- The paper introduces AgentX, which employs hierarchical planning and strict agent roles to decompose tasks, optimize context, and reduce token consumption.
- The paper demonstrates that FaaS-based MCP deployments enhance scalability and cost efficiency, though they may introduce latency trade-offs compared to local setups.
- The paper benchmarks AgentX against SOTA patterns, revealing competitive accuracy, reduced tool invocations, and improved cost performance in complex, tool-rich tasks.
AgentX: Orchestrating Robust Agentic Workflow Patterns with FaaS-hosted MCP Services
Introduction and Motivation
The paper introduces AgentX, a novel agentic workflow pattern designed to address the limitations of existing agentic AI systems in orchestrating complex, multi-step tasks with tool use, particularly in environments with numerous tools and long-context requirements. The work also presents a systematic approach to deploying Model Context Protocol (MCP) servers as Functions as a Service (FaaS), enabling scalable, cloud-native tool integration for agentic workflows. The empirical evaluation benchmarks AgentX against state-of-the-art (SOTA) agentic patterns—ReAct and Magentic-One—across multiple real-world applications, analyzing accuracy, latency, cost, and resource utilization in both local and FaaS-based MCP deployments.
Agentic Workflow Patterns: Design and Distinctions
Agentic patterns define the execution logic for LLM-driven agents interacting with external tools. The paper contrasts three major patterns: ReAct, Magentic-One, and the proposed AgentX.
- ReAct interleaves reasoning and action in a single agent, maintaining a linear context and relying on iterative tool use and observation.
- Magentic-One employs a multi-agent architecture with an orchestrator delegating to specialized agents, each with access to specific tools.
- AgentX introduces a hierarchical, multi-agent workflow: a Stage Generation Agent decomposes the user prompt into stages, a Planner Agent generates detailed plans for each stage, and an Executor Agent executes the plan, invoking tools and consolidating context.
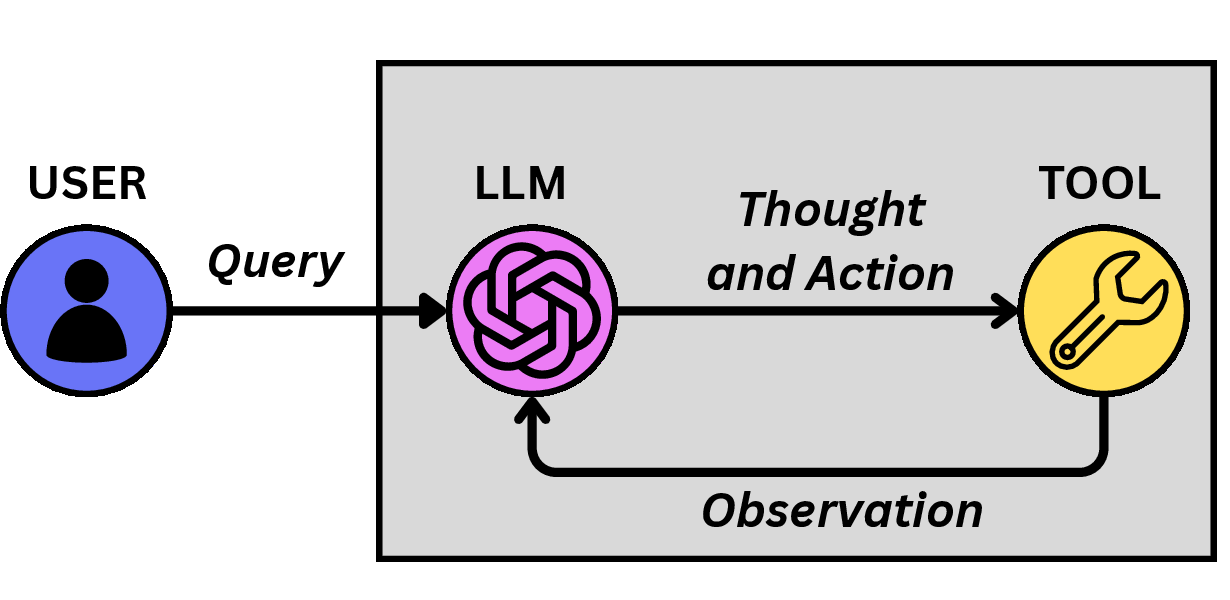
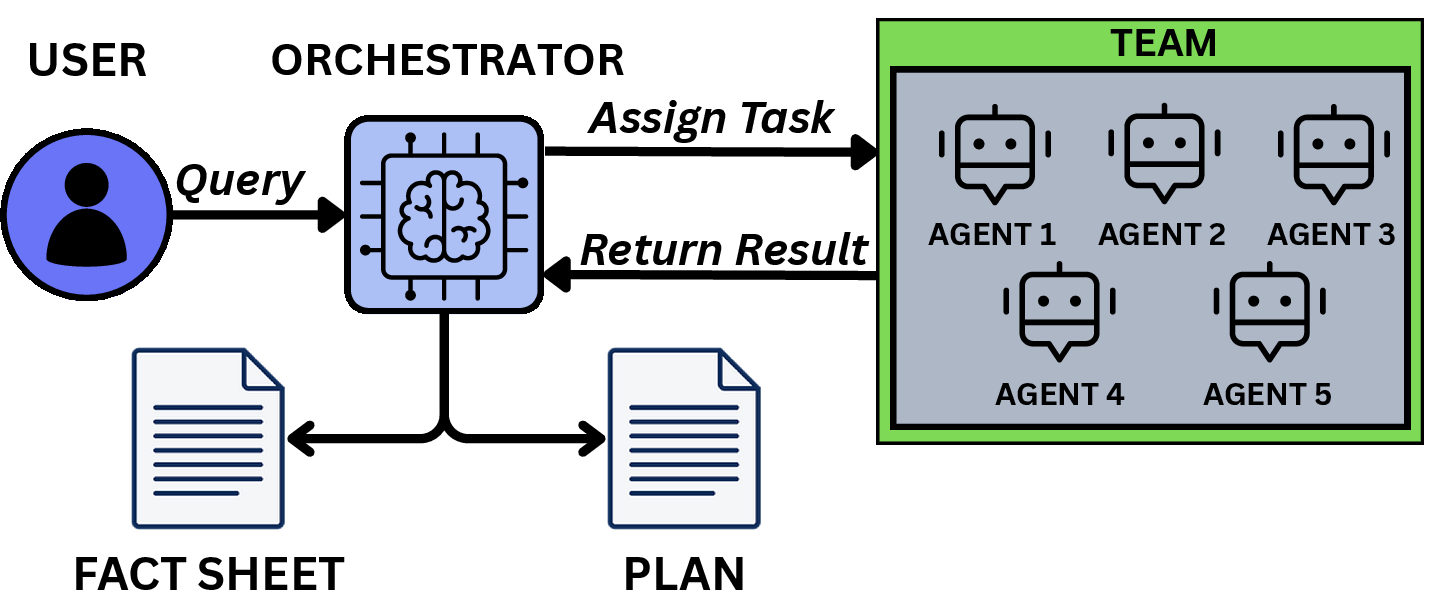
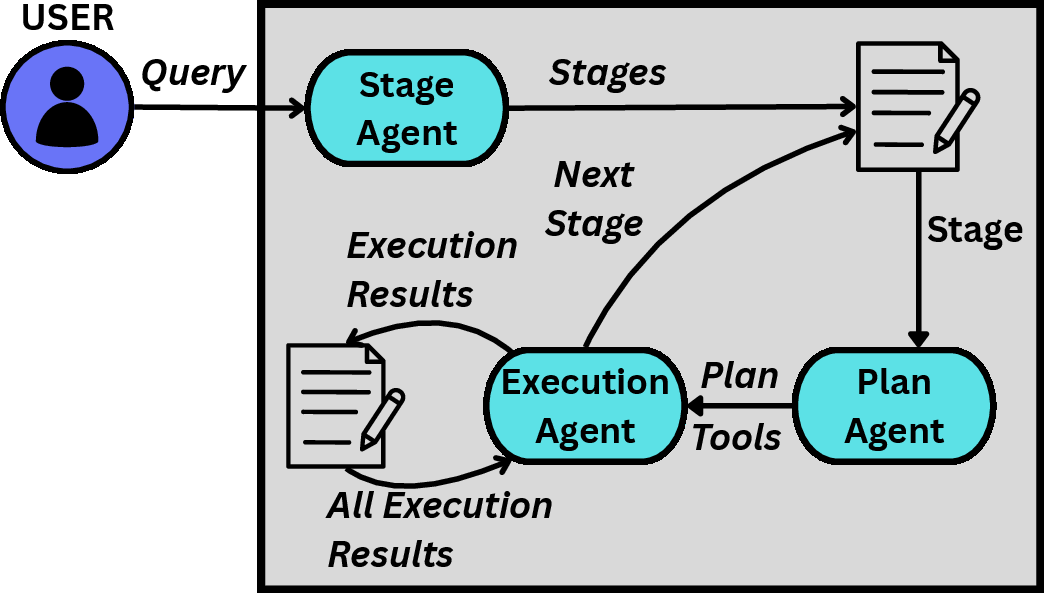
Figure 1: Agentic workflow patterns for ReAct, Magentic-One, and AgentX, highlighting their structural differences.
