- The paper introduces a training-free zero-shot framework for multi-frame story visualization and editing using text-to-image diffusion models.
- It employs a grid-based latent prior and latent blending to maintain visual consistency and perform disentangled, context-aware modifications.
- Quantitative evaluations and user studies confirm its superiority in narrative coherence and editing accuracy over state-of-the-art methods.
Plot'n Polish: Zero-shot Story Visualization and Disentangled Editing with Text-to-Image Diffusion Models
Introduction and Motivation
Plot'n Polish introduces a training-free, zero-shot framework for story visualization and multi-frame editing using text-to-image (T2I) diffusion models. The method addresses critical limitations in existing story visualization pipelines, notably the lack of post-generation editing flexibility and the inability to maintain visual and narrative consistency across multiple frames. Prior approaches either require extensive fine-tuning, generate frames independently (leading to inconsistencies), or lack mechanisms for coherent multi-frame modifications. Plot'n Polish is designed to enable both initial story generation and iterative, disentangled editing—supporting fine-grained and global changes—while ensuring consistency throughout the narrative sequence.
System Overview and Pipeline
The framework operates in two main stages: story visualization and multi-frame editing. Users can provide story plots and image prompts for each frame, or these can be generated by an LLM (e.g., GPT-4) based on a high-level story idea. The image prompts are used to create initial template images via an off-the-shelf T2I model such as SDXL. The editing framework then takes editing prompts (text or images), initial images, and extracted depth conditions to perform consistent, localized, or global edits across the story sequence.
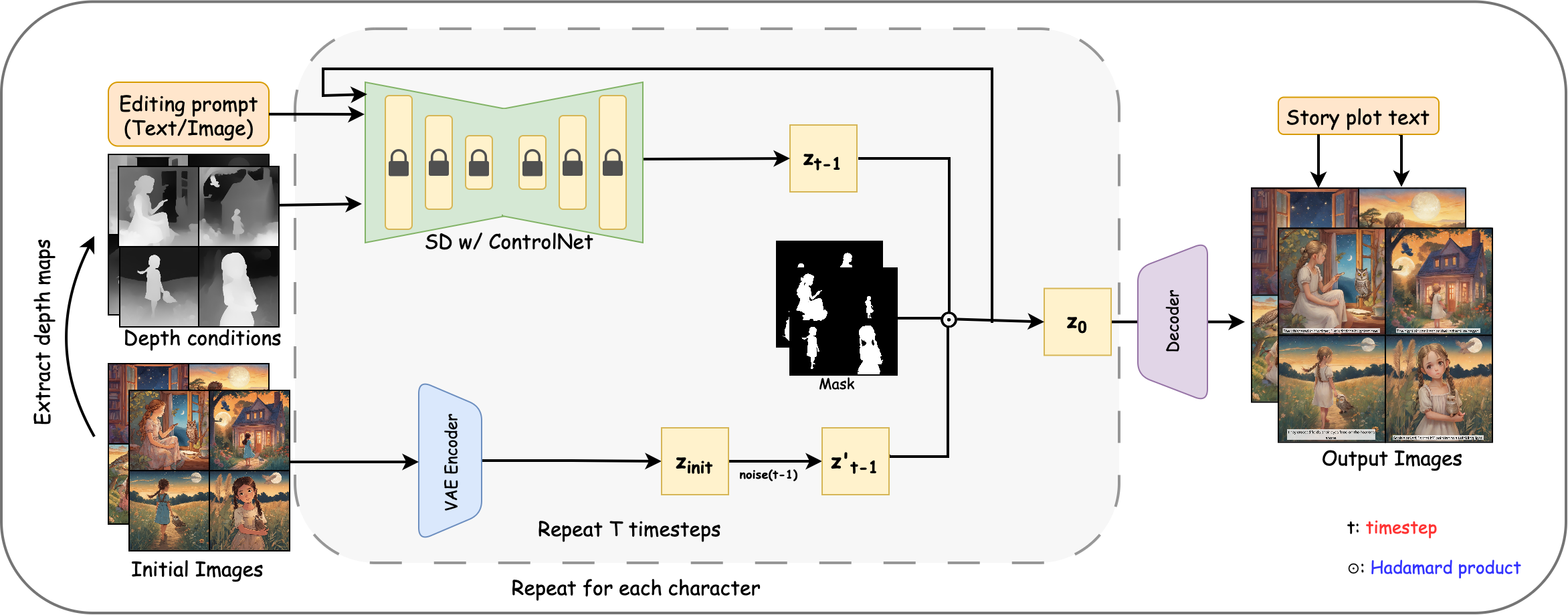
Figure 1: Overview of Plot'n Polish pipeline, illustrating user input, template generation, and multi-frame editing with depth conditions and prompts.
Multi-Frame Consistency and Editing Mechanism
The core innovation is a grid-based latent prior mechanism for multi-frame editing. Given n frames and a concept to modify (e.g., "boy"), object detection and semantic segmentation models extract masks for the target regions. Frames are grouped into grids, and latent representations, masks, and depth conditions are processed jointly. At each diffusion timestep, the latent grid is updated using the editing prompt and depth conditions, with random regrouping to enforce cross-frame consistency and reduce memory overhead.
Latent blending is applied after each denoising step to prevent modifications from affecting unmasked regions, ensuring that only the intended areas are edited while background details are preserved. For global edits (e.g., style changes), blending is omitted to allow modifications to propagate across the entire image. The final latent grid is decoded to produce the edited images.

