Language-agnostic BERT Sentence Embedding
Abstract: While BERT is an effective method for learning monolingual sentence embeddings for semantic similarity and embedding based transfer learning (Reimers and Gurevych, 2019), BERT based cross-lingual sentence embeddings have yet to be explored. We systematically investigate methods for learning multilingual sentence embeddings by combining the best methods for learning monolingual and cross-lingual representations including: masked language modeling (MLM), translation language modeling (TLM) (Conneau and Lample, 2019), dual encoder translation ranking (Guo et al., 2018), and additive margin softmax (Yang et al., 2019a). We show that introducing a pre-trained multilingual LLM dramatically reduces the amount of parallel training data required to achieve good performance by 80%. Composing the best of these methods produces a model that achieves 83.7% bi-text retrieval accuracy over 112 languages on Tatoeba, well above the 65.5% achieved by Artetxe and Schwenk (2019b), while still performing competitively on monolingual transfer learning benchmarks (Conneau and Kiela, 2018). Parallel data mined from CommonCrawl using our best model is shown to train competitive NMT models for en-zh and en-de. We publicly release our best multilingual sentence embedding model for 109+ languages at https://tfhub.dev/google/LaBSE.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LaBSE, which stands for Language-agnostic BERT Sentence Embedding. In simple terms, it’s a tool that turns sentences from more than 100 different languages into numbers (called “embeddings”) so that sentences with the same meaning end up close together—even if they’re written in different languages. This helps computers match translations, search across languages, and use the same text features for many tasks.
What questions were the researchers trying to answer?
- Can we build one model that works well for sentence meaning across many languages (over 100), not just English?
- Can using a big pre-trained LLM (like BERT) help us learn better cross-language sentence representations with much less training data?
- Which training tricks—like special loss functions or pretraining tasks—actually make a difference?
How did they do it? (methods explained simply)
Think of the model like two friendly translators who learn to think alike:
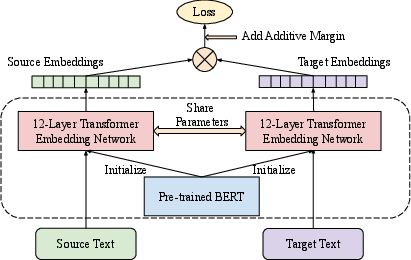
- Dual encoder: There are two identical “readers” (neural networks) that each read one sentence—one in language A and one in language B. They each turn their sentence into a vector (a long list of numbers). If the two sentences are translations, their vectors should be very close; if not, they should be far apart.
- Pretraining with word puzzles:
- Masked Language Modeling (MLM): The model reads sentences with some words hidden and learns to guess the missing words—like fill-in-the-blank games.
- Translation Language Modeling (TLM): The model gets a sentence and its translation stuck together, with some words hidden, and uses both languages as clues to guess the missing words. This teaches the model how languages align.
- Training to rank correct translations:
- The model sees a batch of sentence pairs (true translations). For each source sentence, it must pick which target sentence is the correct translation from many choices. The wrong ones in the batch act as “negatives” (distractors).
- Additive Margin Softmax: Imagine you’re not just telling the model “pick the right pair,” but also “keep the correct pair at least this far apart from the wrong ones.” That “safety gap” (the margin) makes the model’s decisions clearer.
- More and harder practice:
- Cross-accelerator negative sampling: When training across many chips (TPUs/GPUs), they share all the wrong answers across chips to create a bigger, tougher set of distractors in each step. This makes the model learn stronger distinctions without needing huge memory on a single chip.
In short, they first teach the model language basics using huge text (pretraining), then fine-tune it to match translations with smart scoring and lots of tricky comparisons.
What did they find, and why is it important?
Here are the main results, explained briefly:
- Stronger across 100+ languages: On a big test called Tatoeba (112 languages), LaBSE correctly matched translations 83.7% of the time, beating a previous popular system (LASER) that got 65.5%. It did especially well for low-resource languages (languages with little training data).
- Works even for unseen languages: Surprisingly, LaBSE worked pretty well (around 60% average accuracy) on 30+ languages it wasn’t explicitly trained on. This suggests the model learns language patterns that transfer across similar languages.
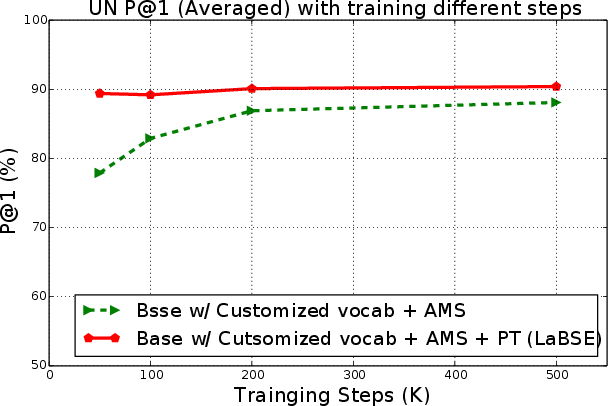
- Needs much less parallel data: Using a large pre-trained multilingual model cut the required “parallel data” (pairs of translated sentences) by about 80%. In other words, it can reach good performance using only about one-fifth as much expensive translation data.
- Best-in-class on several retrieval tasks: It beat strong baselines on:
- UN dataset (millions of sentence pairs from UN documents)
- BUCC shared task (finding matching sentences across two languages in large text collections)
- Competitive on English tasks: On English-only transfer tasks (like sentiment classification), it performed competitively with other sentence embedding models, even though its main goal is multilingual work. On fine-grained English similarity (STS), it wasn’t the best—likely because it’s optimized for “are these translations?” rather than “how similar are these sentences on a 0–5 scale?”
- Finds real translation data on the web: Using LaBSE to mine translation pairs from CommonCrawl (a huge web snapshot), they trained translation systems (English–German and English–Chinese) that reached quality close to strong systems trained on hand-collected datasets. This shows LaBSE can help build translation data automatically.
Why does this matter?
- Cross-language search and matching: LaBSE makes it easy to search for a sentence’s meaning across many languages. This helps with translation tools, multilingual search engines, and organizing information from around the world.
- Helps low-resource languages: Because it shares knowledge across 100+ languages and needs less parallel data, it can improve tools for languages that don’t have many resources.
- Builds better datasets: It can automatically find good translation pairs on the web, which then improves machine translation and other multilingual AI systems.
- One model for many languages: Instead of building a separate model for each language pair, LaBSE is a single model that supports 109+ languages, simplifying deployment and maintenance.
A quick recap
- Main idea: Train a multilingual BERT-based model (LaBSE) that turns sentences into language-agnostic vectors—so translations are close together.
- Key ingredients: Pretraining with MLM/TLM, dual encoders, smart ranking with a margin, and big-batch negative sampling across accelerators.
- Big wins: State-of-the-art translation retrieval across many languages, strong results on low-resource and even unseen languages, and much less reliance on expensive human-made parallel data.
- Real-world impact: Better multilingual search, mining, and translation systems. The model is publicly available at https://tfhub.dev/google/LaBSE.
Collections
Sign up for free to add this paper to one or more collections.