AgentX's key innovations are:
- Hierarchical planning: Decomposition of tasks into stages and sub-steps, improving robustness and modularity.
- Strict agent roles and tool filtering: Each agent has a well-defined function, and the Planner restricts tool exposure to the Executor, reducing cognitive load and hallucination risk.
- Active context optimization: After each stage, the Executor summarizes relevant information, preventing context bloat and reducing token costs.
MCP Server Deployment: Local vs. FaaS Architectures
MCP provides a standardized protocol for exposing tools to LLM agents. The paper evaluates two deployment models:
- Local MCP servers: Tools are hosted on the same machine as the agentic workflow, requiring manual setup and dependency management.
- FaaS-hosted MCP servers: Tools are containerized and deployed as AWS Lambda functions, supporting both monolithic (all tools in one function) and distributed (one function per tool) architectures.
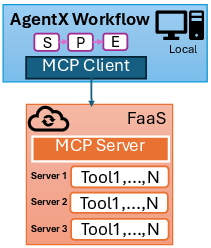
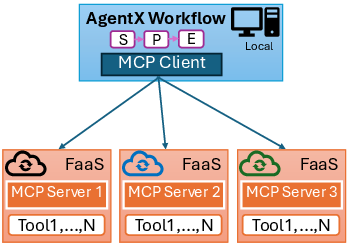
Figure 2: MCP deployment architectures: (a) local servers, (b) monolithic FaaS, and (c) distributed FaaS.
The distributed FaaS approach, evaluated in the paper, enables fine-grained scaling and isolation but introduces deployment complexity and potential cold-start latency. Statefulness is managed via session IDs persisted in DynamoDB, and tool outputs are redirected to S3 to accommodate the stateless nature of Lambda.
Application Workflows and Experimental Setup
Three application templates are used for benchmarking:
- Web Exploration: Search and summarize web content.
- Stock Correlation: Retrieve historical stock data and generate comparative plots.
- Research Report Generation: Download, analyze, and summarize research papers using RAG.
