- The paper introduces a novel online 3D reconstruction framework using a sliding-window token interaction mechanism and a global camera token pool for robust pose estimation.
- It employs a transformer-based decoder with overlapping windows to refine predictions and enhance temporal consistency without excessive memory costs.
- Experiments show state-of-the-art accuracy at real-time speeds (17 FPS) across various benchmarks, highlighting its potential for AR/VR and robotics applications.
WinT3R: Window-Based Streaming Reconstruction with Camera Token Pool
Introduction
WinT3R introduces a feed-forward, online 3D reconstruction framework that addresses the persistent trade-off between reconstruction quality and real-time performance in streaming multi-view geometry. The method leverages a sliding-window token interaction mechanism and a global camera token pool to enable high-fidelity geometry and camera pose estimation at real-time speeds. This approach is motivated by the observation that adjacent frames in a video stream are highly correlated, and that compact camera token representations can efficiently encode global scene information for robust pose estimation. WinT3R achieves state-of-the-art results across a range of benchmarks, demonstrating both superior accuracy and efficiency compared to prior online and offline methods.
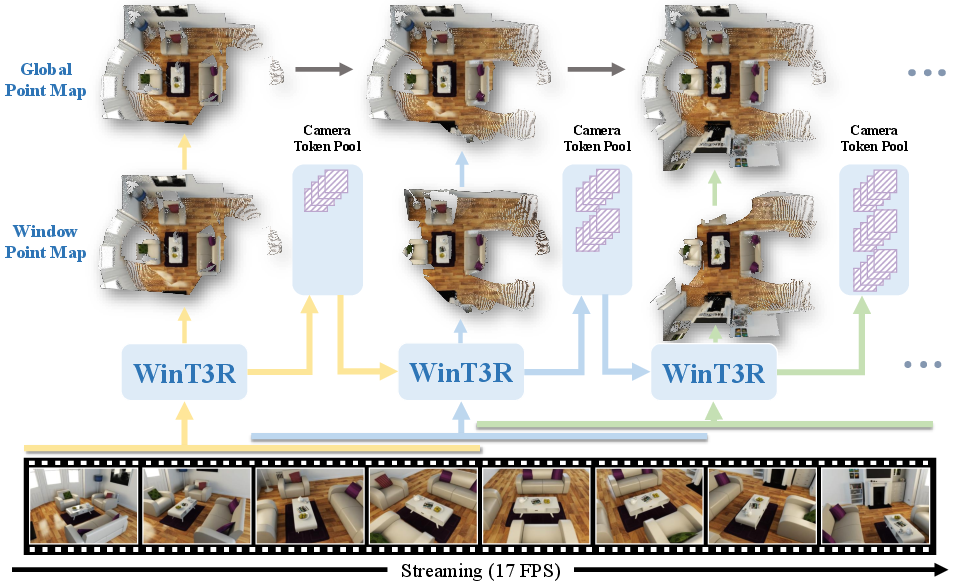
Figure 1: Overview of WinT3R's sliding-window processing and global camera token pool for real-time, high-quality 3D reconstruction.
Methodology
Sliding-Window Token Interaction
WinT3R processes input image streams using a sliding window of fixed size (default w=4), with a stride of w/2 to ensure overlap between adjacent windows. Each window aggregates image tokens from the constituent frames, which are encoded via a frame-wise ViT encoder. These tokens are augmented with learnable camera tokens and passed to a transformer-based decoder that facilitates both intra-window and inter-window information exchange. The overlapping window design ensures that predictions for shared frames are refined as new frames arrive, improving temporal consistency and reconstruction quality.
