across a range of tasks and budgets. Its evolutionary optimization framework is robust, generalizes across tasks and models, and is efficient in both computation and memory. Future work should explore attention-head-level budget allocation and the interaction of cache compression with tokenization schemes.