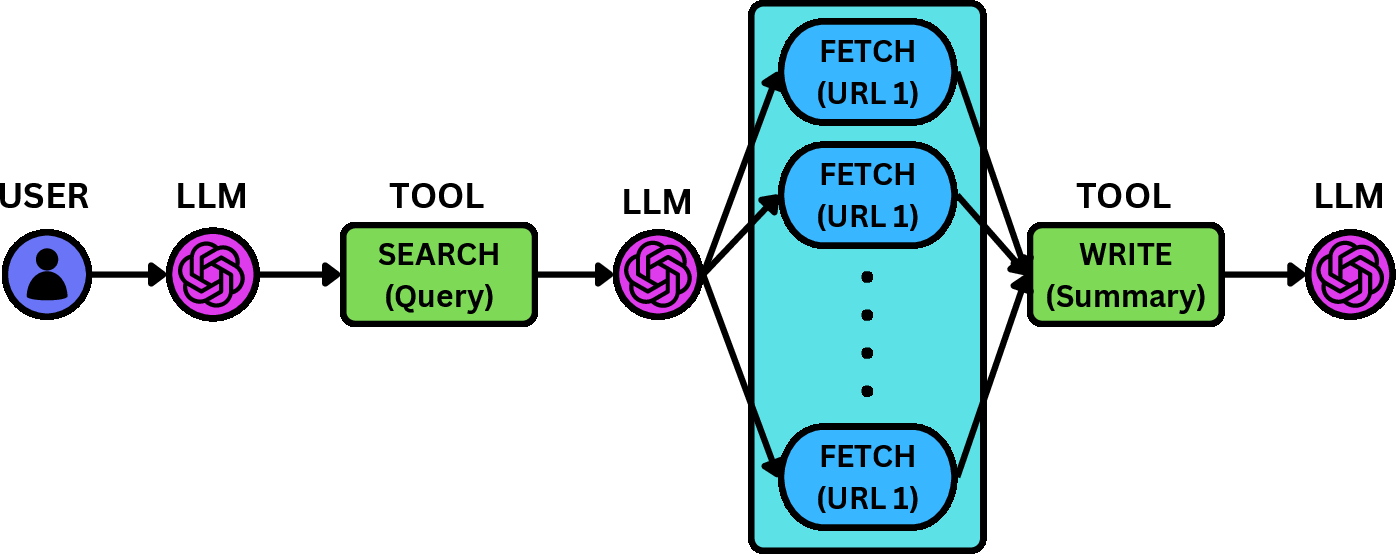
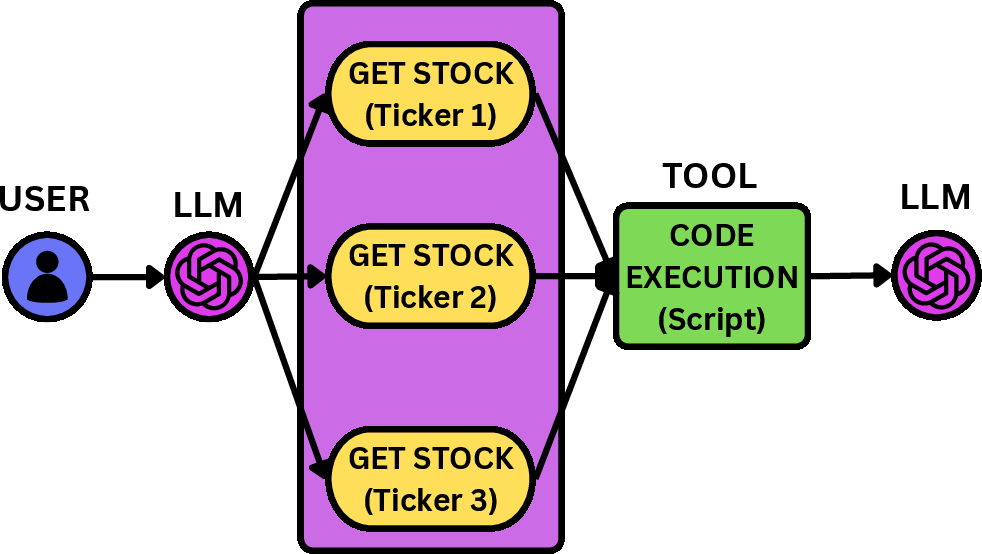
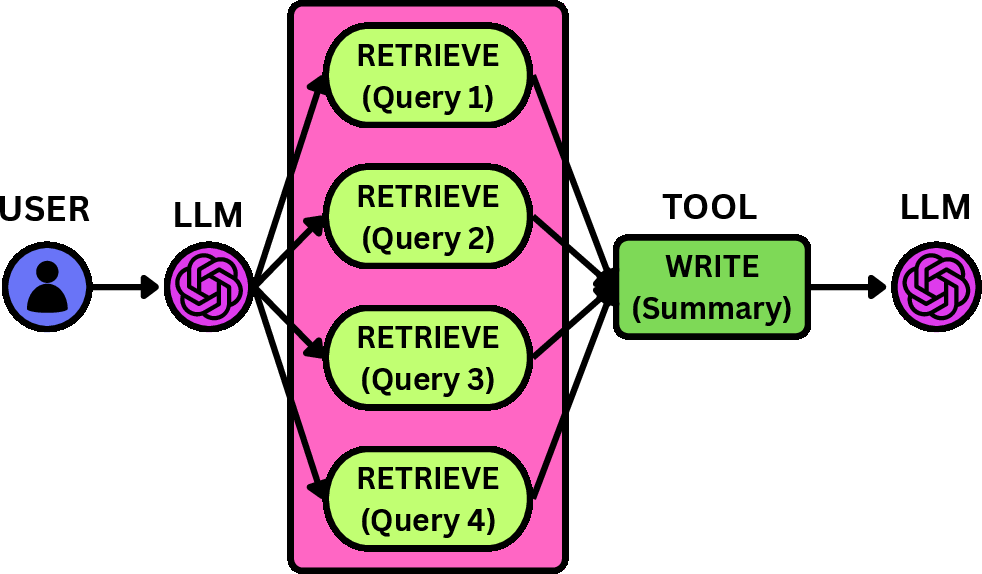
Figure 3: Expected workflow execution behavior for the three applications: web exploration, stock correlation, and research report generation.
