- The paper introduces SI-LLM, a novel framework that infers semantically-rich type hierarchies, attributes, and relationships from minimally curated tabular data.
- It employs prompt engineering with LLMs to merge table-specific hierarchies into a coherent global DAG, achieving up to 0.99 Purity and 0.84 Rand Index.
- The framework demonstrates superior relationship discovery with an F1 score up to 0.81, enabling robust schema inference without external ontologies.
Schema Inference for Tabular Data Repositories Using LLMs
Introduction and Motivation
The proliferation of minimally curated tabular data in data lakes and open repositories has introduced significant challenges for schema inference, particularly due to representational heterogeneity and sparse metadata. Traditional approaches—relying on curated ontologies, extensive training data, or instance-level similarity—are often inadequate for integrating and summarizing such heterogeneous tabular collections. The paper introduces SI-LLM, a prompt-based framework leveraging LLMs to infer conceptual schemas directly from column headers and cell values, without requiring domain ontologies or labeled data. The inferred schema comprises a type hierarchy, conceptual attributes, and inter-type relationships, providing a semantically coherent abstraction over the underlying data.
SI-LLM Framework Overview
SI-LLM operates in three main stages: (1) type hierarchy inference, (2) attribute inference, and (3) relationship discovery. The process is designed to be end-to-end, modular, and robust to the inconsistencies and sparsity typical of web and open data tables.
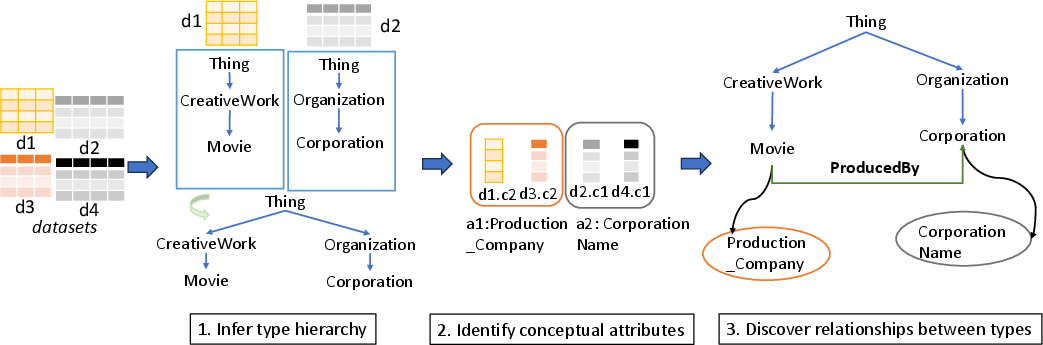
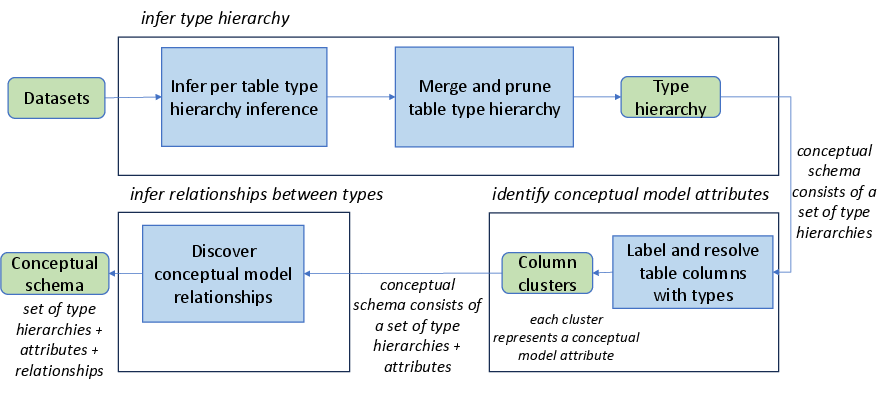
Figure 1: Schema inference steps and their example results, illustrating the SI-LLM pipeline from raw tables to a conceptual schema.