Figure 2: Initial story template generated by SDXL (top row) and refined, consistent panels produced by Plot'n Polish (bottom row).
Personalization and Integration
Plot'n Polish supports personalization via LoRA models or single reference images, leveraging IP-Adapter cross-attention layers for image-based prompts. This enables seamless integration of custom characters, objects, or styles into the story visualization process.
Qualitative and Quantitative Evaluation
Extensive qualitative experiments demonstrate the method's ability to maintain character and object consistency, perform fine-grained edits (e.g., changing hair color, adding accessories), and support global stylistic transformations (e.g., "Van Gogh" style). The framework can edit both generated and user-provided story frames, including illustrations from published books, without retraining or fine-tuning.

Figure 3: Qualitative results showing consistent narratives, localized edits, character replacements, and personalization.
Comparative analysis with state-of-the-art methods (StoryDiffusion, ConsiStory, AutoStudio, Intelligent Grimm) reveals that Plot'n Polish consistently outperforms competitors in maintaining visual coherence, accurately depicting characters and attire, and avoiding blending errors or narrative breaks.

Figure 4: Comparison with prior story visualization methods, highlighting superior consistency and narrative coherence of Plot'n Polish.
For editing tasks, Plot'n Polish demonstrates disentangled, contextually appropriate modifications, outperforming methods such as InstructPix2Pix, LEDITS++, and Plug-and-Play in both accuracy and preservation of background details.

Figure 5: Editing comparison showing Plot'n Polish's ability to apply edits accurately while maintaining narrative coherence.

Figure 6: Comparison of editing methods, illustrating Plot'n Polish's disentangled edits and background preservation.
Quantitative metrics (CLIP-I, CLIP-T, DINO, LPIPS) and user studies confirm the method's superiority in image consistency, text alignment, and editing disentanglement. Plot'n Polish achieves the highest scores in user ratings for narrative alignment and consistency, as well as editing accuracy and disentanglement.
Ablation and Robustness
Ablation studies highlight the importance of grid size, grid priors, and latent blending. Larger grids improve frame-to-frame interaction and consistency; removing grid priors or latent blending leads to character inconsistencies and artifacts. The method is robust to alternative masking strategies, including attention-derived masks, and generalizes to high-resolution models (SDXL, Flux).

Figure 7: Ablation results showing the impact of grid size, grid priors, and latent blending on consistency and artifact reduction.
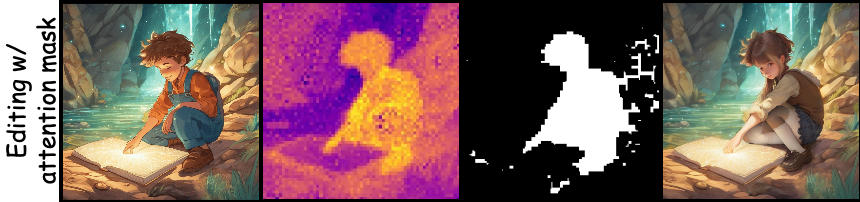
Figure 8: Example of image editing using attention-derived mask.
Limitations
The framework's reliance on segmentation models for mask extraction means that edit quality is contingent on segmentation accuracy. Overlapping objects may result in unintended edits, as illustrated in failure cases.

Figure 9: Failure case due to overlapping mask detection, resulting in unintended subject edits.
Implications and Future Directions
Plot'n Polish advances the state-of-the-art in story visualization by enabling zero-shot, training-free, multi-frame editing with disentangled control. The method's flexibility and efficiency make it suitable for creative workflows, educational content, and personalized storytelling. The integration of LLMs for prompt generation and iterative refinement further enhances user control and narrative alignment.
Theoretically, the grid-based latent prior and blending strategies provide a foundation for future research in multi-frame and video editing, compositional generation, and interactive narrative systems. Future work may explore interactive branching narratives, more sophisticated mask extraction, and integration with multimodal generative models for richer story dynamics.
Conclusion
Plot'n Polish presents a comprehensive framework for zero-shot story visualization and disentangled multi-frame editing using T2I diffusion models. By combining grid-based latent priors, latent blending, and flexible personalization, the method achieves consistent, coherent, and customizable story sequences. Extensive qualitative and quantitative results substantiate its superiority over existing approaches, and its design opens avenues for further research in interactive and compositional generative modeling.