Each application is instantiated with multiple prompts, and each agentic pattern is evaluated across both local and FaaS MCP deployments. All experiments use OpenAI's GPT-4o-mini model with a 128k token context window.
Empirical Results
Accuracy
AgentX achieves accuracy scores competitive with or superior to ReAct and Magentic-One in most tasks. For web search and research report applications, all patterns perform similarly (AgentX: 86.7, ReAct: 86.1, Magentic-One: 89.1 for web search). For stock correlation, AgentX and ReAct outperform Magentic-One by 28.9% and 38.8%, respectively, due to Magentic-One's tendency to truncate or fabricate data.
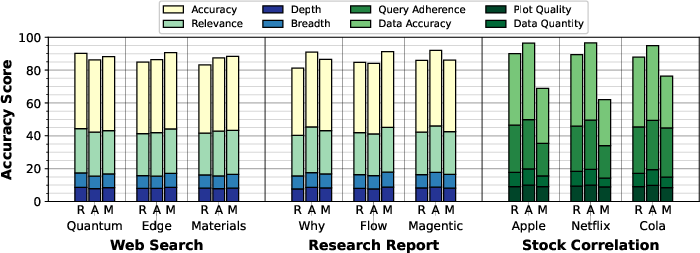
Figure 4: Average accuracy scores for all runs, decomposed by evaluation attribute.
Latency
AgentX generally incurs higher latency than ReAct but is faster than Magentic-One, except in stock correlation where Magentic-One's data truncation reduces its latency at the expense of accuracy. The majority of latency in AgentX is due to LLM inference, especially in applications with minimal tool computation.
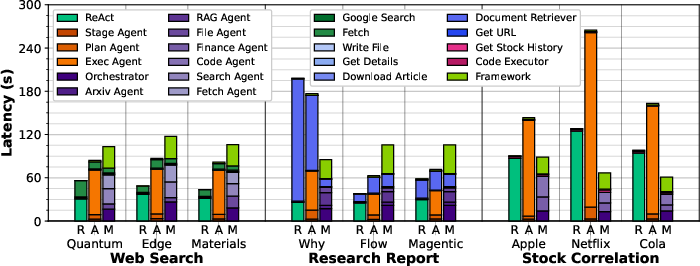
Figure 5: Average latency to complete applications across 5 runs for local executions.
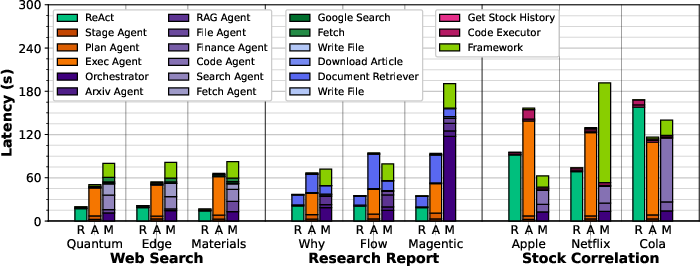
Figure 6: Average latency to complete applications across 5 runs for FaaS executions.
Tool execution latency is higher in FaaS for compute-intensive tools (e.g., code execution), but some remote tools (e.g., document retrieval) are faster due to cloud infrastructure variability.