Type Hierarchy Inference
The first stage constructs a global type hierarchy by inferring, for each table, a type path from a root (Thing) to the most specific type, using LLMs with few-shot prompting. Each table's hierarchy is merged into a global DAG, with post-processing to prune self-loops, inverse edges, and erroneous is-a relationships. The approach departs from prior incremental or instance-based methods by directly generating full type paths, exploiting the LLM's capacity for global reasoning and semantic abstraction.


Figure 2: Basic prompt for type hierarchy inference, showing the structure and context provided to the LLM.
Prompt engineering is critical: the authors systematically evaluate constraints such as abstract type blacklisting, second-layer convergence, and explicit most-specific type anchoring. These constraints are shown to improve both the structural consistency and semantic purity of the inferred hierarchies.
Attribute Inference
Given the type hierarchy, SI-LLM infers conceptual attributes for each type by abstracting over the columns of all tables assigned to that type. For each column, the LLM is prompted with the header and sampled cell values to generate a canonical attribute name. A subsequent LLM-based resolution step clusters semantically equivalent attribute names, assigning a representative to each group. Inherited attributes are promoted up the hierarchy if they appear in a sufficient fraction of child types, using a bottom-up traversal.



Figure 3: Attribute Name Inference Prompt, demonstrating the LLM input for canonicalizing column headers and values.
Relationship Discovery
SI-LLM discovers inter-type relationships by analyzing named-entity attributes whose values predominantly refer to instances of another type. For each such attribute, the LLM is prompted to identify the most specific target type and to generate a predicate label for the relationship. This approach enables the recovery of semantic links (e.g., Movie producedBy Company) even in the absence of explicit foreign keys or join metadata.
Empirical Evaluation
The framework is evaluated on two annotated benchmarks: WDC (web tables) and GDS (Google Dataset Search). Metrics include Rand Index (RI), Purity, Path Tree Consistency Score (PTCS), and standard precision/recall/F1 for relationship discovery. SI-LLM is compared against state-of-the-art baselines, including both LLM-based (GeTT) and embedding-based (SBERT, DeepJoin, SwAV, Unicorn) methods.
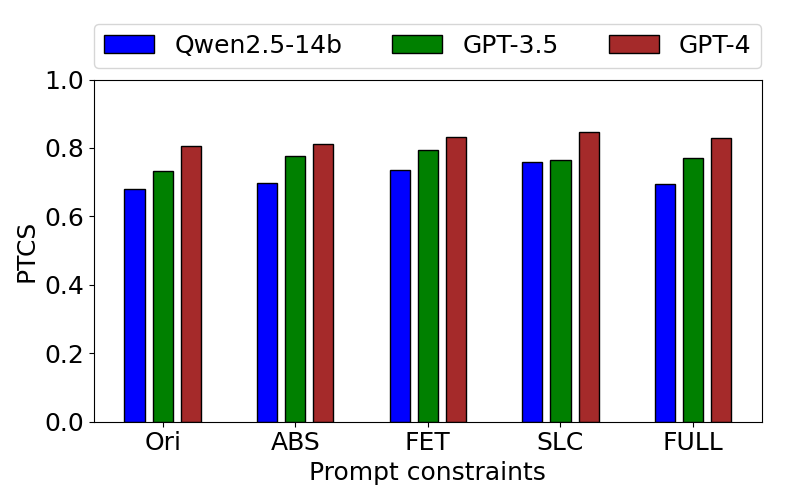
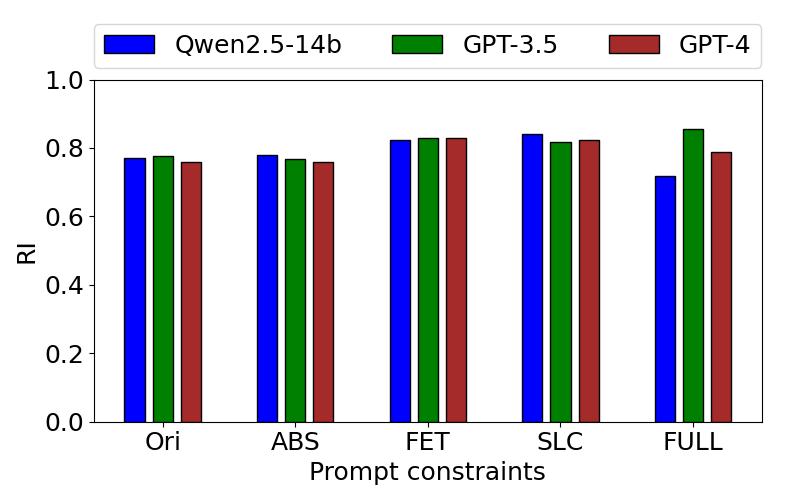
Figure 4: (Left) PTCS of the hierarchies inferred using different prompt constraints on WDC. (Right) RI of the top-level types inferred using different prompt constraints on WDC.