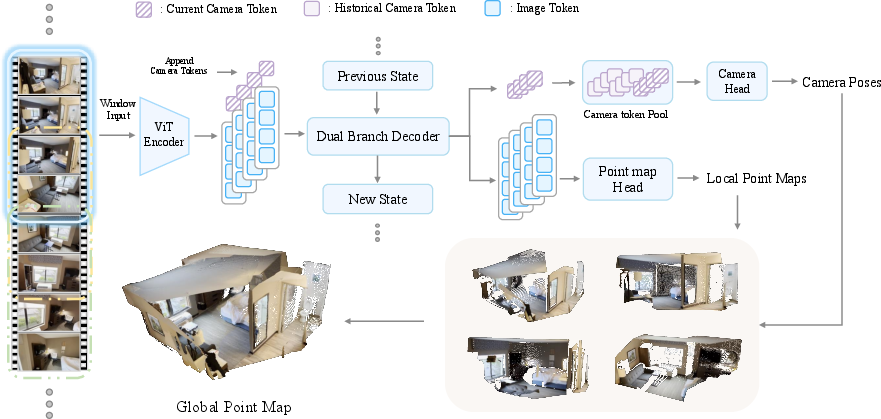
Figure 2: Detailed pipeline of WinT3R, showing token encoding, windowed decoding, and prediction heads for point maps and camera parameters.
The attention mechanism within the decoder is governed by a sliding-window attention mask, which restricts each token's receptive field to the current and historical windows, balancing computational efficiency with sufficient context aggregation.
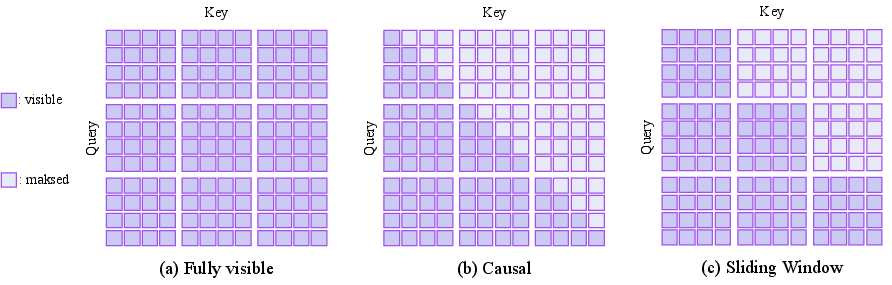
Figure 3: Comparison of attention masks: (a) full attention, (b) causal attention, (c) sliding window attention as used in WinT3R.
Camera Token Pool
A key innovation is the maintenance of a global camera token pool, where each frame's camera token is stored and made available for subsequent pose estimation. This pool acts as a lightweight global memory, enabling the camera head to condition pose predictions on all historical frames without incurring the prohibitive memory and compute costs of storing full image tokens or attention states. The camera head employs a masked attention mechanism aligned with the sliding window, ensuring that pose estimation for new frames can leverage the accumulated global context efficiently.
Prediction Heads and Training
- Point Map Head: A lightweight convolutional head predicts local point maps for each frame, operating on enriched image tokens. This design avoids the artifacts and inefficiencies of previous DPT or linear heads.
- Camera Head: The camera head predicts 7-DoF camera poses (quaternion + translation) using concatenated local and global camera tokens, conditioned on the camera token pool.
The model is trained end-to-end with a composite loss: a confidence-weighted regression loss for point maps and a relative pose loss (supervising pairwise relative poses rather than absolute poses) for camera parameters. Both losses are normalized to account for scale ambiguities and are equally weighted.
Experimental Results
3D Reconstruction
WinT3R demonstrates state-of-the-art performance on both object-centric (DTU) and scene-level (ETH3D, 7-Scenes, NRGBD) benchmarks. The method consistently outperforms prior online methods such as CUT3R, Point3R, and StreamVGGT in terms of accuracy, completeness, and overall Chamfer distance, while maintaining real-time throughput (17 FPS on a single NVIDIA A800 GPU).