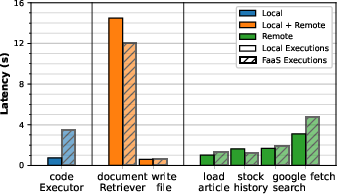
Figure 7: Tool execution latency comparison across local and FaaS deployments.
Success Rate
ReAct achieves 100% success across all applications in local experiments, while AgentX and Magentic-One have lower rates (e.g., AgentX: 80% for web search, 66% for stock correlation). Failures in AgentX and Magentic-One are attributed to context-passing errors, tool misuse, and lack of robust recovery mechanisms.
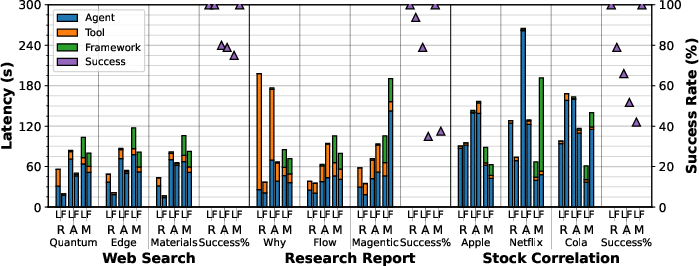
Figure 8: Overall latency and success rate comparison between local and FaaS executions.
Token and Cost Analysis
AgentX consistently consumes fewer input tokens than ReAct and Magentic-One in web search, due to optimized planning and selective tool use. Output token counts are higher in AgentX due to explicit stage summaries, but this reduces downstream input token requirements.
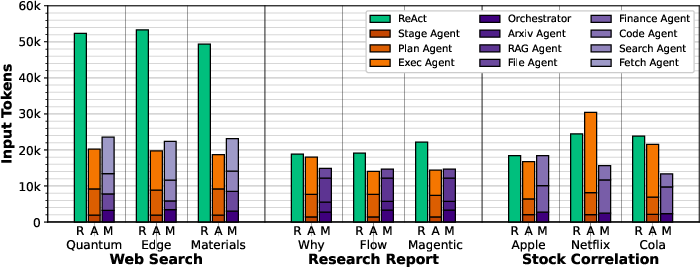
Figure 9: Average input tokens consumed for local executions.
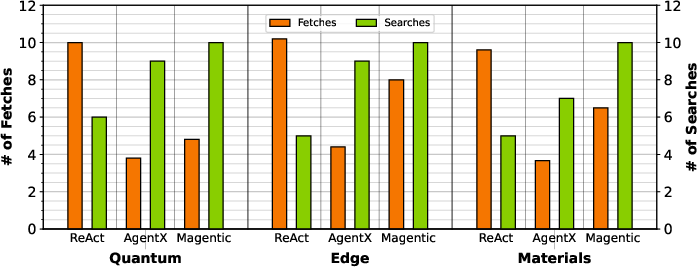
Figure 10: Number of fetches and search results requested by agentic patterns locally.
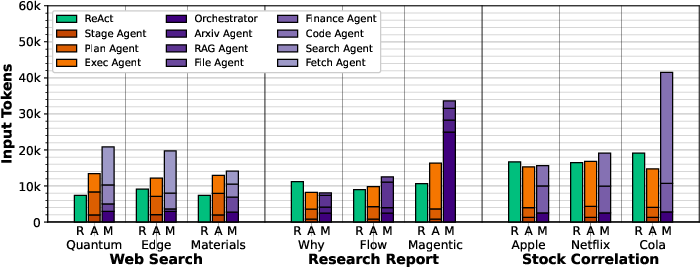
Figure 11: Average input tokens consumed for FaaS executions.
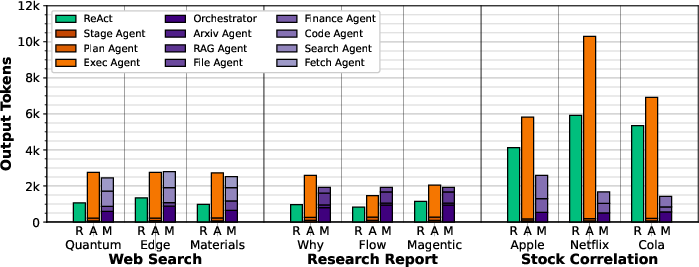
Figure 12: Average output tokens generated for local executions.