Key results:
- Type hierarchy inference: SI-LLM achieves Purity up to 0.99 and RI up to 0.84, outperforming GeTT and most embedding-based baselines. The approach yields richer, more fine-grained hierarchies, with up to 389 types on WDC.
- Attribute inference: SI-LLM attains RI above 0.90 and Purity up to 0.74, matching or exceeding strong PLM-based clustering baselines. Error analysis reveals that LLMs occasionally over-generalize or semantically mix attributes, especially in long-tail distributions.
- Relationship discovery: SI-LLM achieves F1 up to 0.81, with significantly higher recall than embedding-based methods, which tend to miss conceptual relationships not evident at the instance level.
Case Study: End-to-End Schema Induction
The paper presents an end-to-end application of SI-LLM on the GDS benchmark, visualizing the inferred schema.
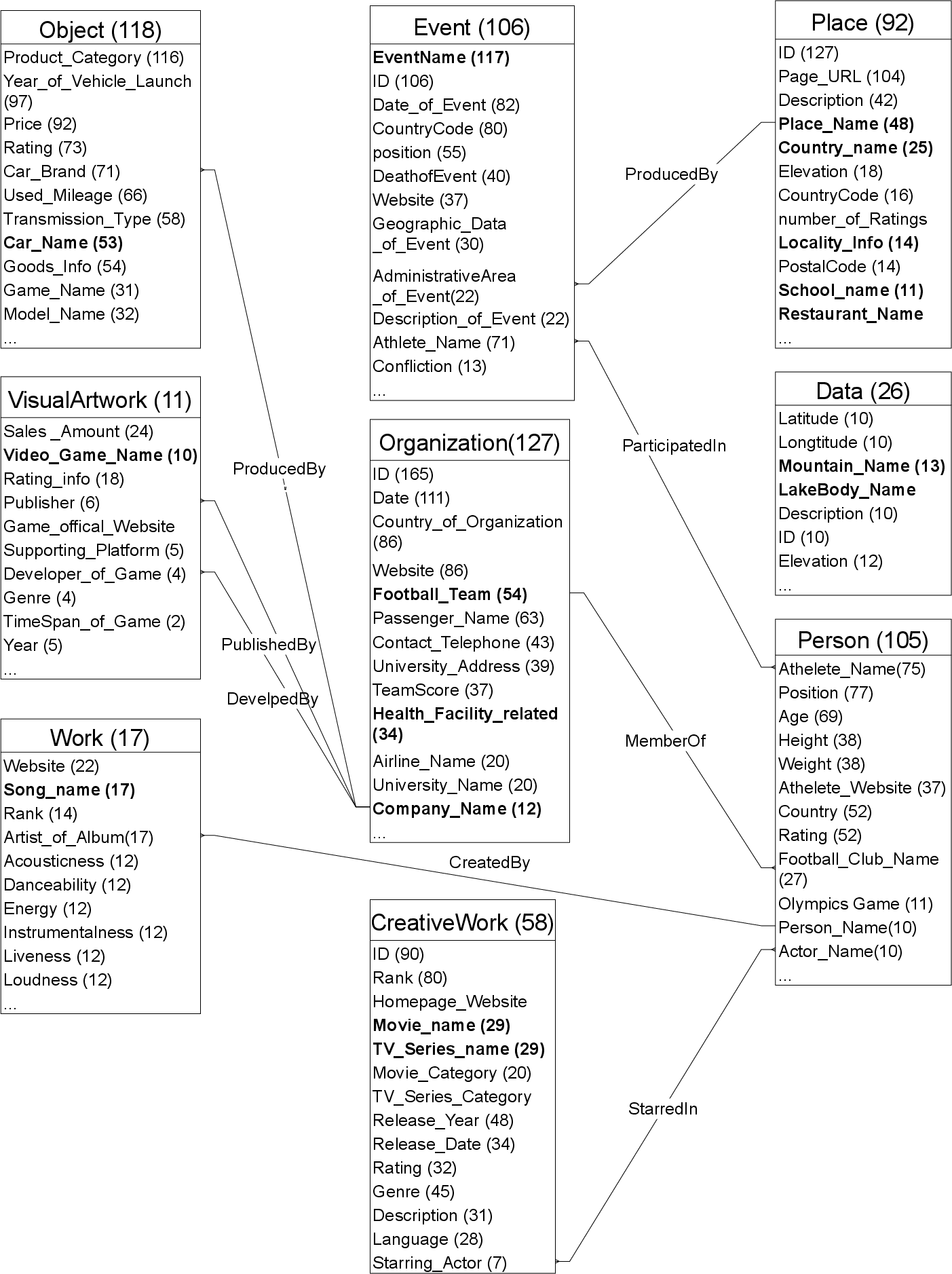
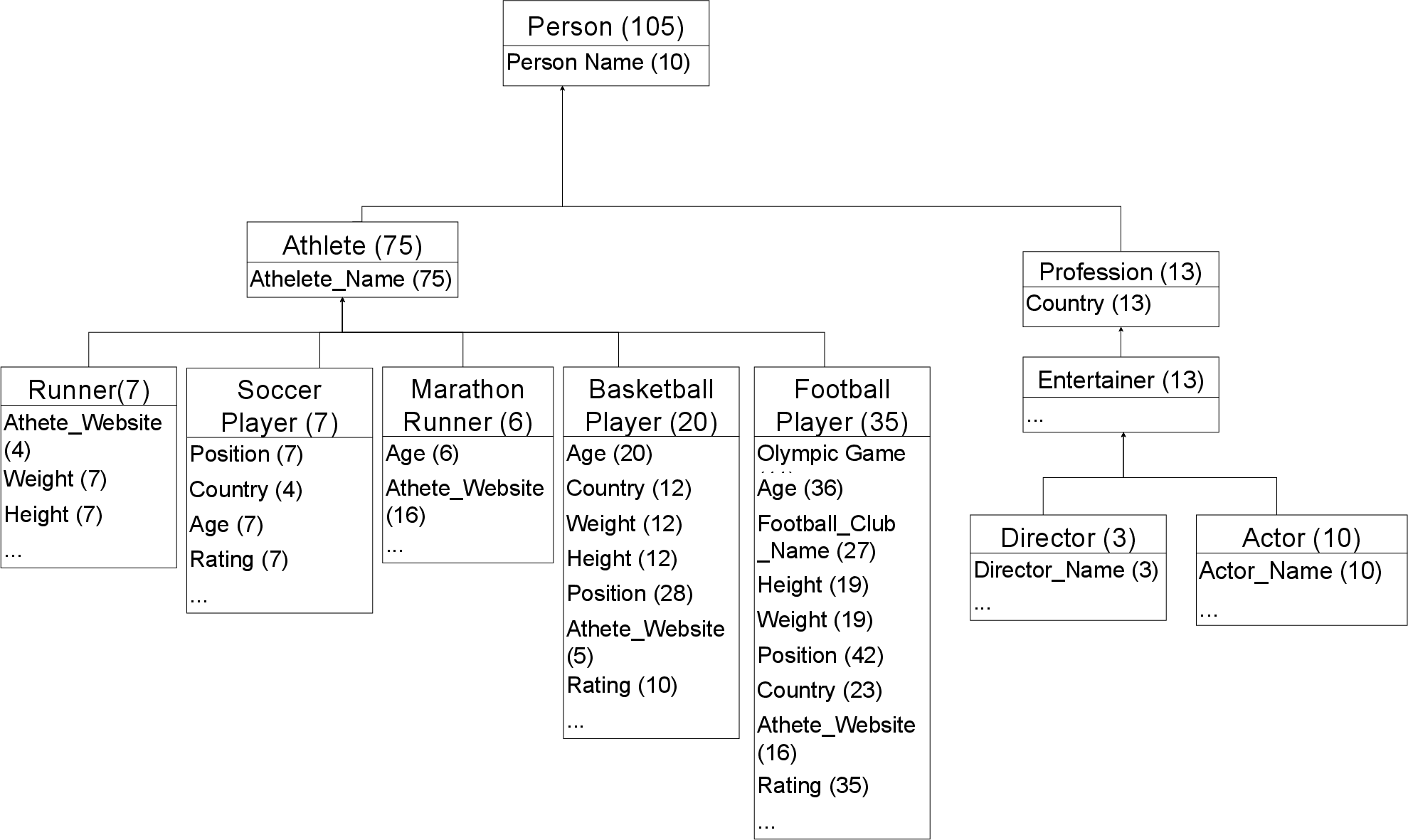
Figure 5: Top-level types, their attributes, and relationships as inferred by SI-LLM on GDS.
The schema recovers 87% of annotated types, with 5 out of 6 ground-truth top-level types present. Relationships are correctly inferred, and the sub-hierarchies (e.g., under Person and Object) demonstrate coherent propagation of attributes and plausible type groupings, despite some naming imperfections and occasional over-generalization.