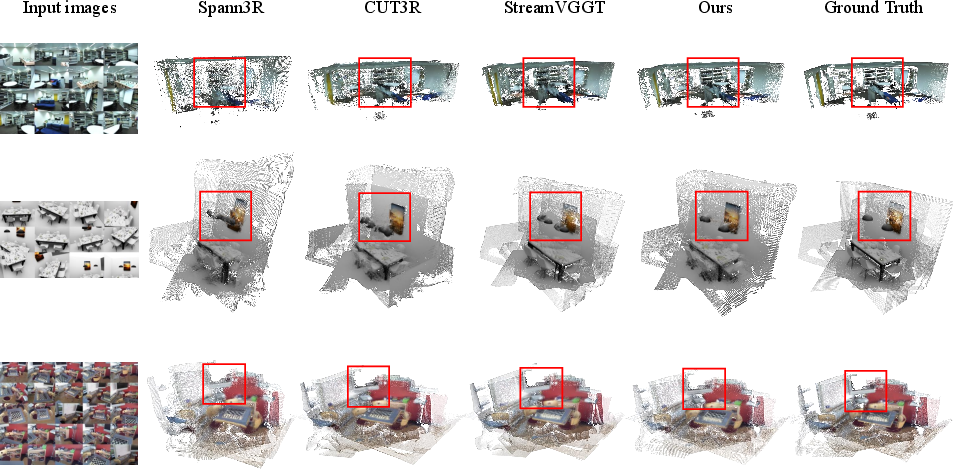
Figure 4: Qualitative comparison of 3D reconstruction accuracy and speed across online methods.

Figure 5: In-the-wild multi-view 3D reconstruction results, showing photorealistic outputs across diverse scenes.
Camera Pose Estimation
On camera pose benchmarks (Tanks and Temples, CO3Dv2, 7-Scenes), WinT3R achieves the highest or near-highest scores in Relative Rotation Accuracy (RRA), Relative Translation Accuracy (RTA), and AUC@30 among online methods. The use of the camera token pool yields a significant improvement in pose estimation accuracy, as confirmed by ablation studies.
Video Depth Estimation
WinT3R attains competitive or superior results on video depth estimation tasks (Sintel, BONN, KITTI), with lower Absolute Relative Error and higher δ<1.25 accuracy compared to other online approaches, while also achieving the highest inference speed.
Ablation Studies
Ablations confirm the critical role of each architectural component:
- Removing the camera token pool degrades pose accuracy substantially.
- Disabling the sliding window or window overlap reduces both reconstruction and pose estimation quality.
- The full model, with all components enabled, achieves the best trade-off between accuracy and efficiency.
Implementation and Resource Considerations
- Model Size: 750M parameters.
- Training: Two-stage training on large-scale multi-view datasets, leveraging DUSt3R pretraining. Full training requires significant compute (64 A800 GPUs for 7 days, then 32 A800 GPUs for 4 days).
- Inference: Real-time performance (17 FPS) is achieved via the compact token design and efficient attention masking.
- Scalability: The camera token pool and sliding window mechanism allow the model to scale to long sequences without quadratic memory growth.
Implications and Future Directions
WinT3R's architectural innovations—particularly the sliding-window token interaction and global camera token pool—demonstrate that high-quality, real-time 3D reconstruction and camera pose estimation are achievable in a feed-forward, streaming setting. The approach is well-suited for robotics, AR/VR, and autonomous systems where low-latency, incremental scene understanding is critical. The compactness of the camera token representation suggests further opportunities for efficient global memory mechanisms in other sequential vision tasks.
Potential future directions include:
- Extending the approach to handle dynamic scenes and non-rigid objects.
- Integrating semantic understanding or object-level reasoning into the reconstruction pipeline.
- Exploring adaptive window sizes or attention masks for variable scene complexity.
- Investigating the use of WinT3R as a foundation for world models in embodied AI agents.
Conclusion
WinT3R establishes a new standard for online 3D reconstruction by combining a sliding-window token interaction mechanism with a global camera token pool. The method achieves state-of-the-art accuracy and efficiency across multiple benchmarks, validating the effectiveness of its architectural choices. The design principles underlying WinT3R—efficient context aggregation, compact global memory, and real-time operation—are likely to inform future research in streaming visual geometry and beyond.