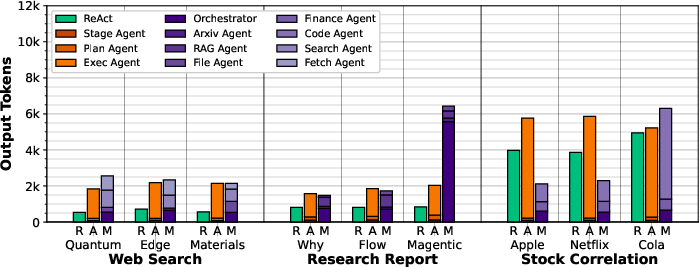
Figure 13: Average output tokens generated for FaaS executions.
AgentX achieves up to 45.7% lower LLM inference cost than ReAct in web search. FaaS cloud costs are negligible compared to LLM inference costs, being two orders of magnitude lower.
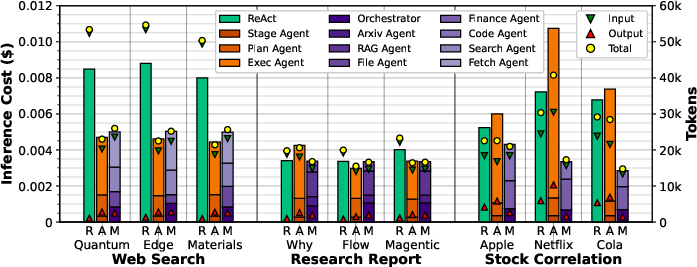
Figure 14: Cost from LLM invocations in local experiments.
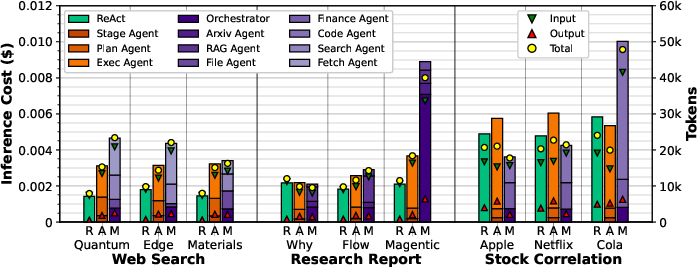
Figure 15: Cost from LLM invocations in FaaS experiments.
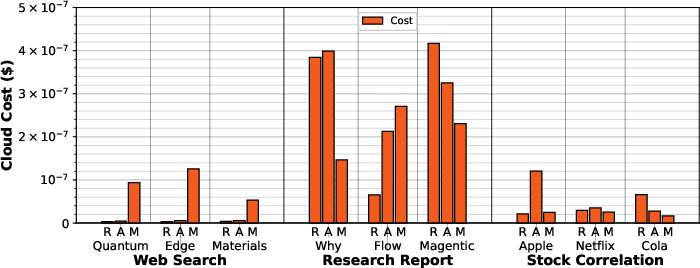
Figure 16: Cloud cost from FaaS MCP server invocations.
AgentX triggers fewer tool invocations and agent inferences than Magentic-One, and significantly fewer than ReAct in verbose tasks, due to its hierarchical planning and context summarization.
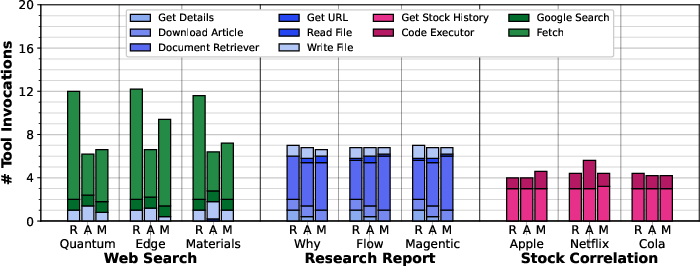
Figure 17: Average tool invocations for local experiments.