Analysis of Prompt Constraints
Prompt constraints play a pivotal role in the stability and quality of the inferred hierarchies. The FET and FULL constraints yield substantial improvements in top-level type inference, while SLC and ABS constraints enhance tree consistency. The ablation study demonstrates that prompt design is a critical lever for controlling LLM behavior in schema induction tasks.
Discussion and Implications
The SI-LLM framework demonstrates that LLMs, when guided by carefully engineered prompts and minimal metadata, can robustly infer semantically meaningful schemas from heterogeneous tabular data. The approach is agnostic to domain ontologies and does not require labeled data, making it applicable to a wide range of data lake and open data scenarios.
Notable claims and findings:
- SI-LLM achieves +7–10% RI and ~97% Purity for type/hierarchy inference, and +30–40% recall/F1 in relationship discovery over strong baselines.
- The method produces more fine-grained and semantically coherent hierarchies than embedding-based approaches, though sometimes at the expense of strict alignment with ground-truth taxonomies.
- LLM-based attribute and relationship inference is robust to representational heterogeneity, but can be sensitive to prompt design and context window limitations.
Future Directions
The paper identifies several open challenges:
- Improving type naming and reducing fallback to generic types, to better align with curated taxonomies.
- Enhancing attribute inference to more accurately capture both common and long-tail attributes, especially in large and complex datasets.
- Extending the approach to support incremental schema evolution and integration with downstream data discovery and exploration tools.
Conclusion
SI-LLM establishes a new paradigm for schema inference in heterogeneous tabular data repositories, leveraging LLMs for semantic abstraction without reliance on external ontologies or labeled data. The framework achieves strong empirical performance across multiple benchmarks and demonstrates the feasibility of prompt-based schema induction at scale. The results have significant implications for automated data integration, discovery, and exploration in open and minimally curated data environments. Further research on prompt optimization, schema evolution, and integration with knowledge graph construction is warranted to fully realize the potential of LLM-driven schema inference.