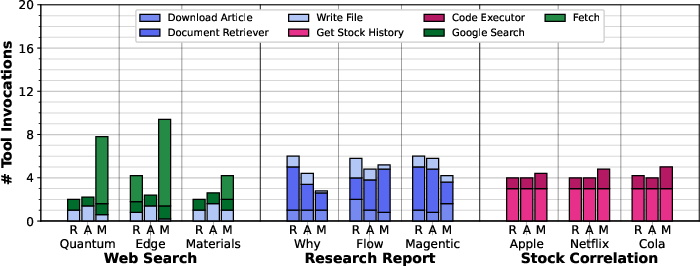
Figure 18: Average tool invocations for FaaS experiments.
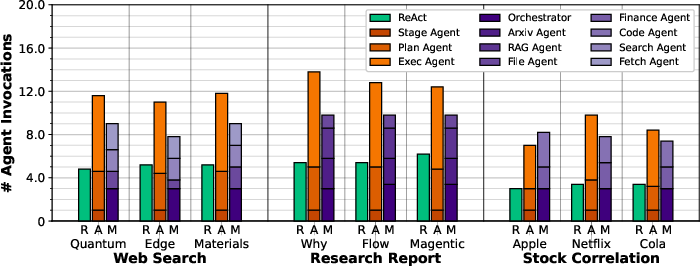
Figure 19: Average agent invocations for local experiments.
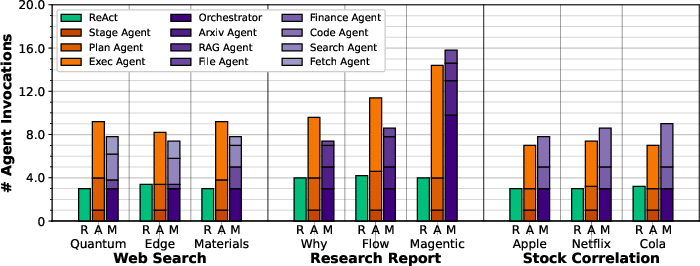
Figure 20: Average agent invocations for FaaS experiments.
Discussion and Observations
- AgentX's hierarchical decomposition reduces token and tool usage but introduces new failure modes, such as redundant or missing stages, and lacks a robust recovery system.
- ReAct's monolithic context leads to higher token costs and redundant tool calls, but its retry mechanism ensures high success rates.
- Magentic-One's agent specialization can result in context loss between agents, leading to data truncation or dummy outputs, especially in tasks requiring data handoff.
- FaaS deployment introduces additional latency for compute-bound tools and requires adaptation for stateless execution (e.g., S3 for file I/O), but offers scalability and operational simplicity.
- Tool description quality is critical; vague or incomplete descriptions lead to tool misuse or underutilization, especially in FaaS where only a subset of tools may be exposed.
Implications and Future Directions
The AgentX pattern demonstrates that hierarchical, role-specialized agentic workflows can achieve competitive or superior accuracy and cost efficiency compared to SOTA baselines, particularly in tasks with complex tool orchestration and long context requirements. However, the lack of built-in recovery and the potential for stage misalignment highlight the need for further research into robust error handling and dynamic workflow adaptation.
The FaaS-based MCP deployment model is viable for scalable, cloud-native agentic applications, but requires careful engineering to handle state, dependencies, and tool selection. The negligible cloud cost relative to LLM inference suggests that future optimization should focus on reducing token usage and improving agentic planning.
Potential future work includes:
- Integrating explicit recovery and self-correction mechanisms into AgentX.
- Enabling parallel execution of independent stages to reduce latency.
- Automating MCP server deployment and tool selection in hybrid cloud environments.
- Extending evaluation to more complex, dynamic workflows and a broader range of LLMs, including on-premise and privacy-sensitive deployments.
Conclusion
AgentX advances the design of agentic workflow patterns by introducing hierarchical planning, strict agent role separation, and active context management, yielding improved cost efficiency and competitive accuracy in complex, tool-rich tasks. The systematic evaluation of FaaS-hosted MCP servers demonstrates the feasibility and trade-offs of serverless tool integration for agentic AI. The findings underscore the importance of workflow architecture, tool description quality, and deployment strategy in achieving robust, scalable, and cost-effective agentic systems. Further research is warranted to address recovery, parallelism, and dynamic adaptation in agentic workflows, as well as to generalize these findings across diverse LLM backends and application domains.